目录
初学阶段,可以认为numpy的某些方法也可以运用到pandas模块中,例如np.where()三元运算、unique去重方法、shape方法
1 pandas介绍
1.1 Pandas介绍
面板 数据 (三维数据)分析 计量经济学(数据分析80% 跑计量20%)
- 以Numpy为基础,借力Numpy模块在计算方面性能高的优势
- 基于matplotlib,能够简便的画图
- 独特的数据结构
1.2 为什么使用Pandas
- 便捷的数据处理能力

- 读取文件方便
- 封装了Matplotlib、Numpy的画图和计算
1.3 案例:在numpy当中创建的股票涨跌幅数据形式
import numpy as np
import pandas as pd
# 创建一个符合正态分布的10个股票5天的涨跌幅数据
st_change = np.random.normal(0,1,(10,5))
st_change
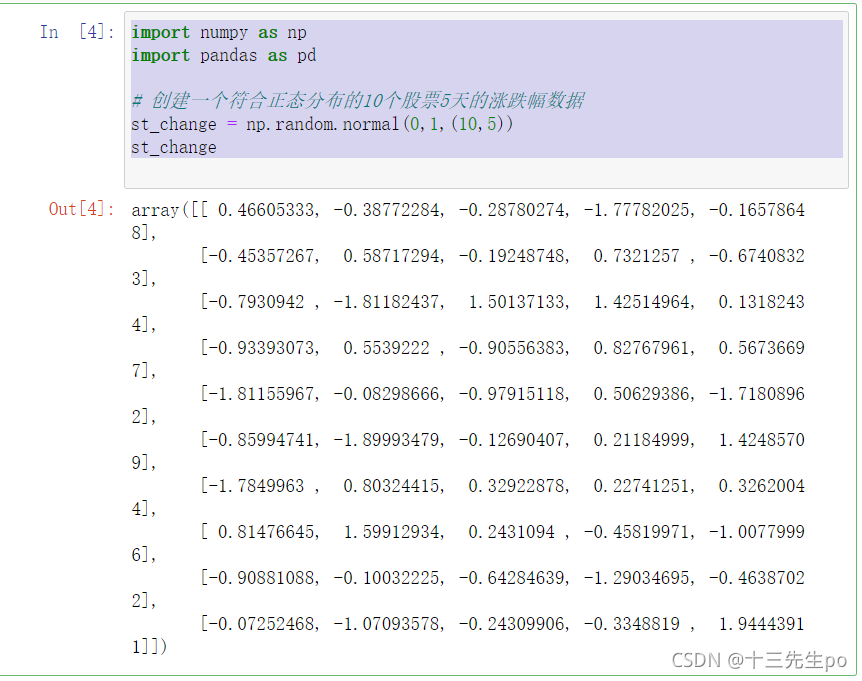
这样的数据形式很难看到存储的是什么样的数据,并且也很难获取相应的数据,比如需要获取某个指定股票的数据,就很难去获取!!
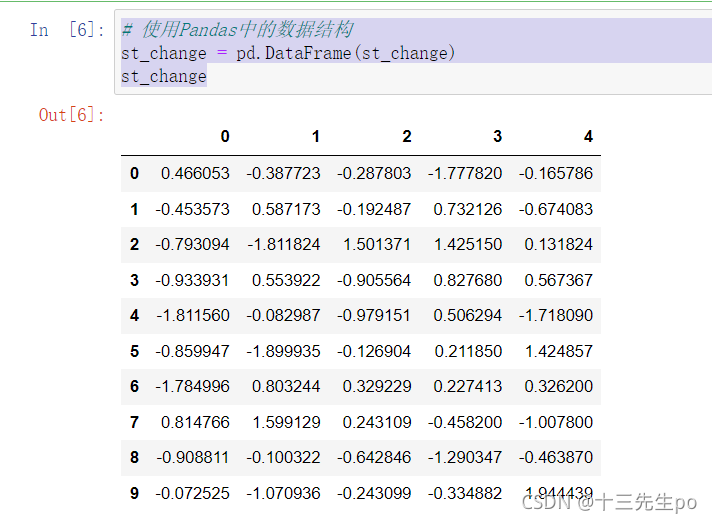
- 让数据更有意义的显示
给股票涨跌幅数据增加行列索引,显示效果更佳
# 使用Pandas中的数据结构
st_change = pd.DataFrame(st_change)
st_change
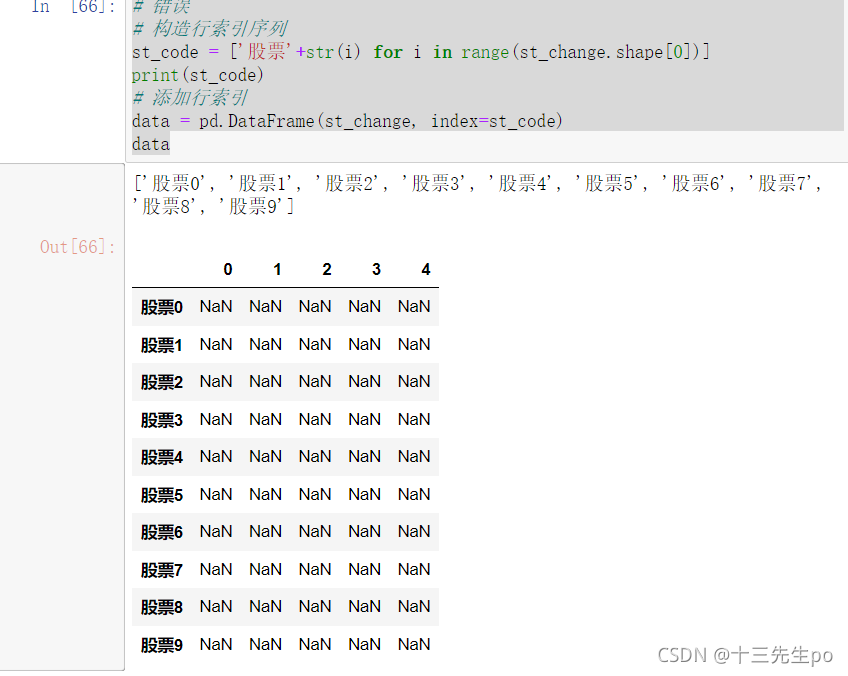
- 增加行索引
错误写法:以下书写的代码可能会出现全Nan值
# 错误
# 构造行索引序列
st_code = ['股票'+str(i) for i in range(st_change.shape[0])]
print(st_code)
# 添加行索引
data = pd.DataFrame(st_change, index=st_code)
data
正确写法:
方法1:对dataframe结构的行索引index直接更改,有可能出问题,取决于赋什么值。以前这样做可以,现在不太推荐了
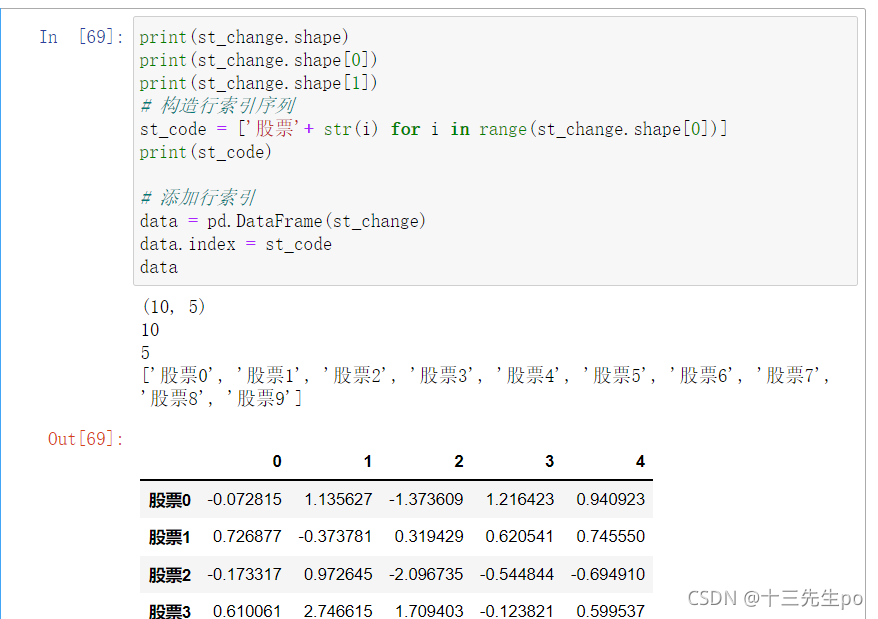
print(st_change.shape)
print(st_change.shape[0])
print(st_change.shape[1])
# 构造行索引序列
st_code = ['股票'+ str(i) for i in range(st_change.shape[0])]
print(st_code)
# 添加行索引
data = pd.DataFrame(st_change)
data.index = st_code
data
方法2:用rename方法改
df.rename(index={原行索引名:替换行索引名})
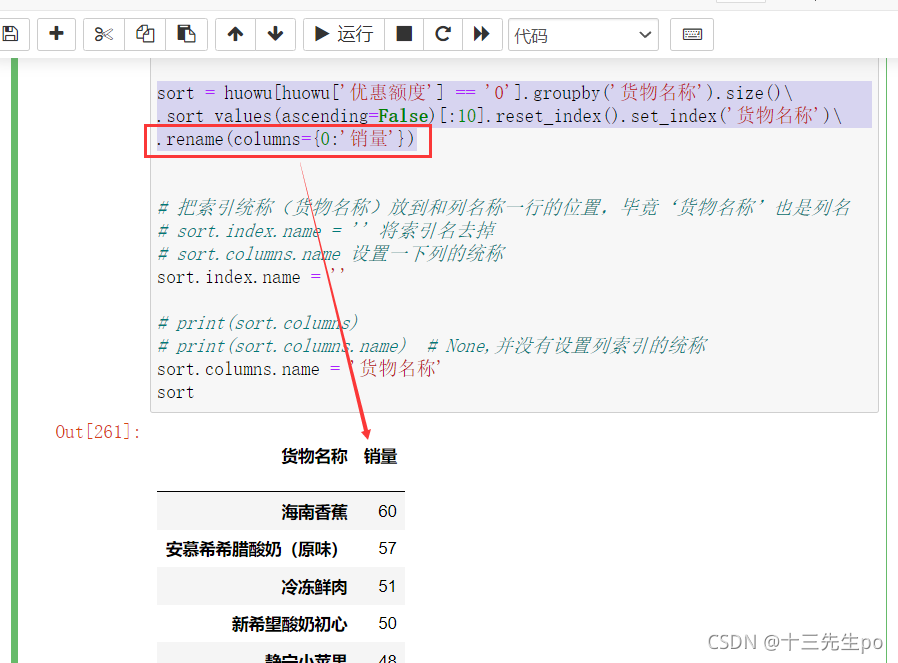
sort = huowu[huowu['优惠额度'] == '0'].groupby('货物名称').size()\
.sort_values(ascending=False)[:10].reset_index().set_index('货物名称')\
.rename(columns={0:'销量'})
- 增加列索引
股票的日期是一个时间的序列,我们要实现从前往后的时间还要考虑每月的总天数等,不方便。使用pd.date_range():用于生成一组连续的时间序列(暂时了解)
date_range(start=None,end=None, periods=None, freq='B')
start:开始时间
end:结束时间
periods:时间天数
freq:递进单位,默认1天,'B'默认略过周末
# 生成一个时间的序列,略过周末非交易日
以下是错误代码,和上面可能出现错误的写法一样,全体nan值
# 生成一个时间的序列,略过周末非交易日
date = pd.date_range('2017-01-01', periods=stock_change.shape[1], freq='B')
# index代表行索引,columns代表列索引
data = pd.DataFrame(stock_change, index=stock_index, columns=date)
正确代码
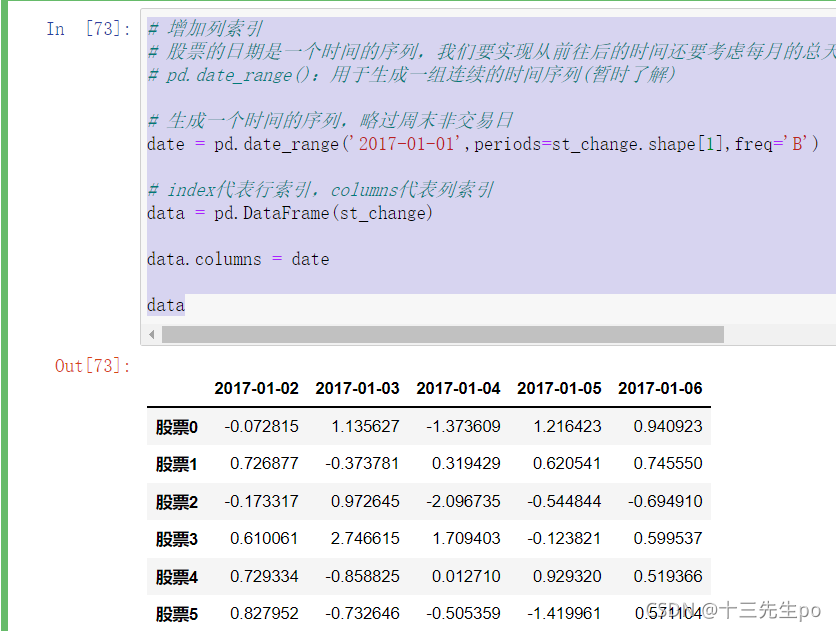
# 增加列索引
# 股票的日期是一个时间的序列,我们要实现从前往后的时间还要考虑每月的总天数等,不方便。使用
# pd.date_range():用于生成一组连续的时间序列(暂时了解)
# 生成一个时间的序列,略过周末非交易日
date = pd.date_range('2017-01-01',periods=st_change.shape[1],freq='B')
# index代表行索引,columns代表列索引
data = pd.DataFrame(st_change)
data.columns = date
data
1.4 DataFrame
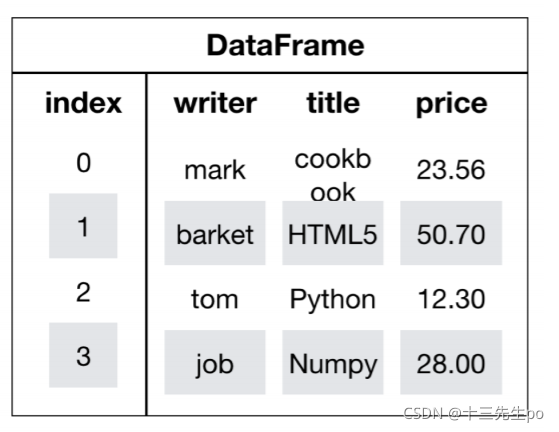
1.4.1 DataFrame结构
DataFrame对象既有行索引,又有列索引
- 行索引,表明不同行,横向索引,叫index
- 列索引,表名不同列,纵向索引,叫columns
1.4.2 DatatFrame的常用属性和方法
常用属性:
- index.name/index.columns.name
常用检查索引和列是否有统称的名字
huowu.head()
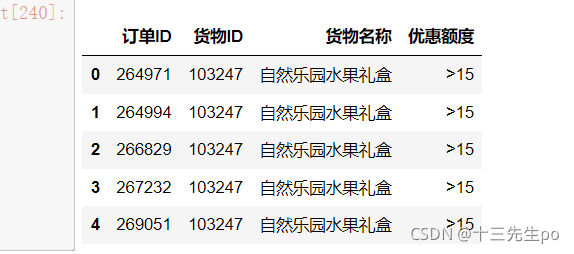
# 指标创建:不同优惠额度的订单数量
huowu.head()
huowu.index.name # None
huowu.columns.name # None
没有输出值,说明没有
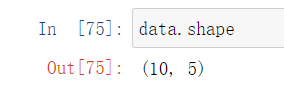
- shape
numpy的array结构和pandas的dataframe结构一样都可以调用查看shape属性
data.shape
- index
获得DataFrame的行索引列表
data.index

- columns
DataFrame的列索引列表
data.columns

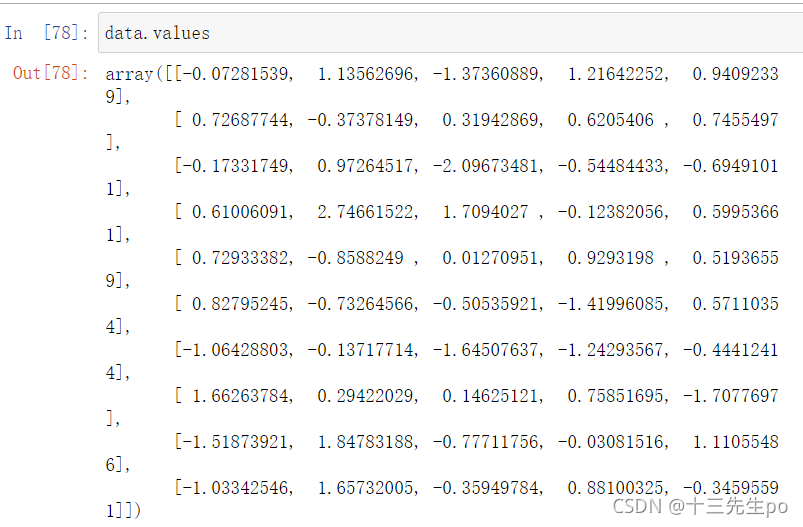
- values
直接获取其中array的值
data.values
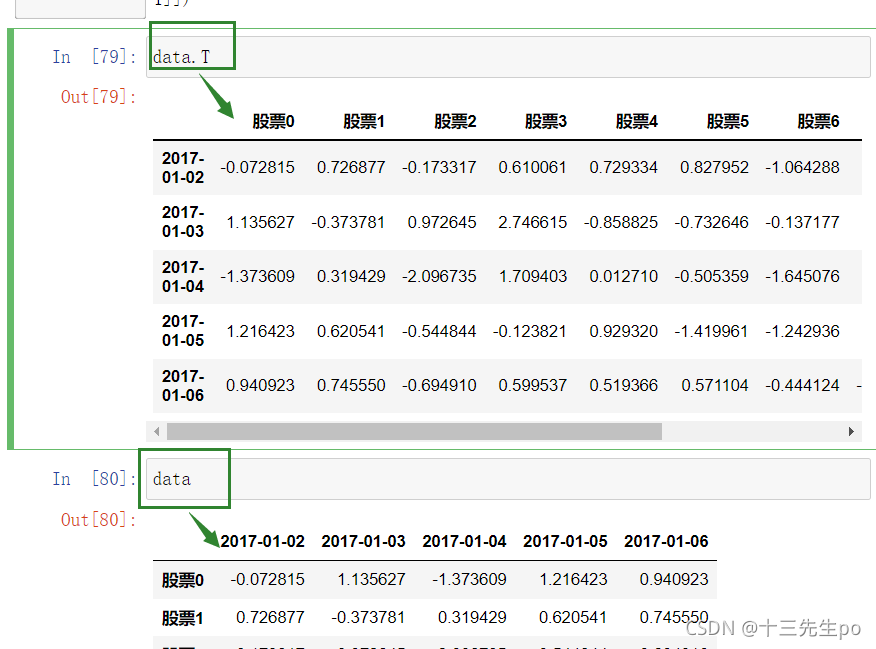
- T
转置
转置之后实际数据并没有转置
data.T
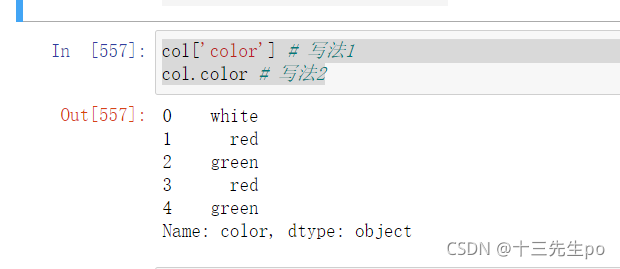
- pd.列名 或者 pd.[列名] 显示列数据
col['color'] # 写法1
col.color # 写法2
- [:,0] # 提取第0列的所有数值,提取列数值
原数据
X_new
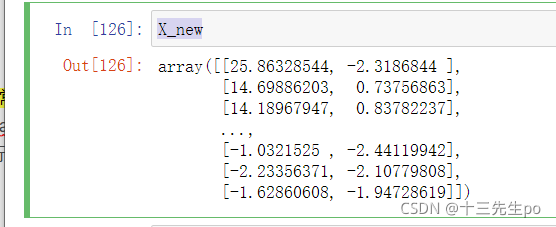
X_new[:,0]

常用方法:
- reindex(columns=[]) # 自定义排序
原本的数据
# 按列重新排序
data3 = data3.reindex(columns=['L','R','F','M','C'])
data3.head()
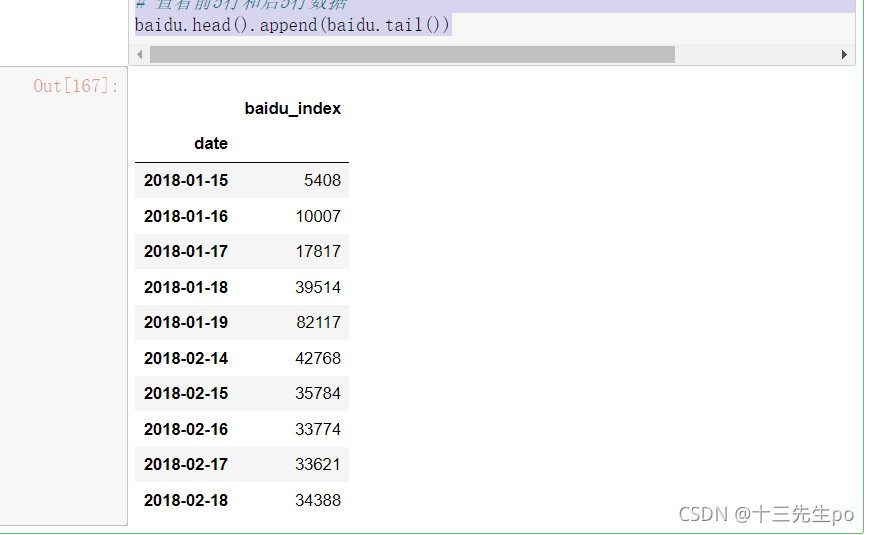
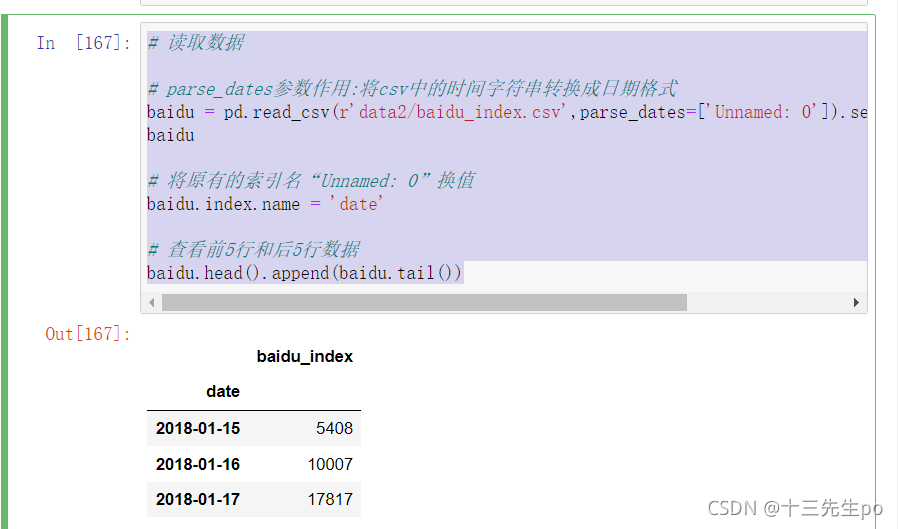
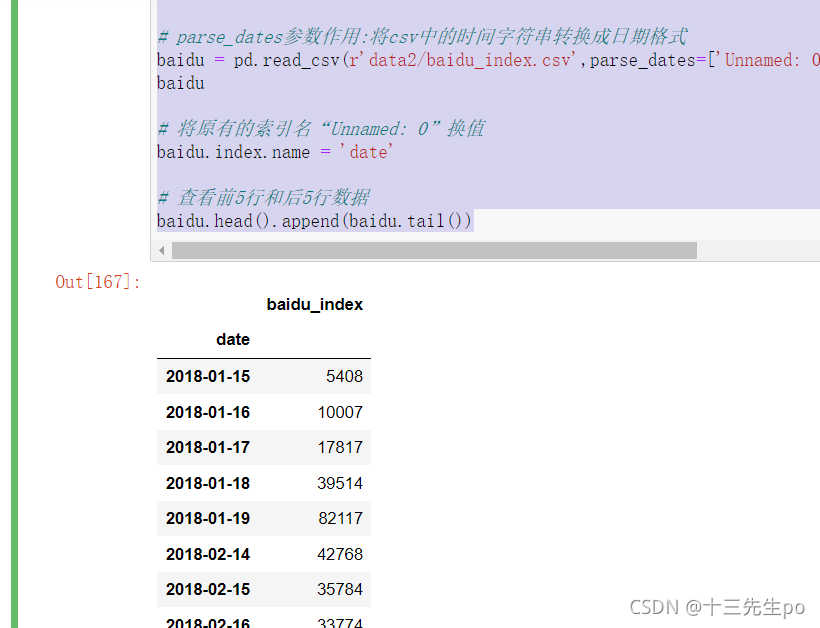
- baidu.head().append(baidu.tail()) # 查看前5行和后5行数据
# 读取数据
# parse_dates参数作用:将csv中的时间字符串转换成日期格式
baidu = pd.read_csv(r'data2/baidu_index.csv',parse_dates=['Unnamed: 0']).set_index('Unnamed: 0')
baidu
# 将原有的索引名“Unnamed: 0”换值
baidu.index.name = 'date'
# 查看前5行和后5行数据
baidu.head().append(baidu.tail())
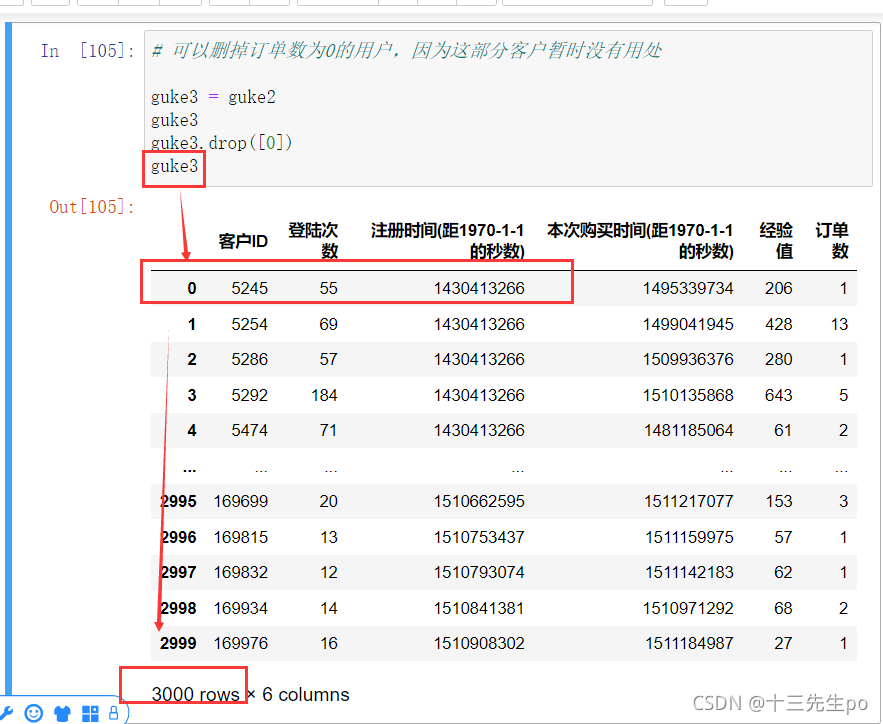
- drop([行坐标,行坐标]) # 删除行或者列
- 删除指定行
drop方法只对本行操作的数据有效,并不会对目标造成实际操作
原数据
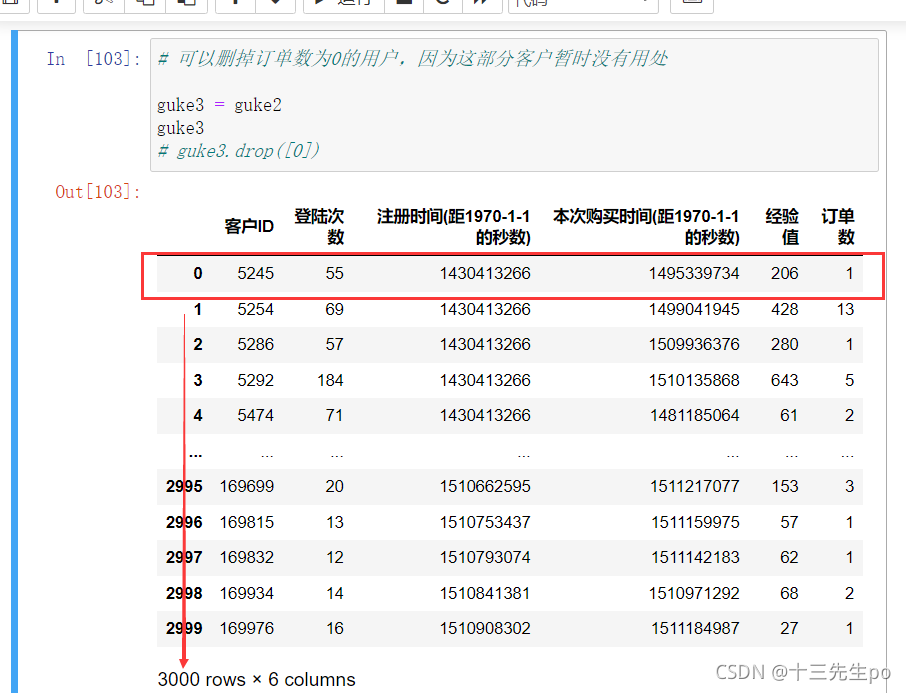
# 可以删掉订单数为0的用户,因为这部分客户暂时没有用处
guke3 = guke2
guke3.drop([0])
修改成功
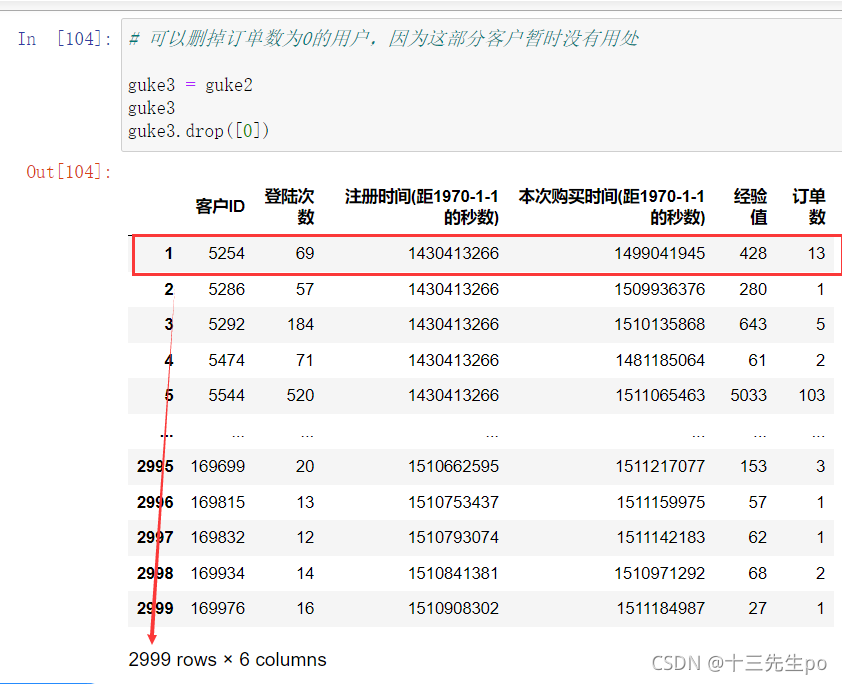
但重新打印出guke3,可以发现并没有真正的删除
# 可以删掉订单数为0的用户,因为这部分客户暂时没有用处
guke3 = guke2
guke3
guke3.drop([0])
guke3
- drop(['列名’],axis=1) # 删除列
参考网址pandas删除某一列的方法
原本数据
删除列
guke2.drop('客户类别',axis=1)
** 注意删除不改表原始数据**
删除后重新删除还是原来的数值,可以将删除行代码传给新的实参进行保留
- info()
查看各列数据的数据类型
st1.info()
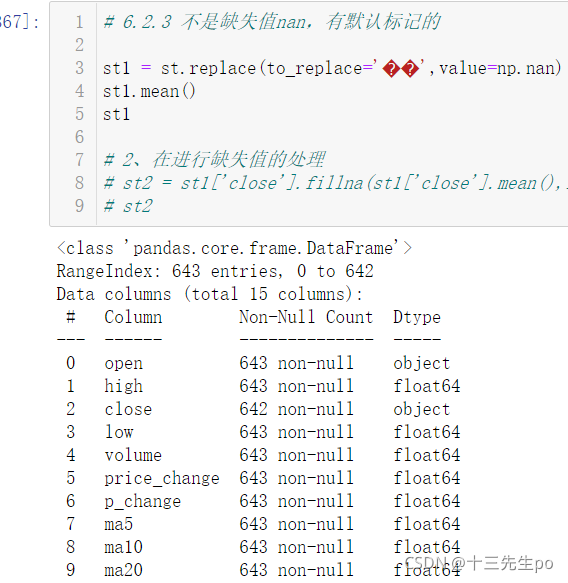
- astype(np.float)
列数据类型转换- 由于错误值的存在,已经将整列的数据类型变成了object字符串类型,不能使用fillna()方法来替换
但是要给原数据增加个新列,把修改后的列赋值过去,删除旧列,或者直接用新列覆盖旧列,然后才能用fillna方法进行替换,如以下代码
st1['close'] = st1['close'].astype(np.float)
st1['close'].fillna(st1['close'].mean(),inplace=True)
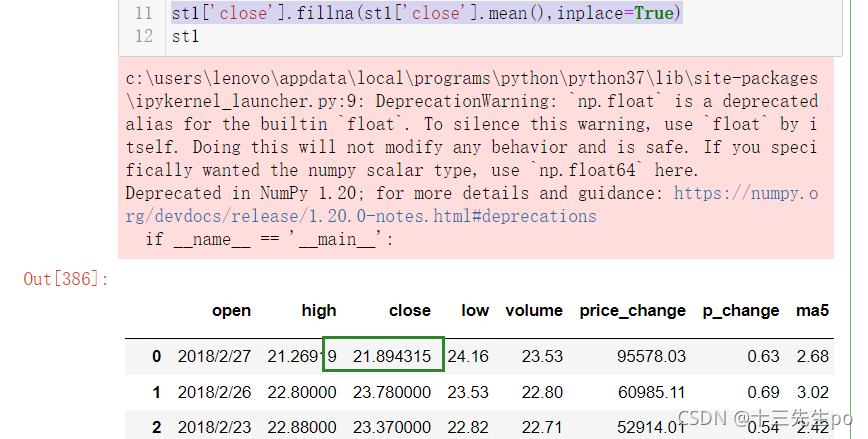
值改了过来
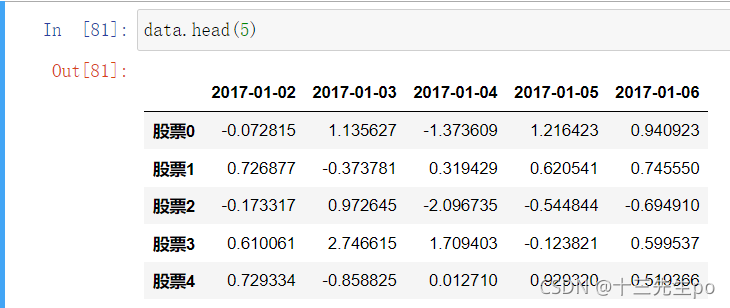
- head(5):显示前5行内容
如果不补充参数,默认5行。填入参数N则显示前N行
data.head(5)
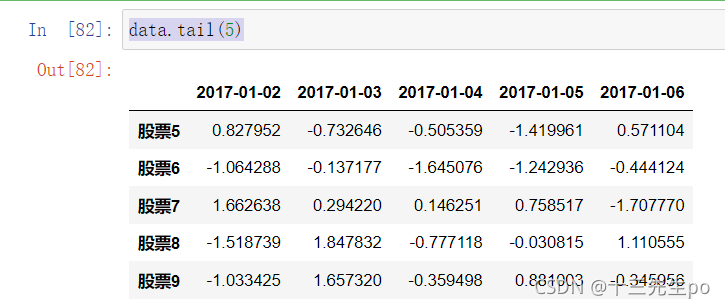
- tail(5):显示后5行内容
如果不补充参数,默认5行。填入参数N则显示后N行
data.tail(5)
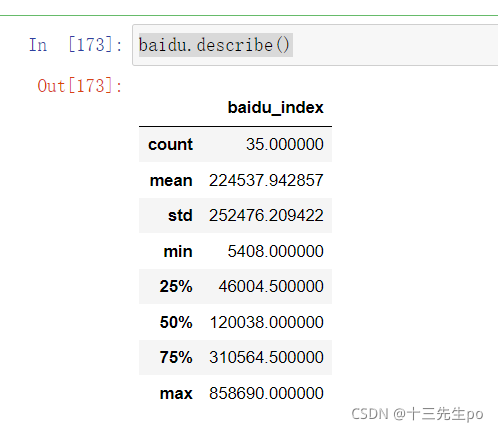
- describe() # 查看统计类数据整合
baidu.describe()
- rename() #修改行索引/列索引名称
- 列修改
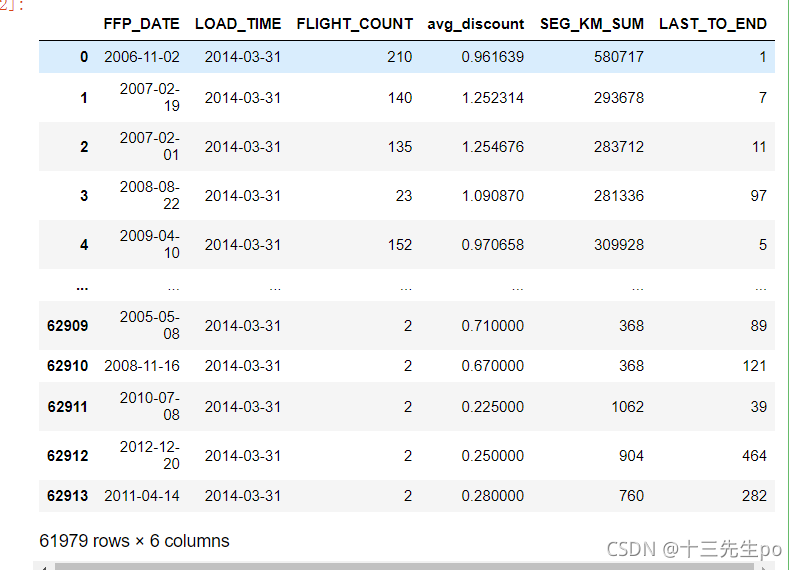
# 其他指标改列索引
data3 = data2.rename(columns={
'FLIGHT_COUNT': 'F', 'avg_discount': 'C', 'SEG_KM_SUM': 'M', 'LAST_TO_END': 'R'}).drop(['FFP_DATE', 'LOAD_TIME'], axis=1)
data3
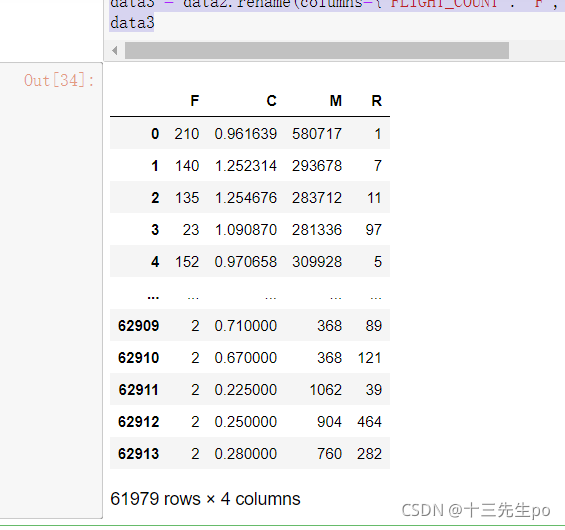
- 行修改
data5 = np.random.normal(0,1,(10,5))
data5 = pd.DataFrame(data5)
data5.rename(index={
0:1,2:22})
- reset_index() # 重置索引,还能将Series结构变成dataframe结构
pc3.reset_index()
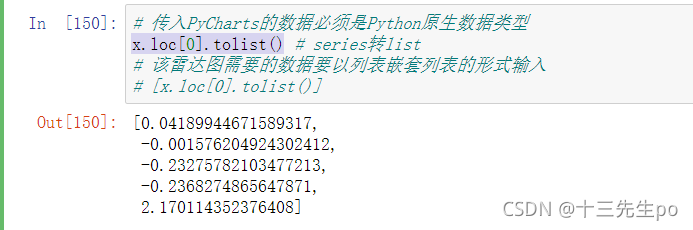
- to_list() # pd结构数据变列表数据
x.loc[0].tolist()
1.4.3 DatatFrame索引的设置
修改行列索引值
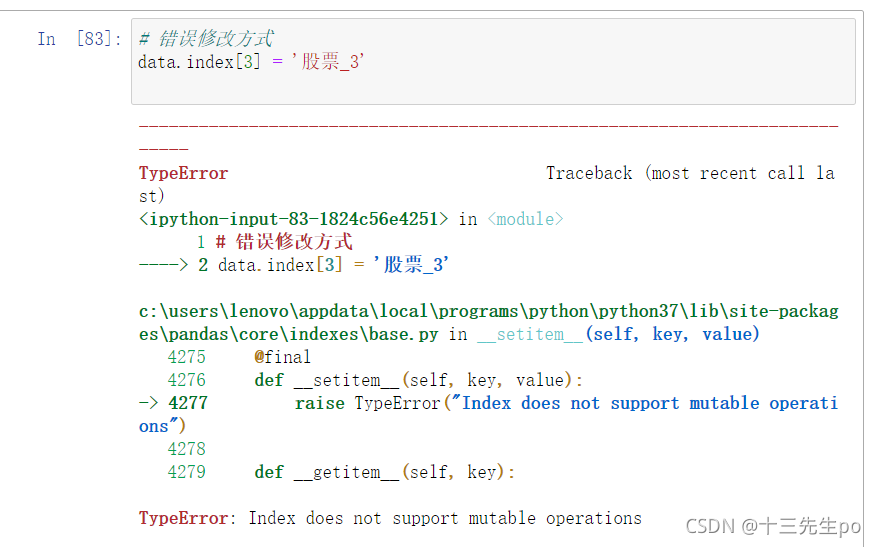
注意:以下修改方式是错误的
- 错误写法1
# 错误修改方式
data.index[3] = '股票_3'
#报错: TypeError: Index does not support mutable operations
- 错误写法2:
# 错误
# 构造行索引序列
st_code = ['股票'+str(i) for i in range(st_change.shape[0])]
print(st_code)
# 添加行索引
data = pd.DataFrame(st_change, index=st_code)
data
正确的方式:
写法1:对dataframe结构的行索引index直接更改,有可能出问题,取决于赋什么值。以前这样做可以,现在不太推荐了
stock_code = ["股票_" + str(i) for i in range(stock_change.shape[0])]
# 必须整体全部修改
data.index = stock_code
写法2:用rename方法改
df.rename(index={原行索引名:替换行索引名})
data5 = np.random.normal(0,1,(10,5))
data5 = pd.DataFrame(data5)
data5.rename(index={0:1,2:22})
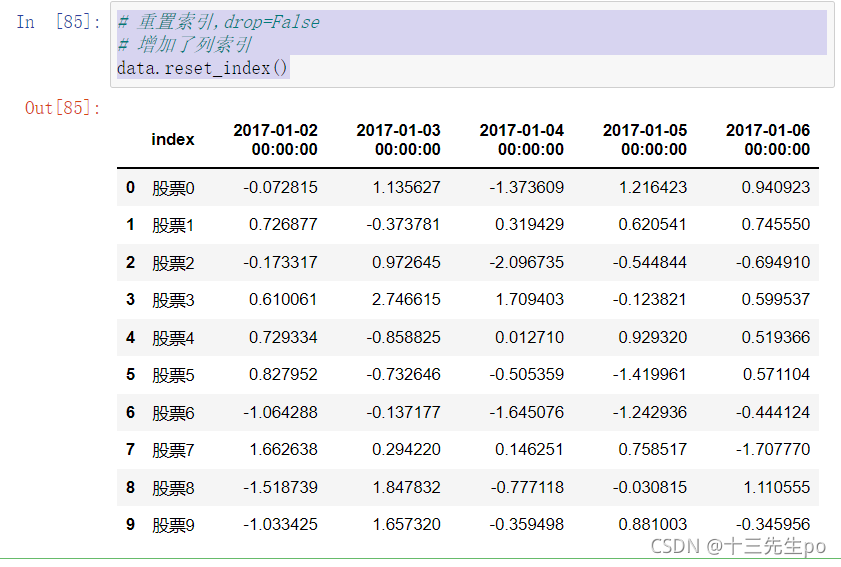
重设索引
- reset_index(drop=False)
- 设置新的下标索引
- drop:默认为False,不删除原来索引,如果为True,删除原来的索引值
# 重置索引,drop=False
# 增加了列索引
data.reset_index()
# 重置索引,drop=True
# 删掉原来的行索引
data.reset_index(drop=True)
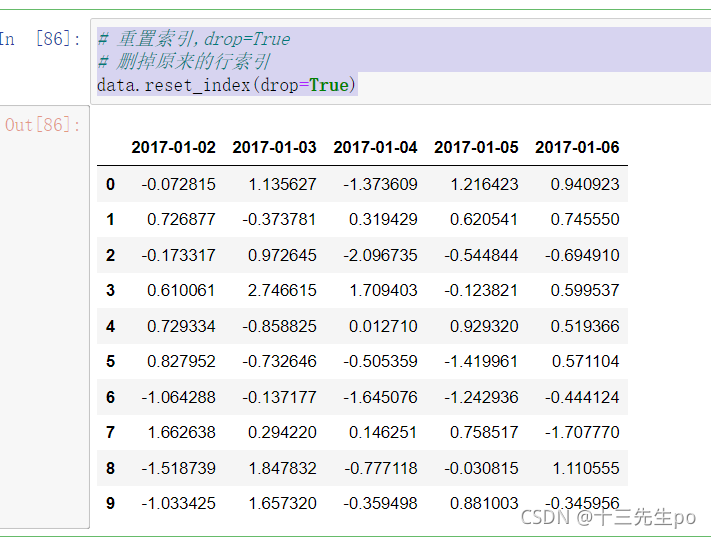
- 以某列值设置为新的索引
set_index(keys,drop=True)- keys : 列索引名成或者列索引名称的列表
- drop : boolean, default True.当做新的索引,删除原来的列
设置新索引案例
# 以某列值设置为新的索引
df = pd.DataFrame({'month': [1, 4, 7, 10],
'year': [2012, 2014, 2013, 2014],
'sale':[55, 40, 84, 31]})
print(df)
# 以月份设置新的索引
df.set_index('month')
# 设置多个索引,以年和月份
df.set_index(['year','month'])
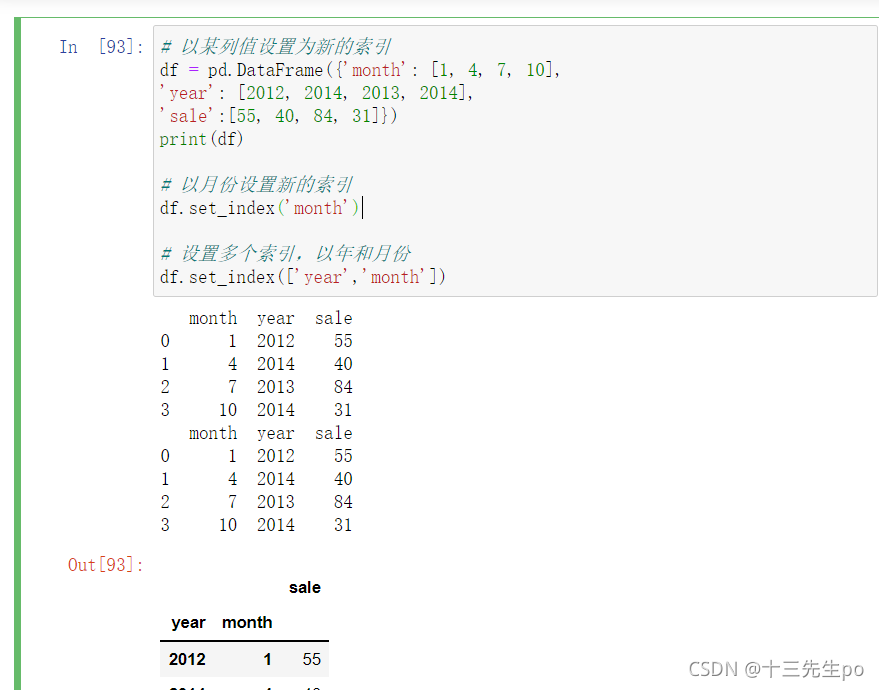
注:通过刚才的设置,这样DataFrame就变成了一个具有MultiIndex的DataFrame。
索引列名称的增加
效果如下:
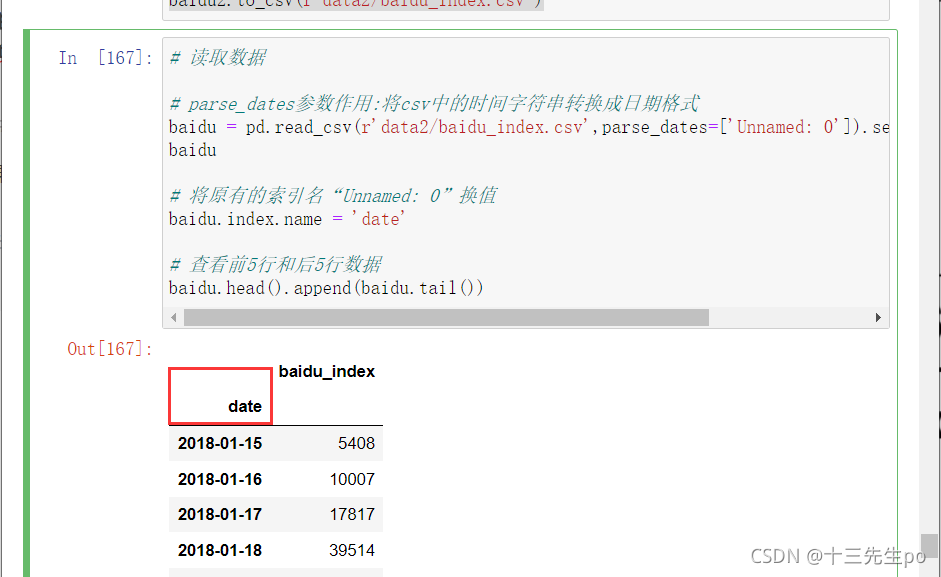
- baidu.index.name = ‘列名’
# 读取数据
# parse_dates参数作用:将csv中的时间字符串转换成日期格式
baidu = pd.read_csv(r'data2/baidu_index.csv',parse_dates=['Unnamed: 0']).set_index('Unnamed: 0')
baidu
# 将原有的索引名“Unnamed: 0”换值
baidu.index.name = 'date'
# 查看前5行和后5行数据
baidu.head().append(baidu.tail())
1.6 Series结构
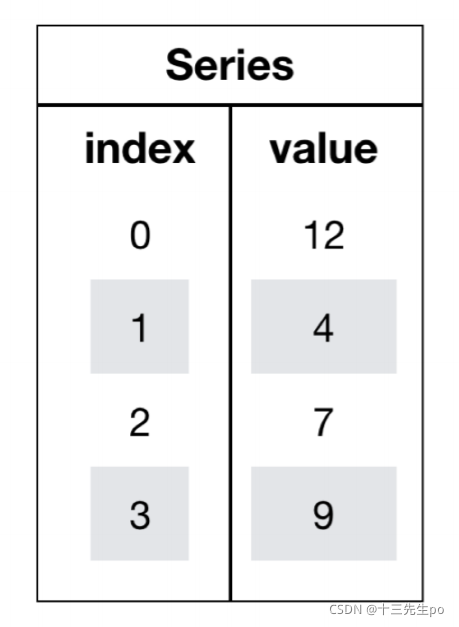
- series结构只有行索引
我们获取’股票0’的所有数据(可能要转置)
data
# series
data['股票0']
type(data['股票0'])
# 这一步相当于是series去获取行索引的值
data
data['股票0']['2017-01-02']
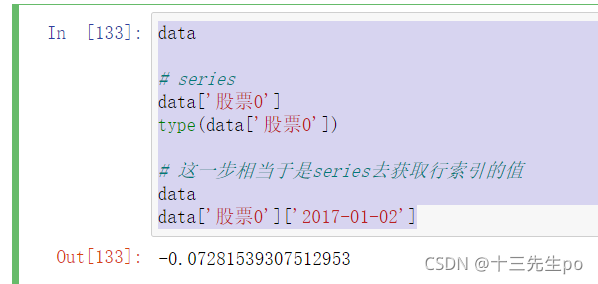
1.6.1 创建series
通过已有数据创建
- 指定内容,默认索引
# 创建series
# 指定内容,默认索引
pd.Series(np.arange(10))
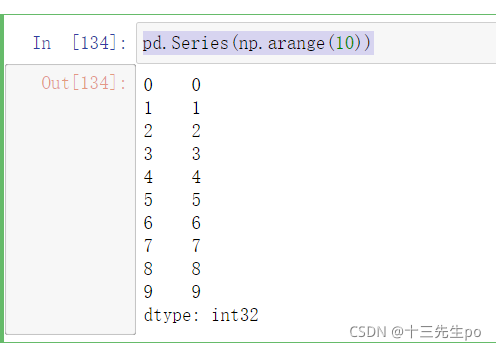
- 指定索引
# 创建series
# 指定索引
pd.Series([6.7, 5.6, 3, 10, 2], index=[1, 2, 3, 4, 5])
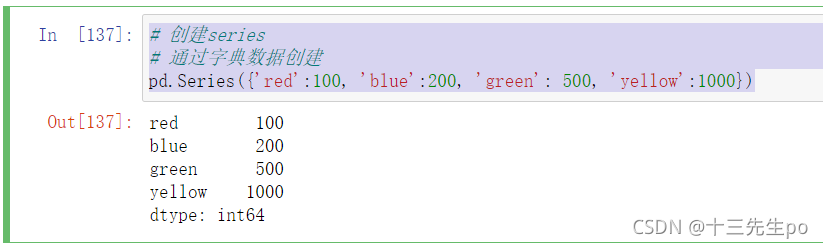
- 通过字典数据创建
# 创建series
# 通过字典数据创建
pd.Series({'red':100, 'blue':200, 'green': 500, 'yellow':1000})
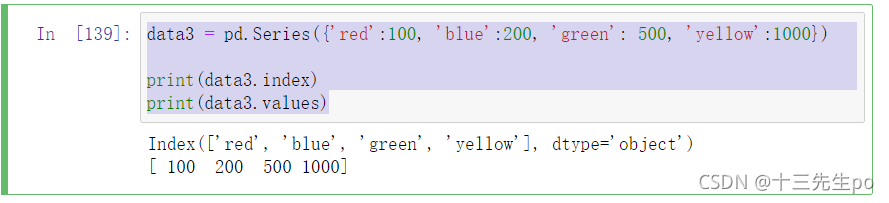
1.6.2 series获取索引和值
- index
- values
data3 = pd.Series({'red':100, 'blue':200, 'green': 500, 'yellow':1000})
print(data3.index)
print(data3.values)
1.7 小结
- pandas的三种数据结构
- DataFrame结构
- Series结构
- index索引对象
pandas库简介(1)–pandas的三种数据结构https://blog.csdn.net/zby1001/article/details/54234121
1.8 创建dataframe数据结构
以下方法并非独一,可以有多种方式创建
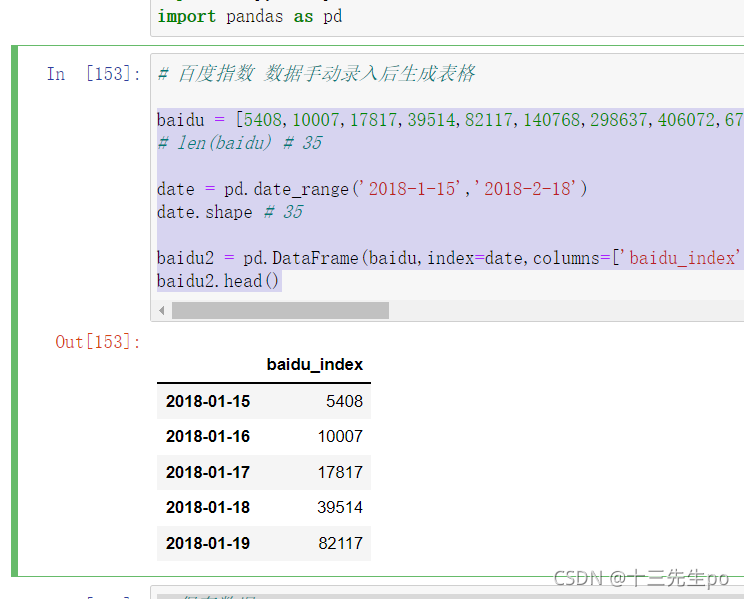
- pd.DataFrame(数据对象, index=索引列, columns=[‘列名称’])
baidu = [5408,10007,17817,39514,82117,140768,298637,406072,677541,858690,839792,744390,653541,496701,390412,322492,256334,212914,180933,157411,140104,120038,125914,105679,88426,75185,66567,61036,54812,49241,42768,35784,33774,33621,34388]
# len(baidu) # 35
date = pd.date_range('2018-1-15','2018-2-18')
date.shape # 35
baidu2 = pd.DataFrame(baidu,index=date,columns=['baidu_index'])
baidu2.head()
2 基本数据操作
2.1 索引操作
Numpy当中我们已经讲过使用索引选取序列和切片选择,pandas也支持类似的操作,也可以直接使用列名、行名称,甚至组合使用
2.1.1 直接使用行列索引(先列后行)
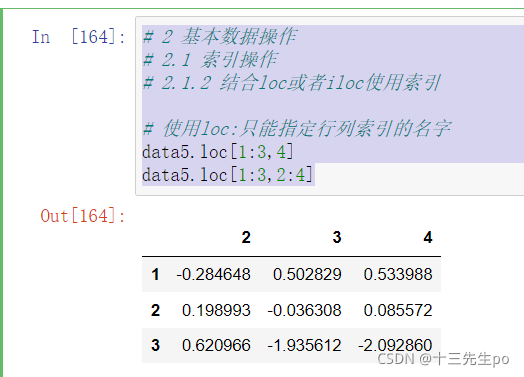
# 2 基本数据操作
# 2.1 索引操作
# 2.1.2 结合loc或者iloc使用索引
# 使用loc:只能指定行列索引的名字
data5.loc[1:3,4]
data5.loc[1:3,2:4]
2.1.2 结合loc或者iloc使用索引
# 2 基本数据操作
# 2.1 索引操作
# 2.1.2 结合loc或者iloc使用索引
# 使用loc:只能指定行列索引的名字
data5.loc[1:3,4]
data5.loc[1:3,2:4]
data5.loc[[1,3],[2,4]]
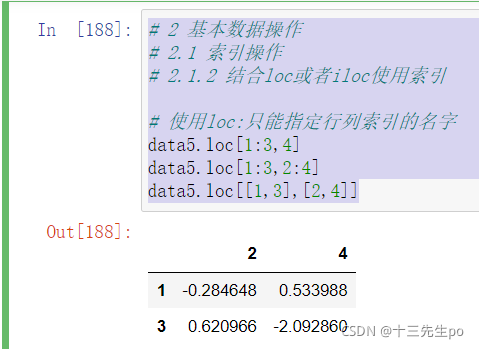
# 2 基本数据操作
# 2.1 索引操作
# 2.1.2 结合loc或者iloc使用索引
# 使用iloc可以通过索引的下标去获取
data5.iloc[0:8,4:5] # 得到一列
data5.iloc[0:8,3:6]
data5.iloc[[1,3],[2,3]]
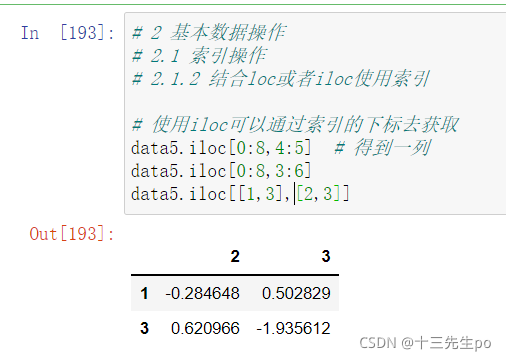
2.1.3 使用ix组合索引(已官方弃用)
已经被弃用
2.2 赋值操作
# 2.2 赋值操作
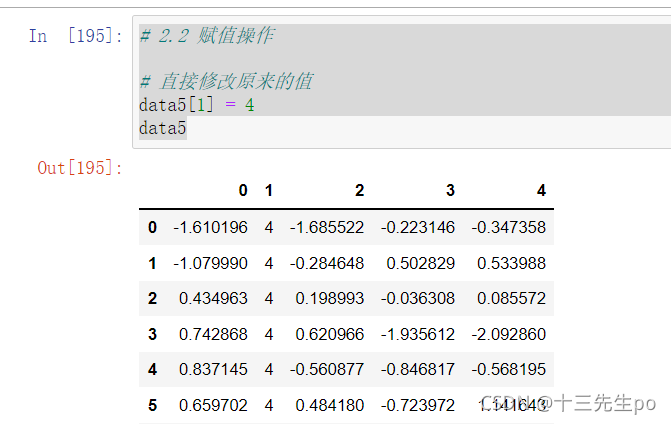
# 直接修改原来的值
data5[1] = 4
data5
2.3 排序
排序有两种形式,一种对内容进行排序,一种对索引进行排序
DataFrame排序
- 使用df.sort_values(key=, ascending=,by=)对内容进行排序
- 单个键或者多个键进行排序,默认升序
- ascending=False:降序
- ascending=True:升序
- by=‘xx’ 指定排序的关键值
# 2.3 排序
# DataFrame排序
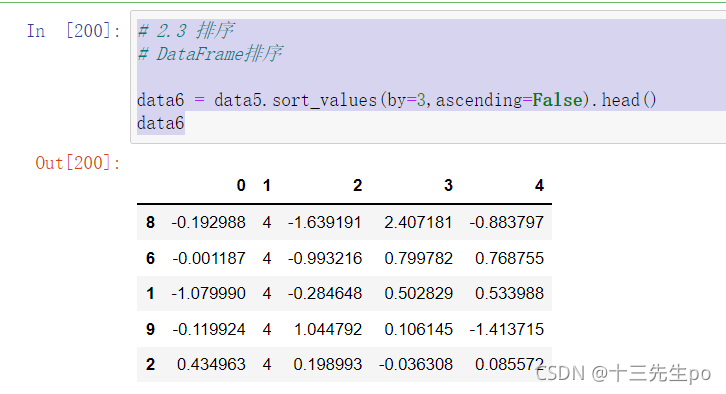
# 按照涨跌幅大小进行排序 , 使用ascending指定按照大小排序
data6 = data5.sort_values(by=3,ascending=False).head()
data6
# 2.3 排序
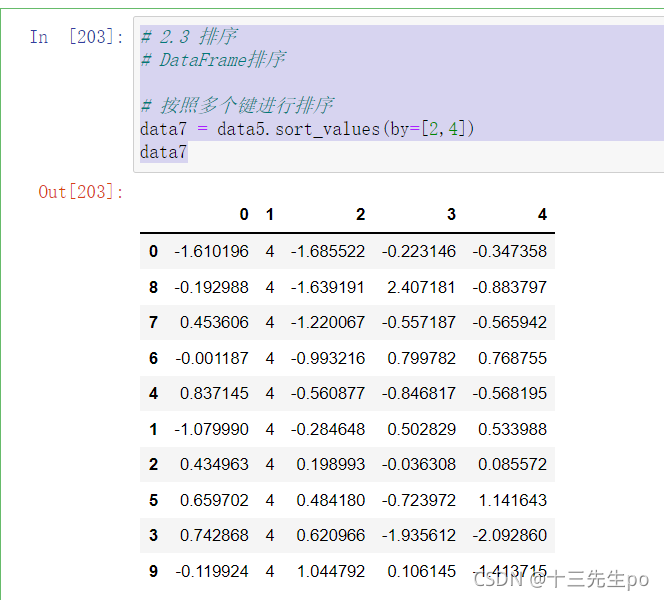
# DataFrame排序
# 按照多个键进行排序
data7 = data5.sort_values(by=[2,4])
data7
- 使用sort_index对索引进行排序
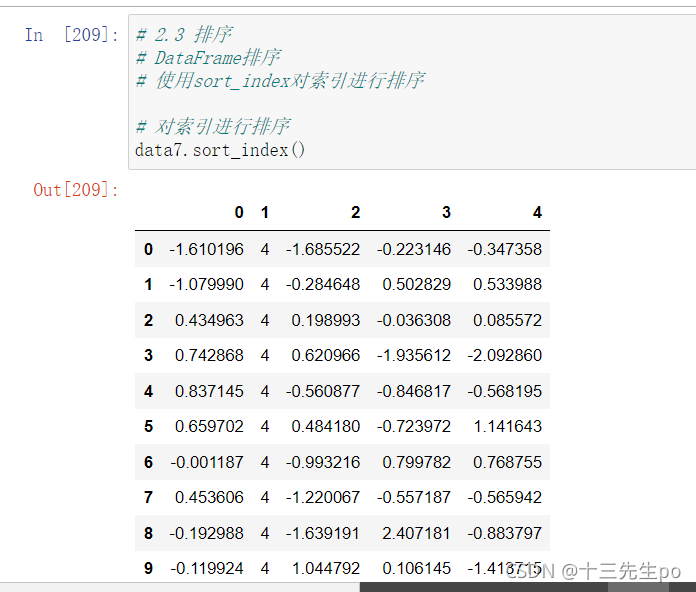
# 2.3 排序
# DataFrame排序
# 使用sort_index对索引进行排序
# 对索引进行排序
data7.sort_index()
1.9 其他设置
# 显示默认显示行数
pd.set_option('display.max_rows', 80) # 设为None为显示所有行
# 设置默认显示列数
# pd.set_option('display.max_columns', None)
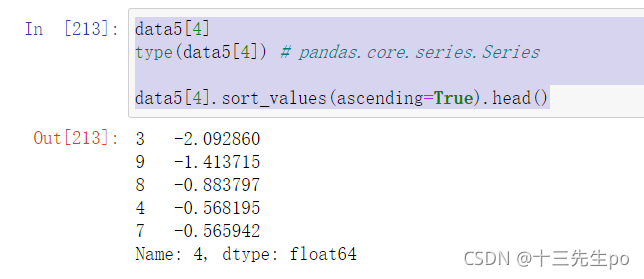
Series
- 使用series.sort_values(ascending=True)对内容进行排序
series排序时,只有一列,不需要参数
data5[4]
type(data5[4]) # pandas.core.series.Series
data5[4].sort_values(ascending=True).head()
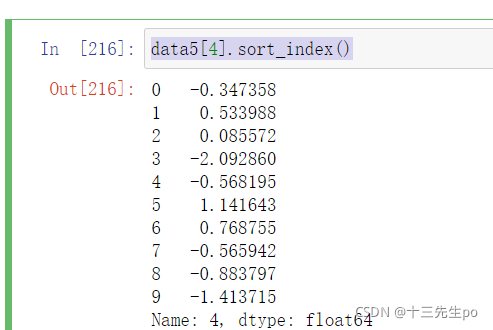
- 使用series.sort_index()对索引进行排序
与df一致
data5[4].sort_index()
2.4 查询列值(行值只能用loc或者iloc查询)
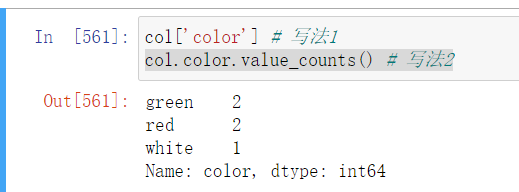
- pd.列名 或者 pd.[列名] 显示列数据
col['color'] # 写法1
col.color # 写法2
- 多列查询
# 指定列检查
e1 = explore[['null','max','min']]
e1
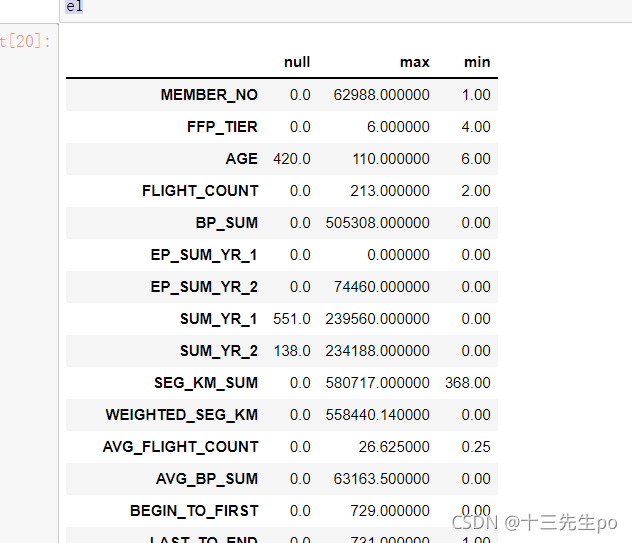
对查询列值聚合(计数)
- pd.列名.value_counts() # 直接获得一份简版交叉表
col.color.value_counts()
2.5 总结
- 索引操作,loc和iloc
- 赋值操作
- sort_values对内容进行排序
- sort_index对索引进行排序
3 DataFrame运算
3.1 算术运算
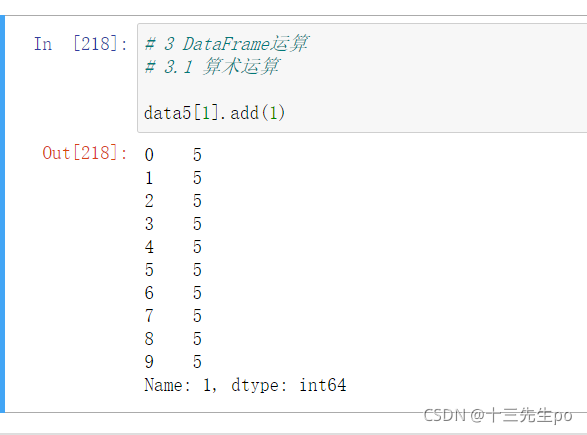
- add(other) # 加
比如进行数学运算加上具体的一个数字
# 3 DataFrame运算
# 3.1 算术运算
data5[1].add(1)
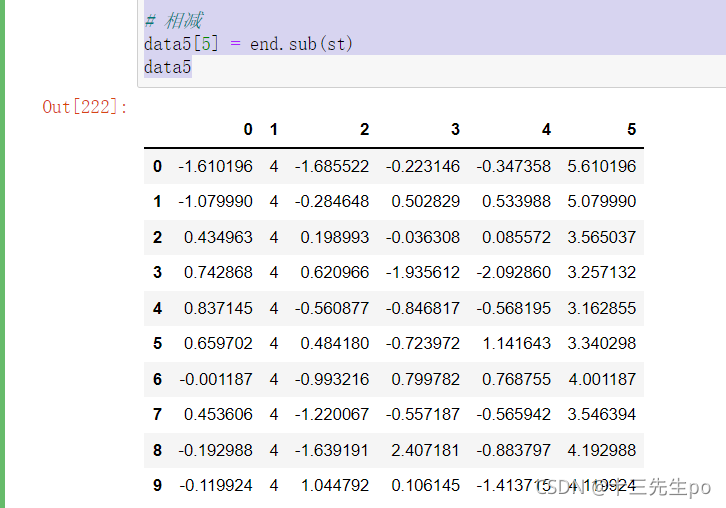
- sub(other) # 减
求差
# 3 DataFrame运算
# 3.1 算术运算
data5
# 1、筛选两列数据
st = data5[0]
end = data5[1]
# 相减
data5[5] = end.sub(st)
data5
- add()、sub()、mul()和div()分别表示加减乘除(注意乘法是对应元素相乘,而不是矩阵乘法)
# 3 DataFrame运算
# 3.1 算术运算
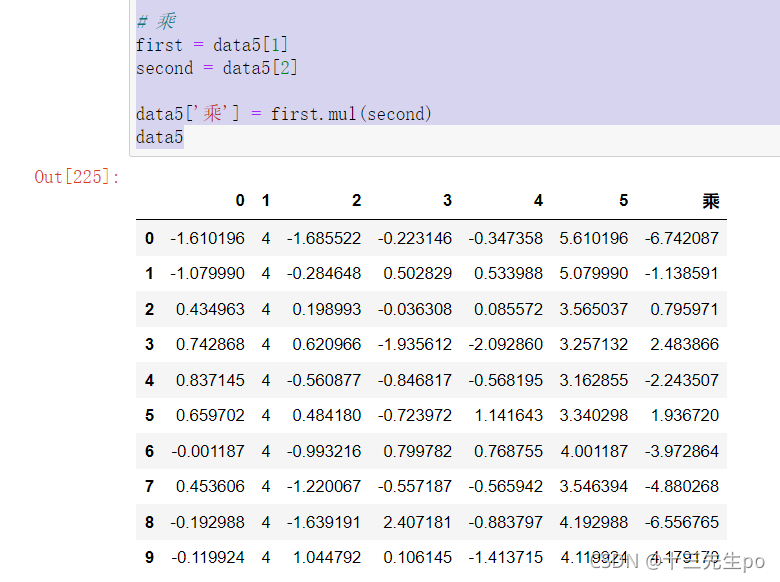
# 乘
first = data5[1]
second = data5[2]
data5['乘'] = first.mul(second)
data5
# 3 DataFrame运算
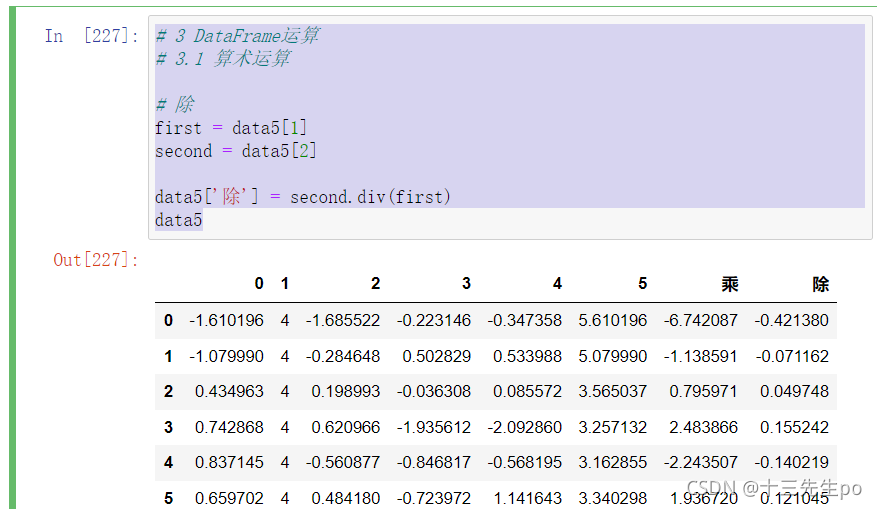
# 3.1 算术运算
# 除 被除数.div(除数)
first = data5[1]
second = data5[2]
data5['除'] = second.div(first)
data5
3.2 逻辑运算
3.2.1 逻辑运算符号<、 >、|、 &
筛选单个结果
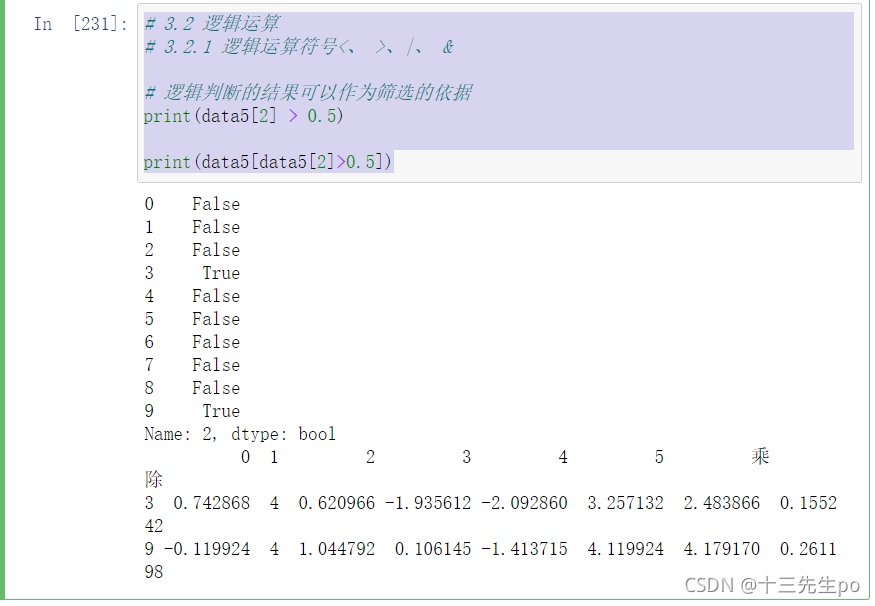
# 3.2 逻辑运算
# 3.2.1 逻辑运算符号<、 >、|、 &
# 逻辑判断的结果可以作为筛选的依据
print(data5[2] > 0.5)
print(data5[data5[2]>0.5])
完成多个逻辑判断
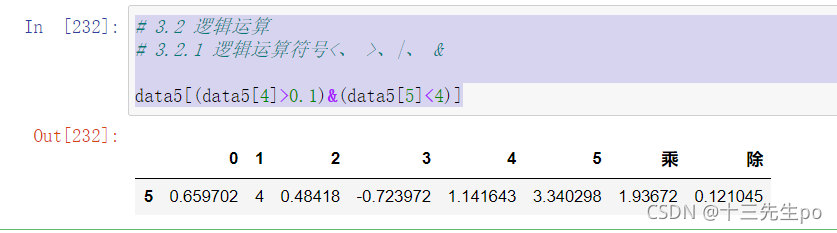
- 与判断 &
# 3.2 逻辑运算
# 3.2.1 逻辑运算符号<、 >、|、 &
data5[(data5[4]>0.1)&(data5[5]<4)]
- 或判断
# 3.2 逻辑运算
# 3.2.1 逻辑运算符号<、 >、|、 &
data5[(data5[4]>0.1)|(data5[5]<4)]
第二种写法
- == / !=等判断
index1 = data.SUM_YR_1 != 0
在这里插入代码片
3.2.2 逻辑运算函数
- query(expr)
- expr:查询字符串
通过query使得刚才的过程更加方便简单
# 3.2 逻辑运算
# 3.2.2 逻辑运算函数
data5.query("乘>0 | 除>0")
- isin(values)
# 3.2 逻辑运算
# 3.2.2 逻辑运算函数
data5[data5[1].isin([4])]
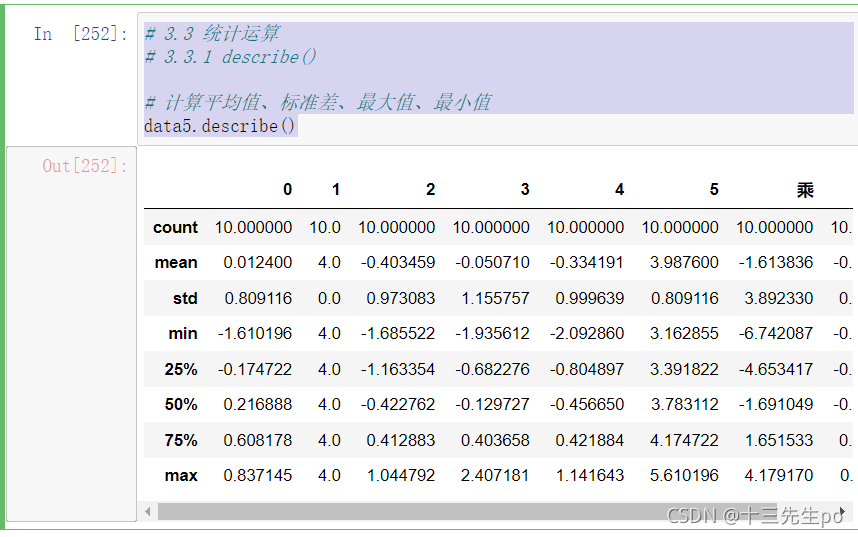
3.3 统计运算
3.3.1 describe()
综合分析: 能够直接得出很多统计结果, count , mean , std , min , max 等
# 3.3 统计运算
# 3.3.1 describe()
# 计算平均值、标准差、最大值、最小值
data5.describe()
3.3.2 统计函数
Numpy当中已经详细介绍,在这里我们演示min(最小值), max(最大值), mean(平均值), median(中位数), var(方差), std(标准差)结果
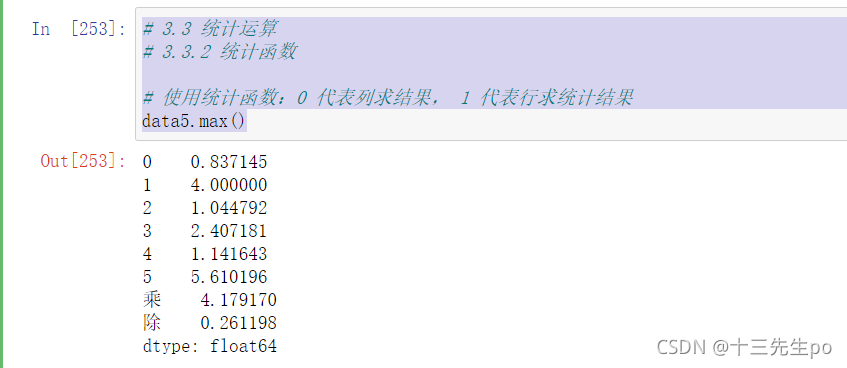
对于单个函数去进行统计的时候,坐标轴还是按照这些默认为“columns” (axis=0, default),如果要对行“index” 需要指定(axis=1)
- max()、min()
# 3.3 统计运算
# 3.3.2 统计函数
# 使用统计函数:0 代表列求结果, 1 代表行求统计结果
data5.max()
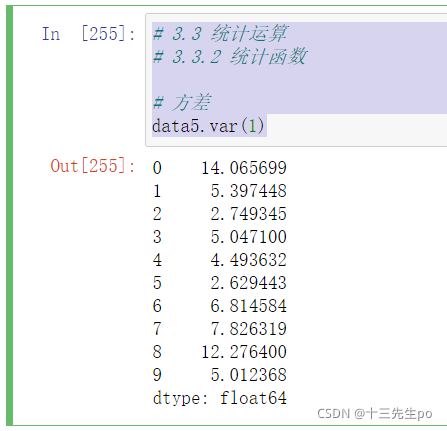
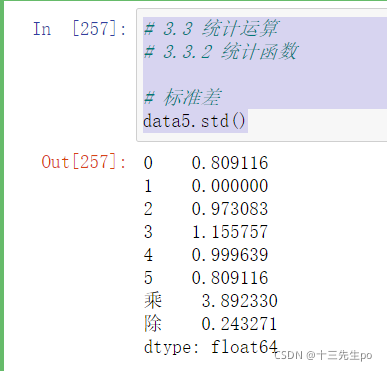
- std()、var()
# 3.3 统计运算
# 3.3.2 统计函数
# 方差
data5.var(1)
# 3.3 统计运算
# 3.3.2 统计函数
# 标准差
data5.std()
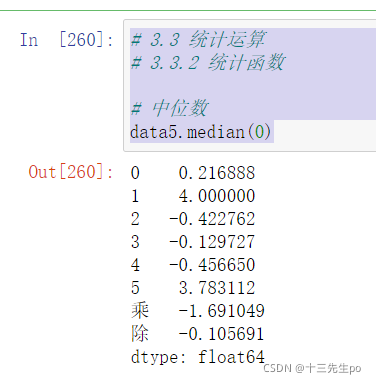
- median():中位数
中位数为将数据从小到大排列,在最中间的那个数为中位数。如果没有中间数,取中间两个数的平均值。
# 3.3 统计运算
# 3.3.2 统计函数
# 中位数
data5.median(0)
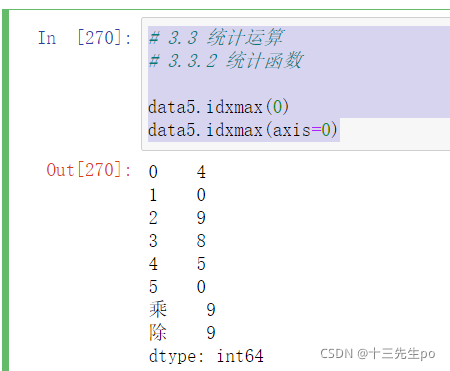
- idxmax() # 求出最大值的位置、idxmin() # 求出最小值的位置
# 3.3 统计运算
# 3.3.2 统计函数
data5.idxmax(0)
data5.idxmax(axis=0)
# 3.3 统计运算
# 3.3.2 统计函数
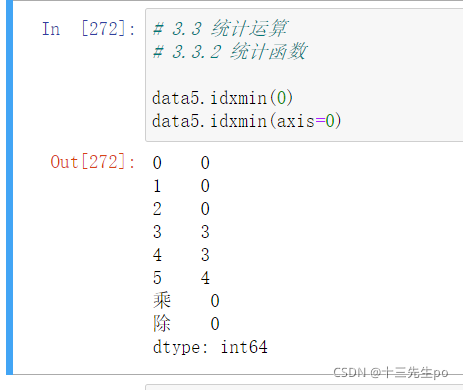
data5.idxmin(0)
data5.idxmin(axis=0)
3.4 累计统计函数
| 函数 | 作用 |
|---|---|
| cumsum | 计算前1/2/3/…/n个数的和(值一个个累计上去) |
| cummax | 计算前1/2/3/…/n个数的最大值 |
| cummin | 计算前1/2/3/…/n个数的最小值 |
| cumprod | 计算前1/2/3/…/n个数的积 |
以上这些函数可以对series和dataframe操作
这里我们按照时间的从前往后来进行累计
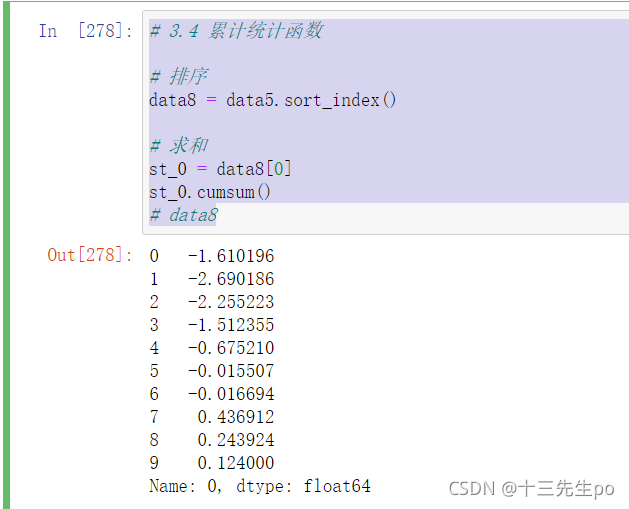
# 3.4 累计统计函数
# 排序
data8 = data5.sort_index()
# 求和
st_0 = data8[0]
st_0.cumsum()
# data8
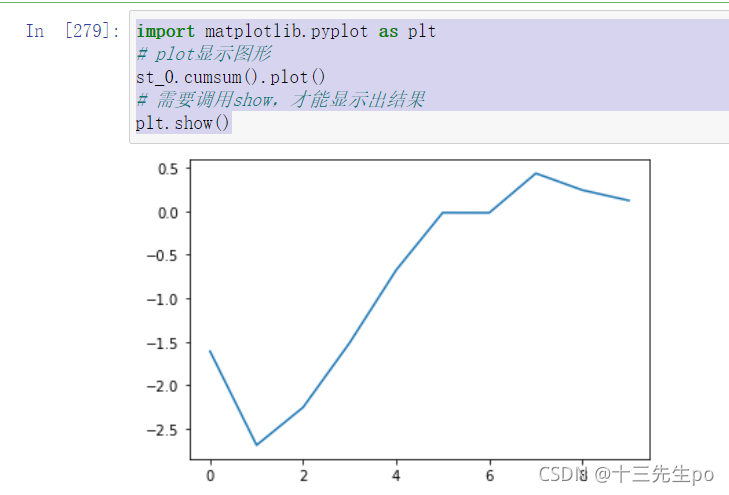
使用plot函数画出图像
import matplotlib.pyplot as plt
# plot显示图形
st_0.cumsum().plot()
# 需要调用show,才能显示出结果
plt.show()
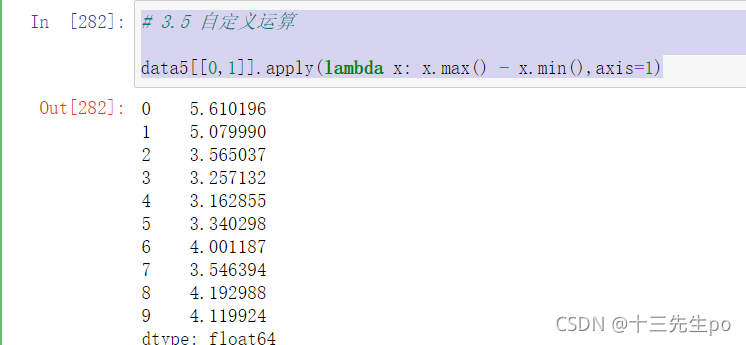
3.5 自定义运算
- apply(func, axis=0)
- func:自定义函数
- axis=0:默认是列,axis=1为行进行运算
案例:定义一个对列,最大值-最小值的函数
# 3.5 自定义运算
data5[[0,1]].apply(lambda x: x.max() - x.min(),axis=1)
4 Pandas画图
4.1 pandas.DataFrame.plot
- DataFrame.plot (x=None, y=None, kind=‘line’)
- x : label or position, default None
- y : label, position or list of label, positions, default None
- Allows plotting of one column versus another
- kind : str
- ‘line’ : line plot (default)
- ‘bar’ : vertical bar plot
- ‘barh’ : horizontal bar plot
- ‘hist’ : histogram
- ‘pie’ : pie plot
- ‘scatter’ : scatter plot
更多参数细节:https://pandas.pydata.org/pandas-docs/stable/generated/pandas.DataFram
e.plot.html?highlight=plot#pandas.DataFrame.plot
4.2 pandas.Series.plot
更多参数细节:https://pandas.pydata.org/pandas-docs/stable/generated/pandas.Series.plo
t.html?highlight=plot#pandas.Series.plot
5 文件读取与存储
我们的数据大部分存在于文件当中,所以pandas会支持复杂的IO操作,pandas的API支持众多的文件格式,如CSV、SQL、XLS、JSON、HDF5。
注:最常用的HDF5和CSV文件
5.1 CSV
5.1.1 读取csv文件-read_csv
- pandas.read_csv(filepath_or_buffer, sep =’,’ , delimiter = None,parse_dates=[‘列名’])
- filepath_or_buffer:文件路径
- usecols:指定读取的列名,列表形式
- parse_dates=[‘列名’] 将csv中的时间字符串转换成日期格式
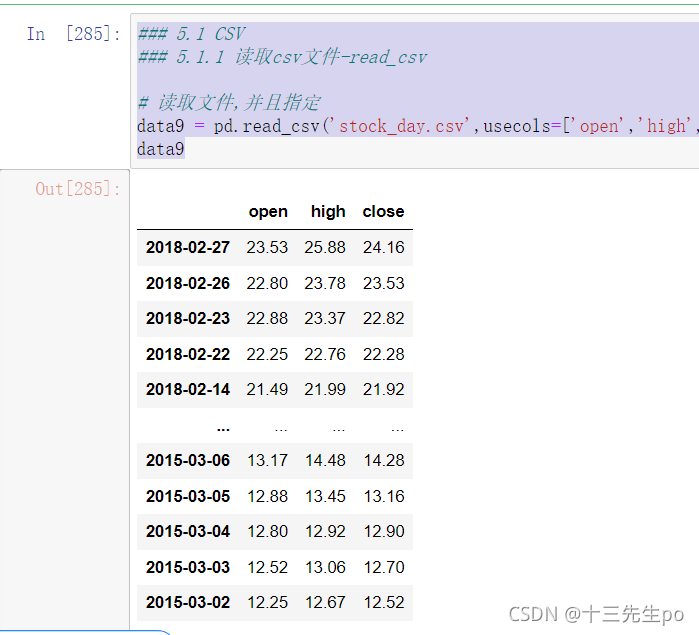
### 5.1 CSV
### 5.1.1 读取csv文件-read_csv
# 读取文件,并且指定
data9 = pd.read_csv('stock_day.csv',usecols=['open','high','close'])
data9
- 带日期格式的数据结构写法
# 读取数据
# parse_dates参数作用:将csv中的时间字符串转换成日期格式
baidu = pd.read_csv(r'data2/baidu_index.csv',parse_dates=['Unnamed: 0']).set_index('Unnamed: 0')
baidu
# 将原有的索引名“Unnamed: 0”换值
baidu.index.name = 'date'
# 查看前5行和后5行数据
baidu.head().append(baidu.tail())
5.1.2 写入csv文件-to_csv
- DataFrame.to_csv (path_or_buf=None, sep=’, ’, columns=None, header=True, index=True,
index_label=None, mode=‘w’, encoding=None)- path_or_buf :string or file handle, default None
- sep :character, default ‘,’
- columns :sequence, optional
- mode:‘w’:重写, ‘a’ 追加
- index:是否写进行索引
- header :boolean or list of string, default True,是否写进列索引值
to_csv的更多参数详解:pandas.read_csv参数详解
- Series.to_csv (path=None, index=True, sep=’, ‘, na_rep=’’, float_format=None, header=False,
index_label=None, mode=‘w’, encoding=None, compression=None, date_format=None,
decimal=’.’)- Write Series to a comma-separated values (csv) file
### 5.1 CSV
# 5.1.2 写入csv文件-to_csv
# 保存'open'列的数据
data9
# 选取10行数据保存,便于观察数据
data9[:10].to_csv('test1.csv',columns=['open'])
读取,查看结果
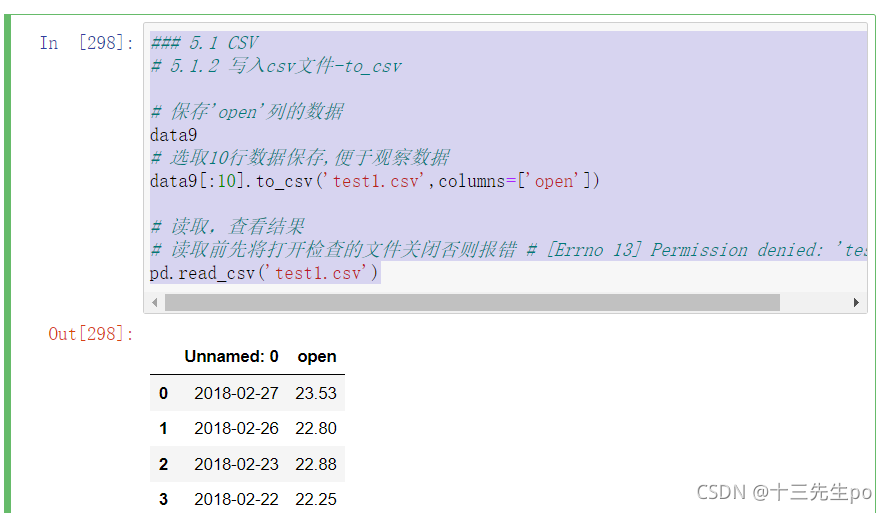
### 5.1 CSV
# 5.1.2 写入csv文件-to_csv
# 保存'open'列的数据
data9
# 选取10行数据保存,便于观察数据
data9[:10].to_csv('test1.csv',columns=['open'])
# 读取,查看结果
# 读取前先将打开检查的文件关闭否则报错 # [Errno 13] Permission denied: 'test1.csv'
pd.read_csv('test1.csv')
会发现将索引存入到文件当中,变成单独的一列数据。如果需要删除,可以指定index参数,删除原来的文件,重新保存一次。
# 会发现将索引存入到文件当中,变成单独的一列数据。如果需要删除,可以指定index参数,删除原来的文件,重新保存一次。
# index:存储不会将索引值变成一列数据
data9[:10].to_csv('test2.csv',columns=['open'],index=False)
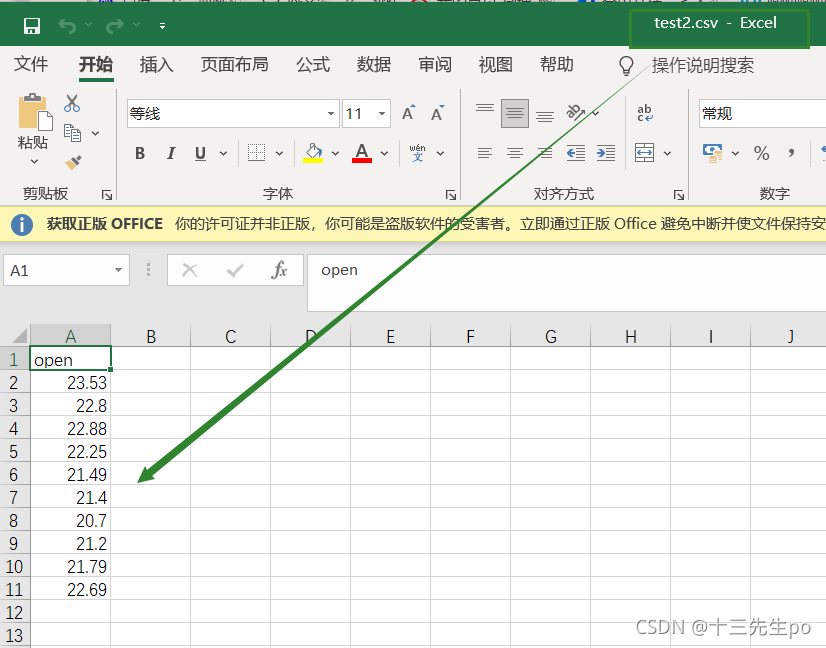
- 指定追加方式
# 指定追加方式
data9[:10].to_csv('test2.csv',columns=['open'],index=False,mode='a')
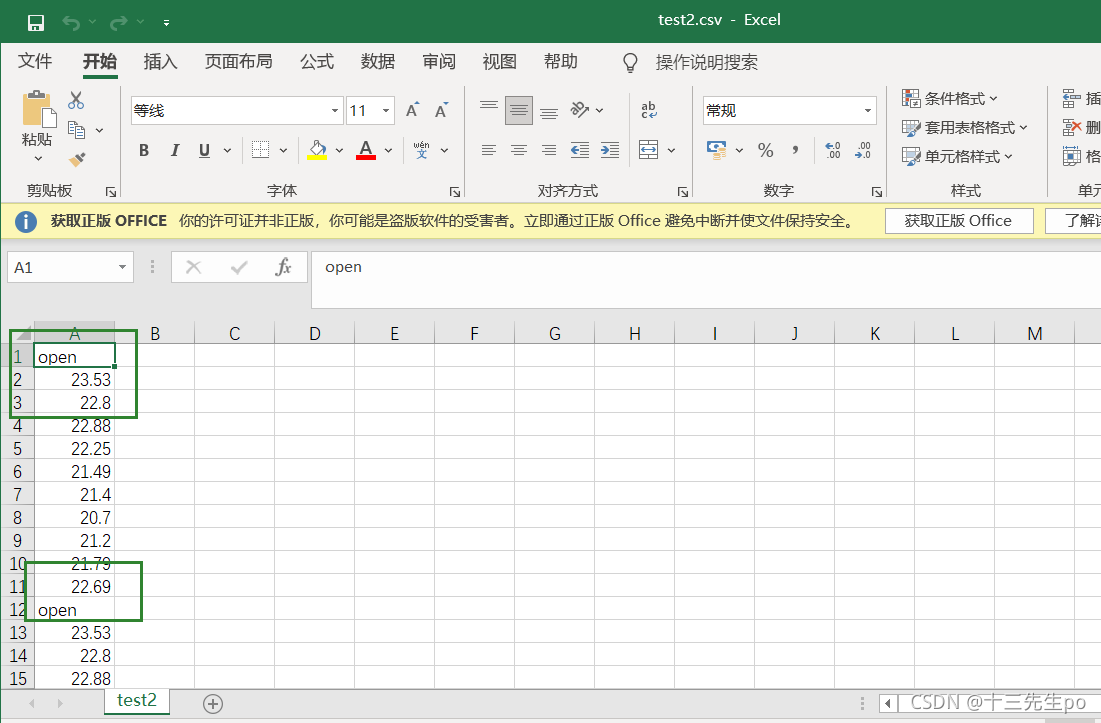
又存进了一个列名,所以当以追加方式添加数据的时候,一定要去掉列名columns,指定header=False
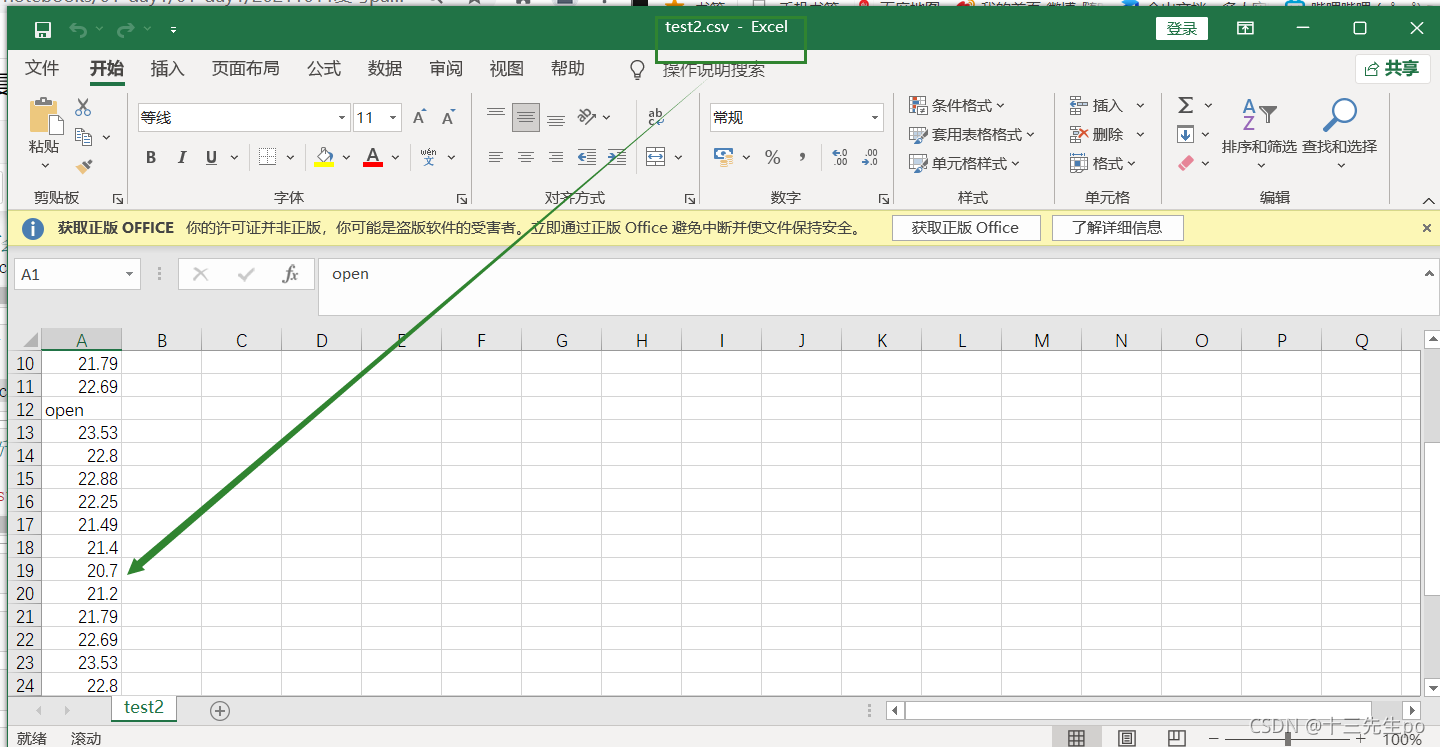
# 又存进了一个列名,所以当以追加方式添加数据的时候,一定要去掉列名columns,指定header=False
data9[:10].to_csv('test2.csv',columns=['open'],index=False,mode='a',header=False)
5.2 HDF5
5.2.1 read_hdf与to_hdf
HDF5文件的读取和存储需要指定一个键,值为要存储的DataFrame
- pandas.read_hdf(path_or_buf,key =None,** kwargs)
从h5文件当中读取数据
-path_or_buffer:文件路径
-key:读取的键
-mode:打开文件的模式
-return:Theselected object
- DataFrame.to_hdf (path_or_buf, key, **kwargs)
案例
- 读取文件
# 5.2 HDF5
# 5.2.1 read_hdf与to_hdf
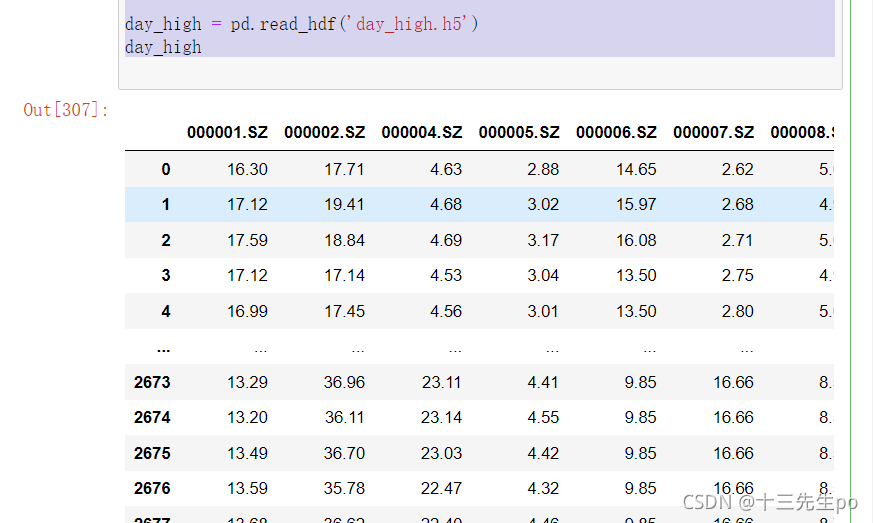
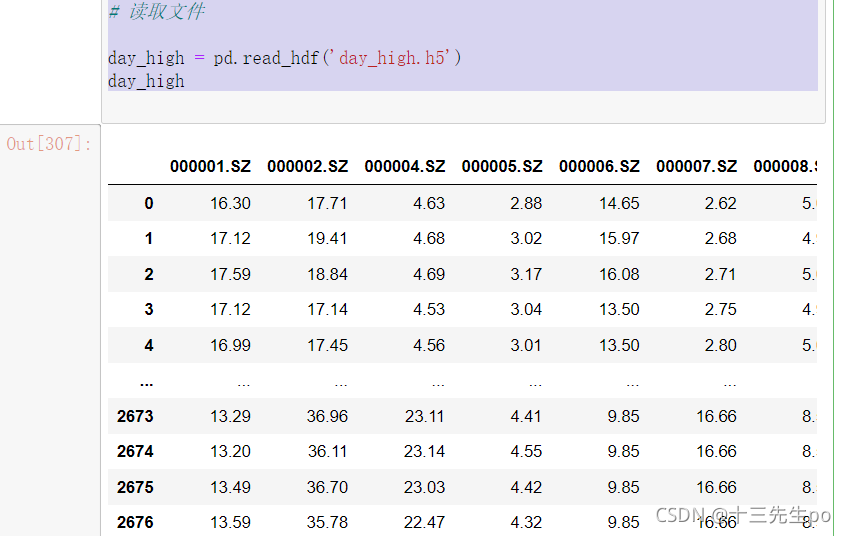
# 读取文件
day_high = pd.read_hdf('day_high.h5')
day_high
如果读取的时候出现以下错误
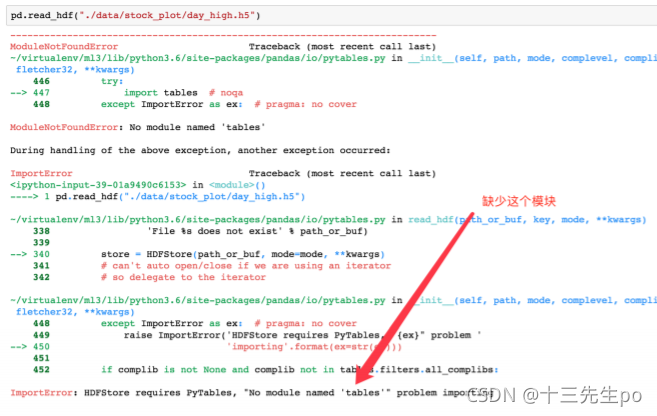
需要安装安装tables模块避免不能读取HDF5文件
pip install tables

- 存储文件
# 5.2 HDF5
# 5.2.1 read_hdf与to_hdf
# 读取文件
day_high = pd.read_hdf('day_high.h5')
day_high
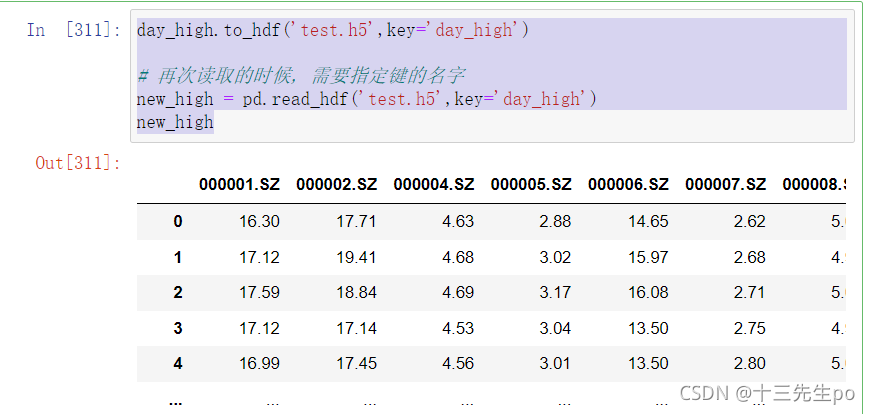
再次读取的时候, 需要指定键的名字
day_high.to_hdf('test.h5',key='day_high')
# 再次读取的时候, 需要指定键的名字
new_high = pd.read_hdf('test.h5',key='day_high')
new_high
5.3 JSON
Json是我们常用的一种数据交换格式,前面在前后端的交互经常用到,也会在存储的时候选择这种格式。所以我们需要知道Pandas如何进行读取和存储JSON格式。
5.3.1 read_json
- pandas.read_json(path_or_buf=None, orient=None, typ=‘frame’, lines=False)
- 将JSON格式准换成默认的Pandas DataFrame格式
- orient : string,Indication of expected JSON string format.
- ‘split’ : dict like {index -> [index], columns -> [columns], data -> [values]}
- ‘records’ : list like [{column -> value}, … , {column -> value}]
- ‘index’ : dict like {index -> {column -> value}}
- ‘columns’ : dict like {column -> {index -> value}},默认该格式
- ‘values’ : just the values array
- lines : boolean, default False
- 按照每行读取json对象
- typ : default ‘frame’, 指定转换成的对象类型series或者dataframe
案例
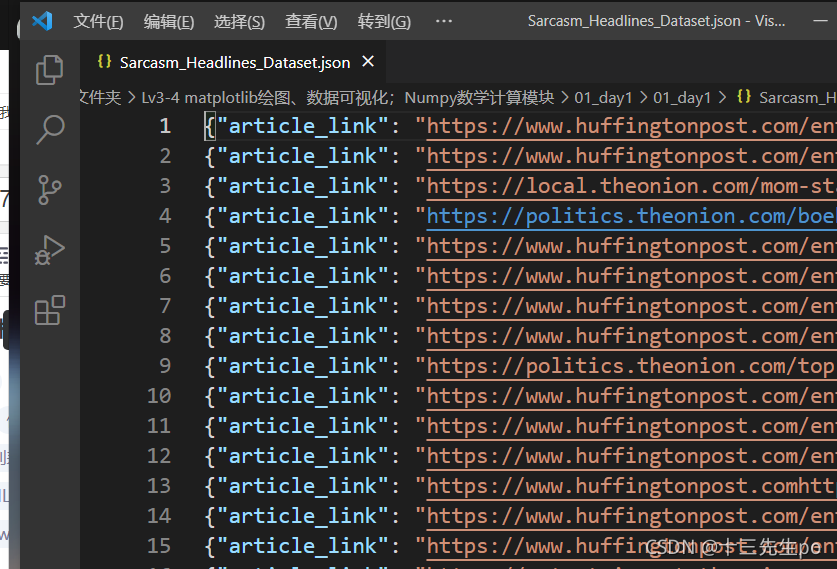
Sarcasm_Headlines_Dataset.json
- 数据介绍
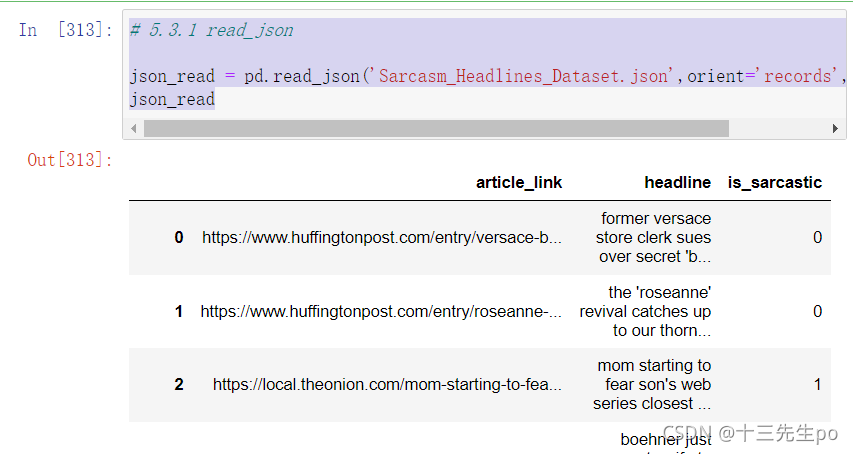
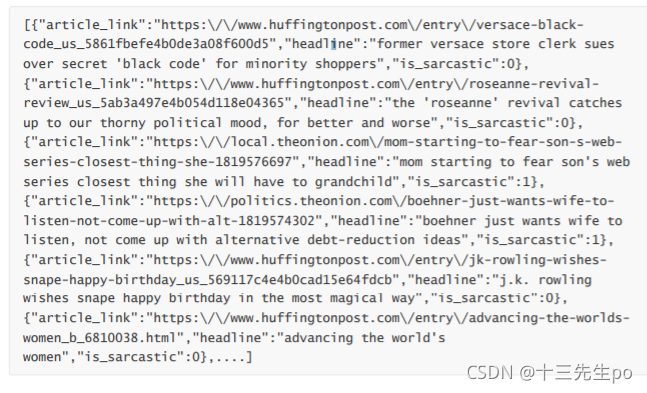
这里使用一个新闻标题讽刺数据集,格式为json。 is_sarcastic :1讽刺的,否则为0; headline :新闻报道的标题; article_link :链接到原始新闻文章。存储格式为:
- 读取
orient指定存储的json格式,lines指定按行作为一个样本
# 5.3.1 read_json
json_read = pd.read_json('Sarcasm_Headlines_Dataset.json',orient='records',lines=True)
json_read
5.3.2 to_json
- DataFrame.to_json(path_or_buf=None,orient=None,lines=False)
将Pandas 对象存储为json格式
path_or_buf=None:文件地址
orient:存储的json形式,{‘split’,’records’,’index’,’columns’,’values’}
lines:一个对象存储为一行
案例
- 存储文件
# 5.3.2 to_json
json_read.to_json('test.json',orient='records')
- 修改lines参数为True
# 修改lines参数为True
json_read.to_json('test.json',orient='records',lines=True)

5.4 excel
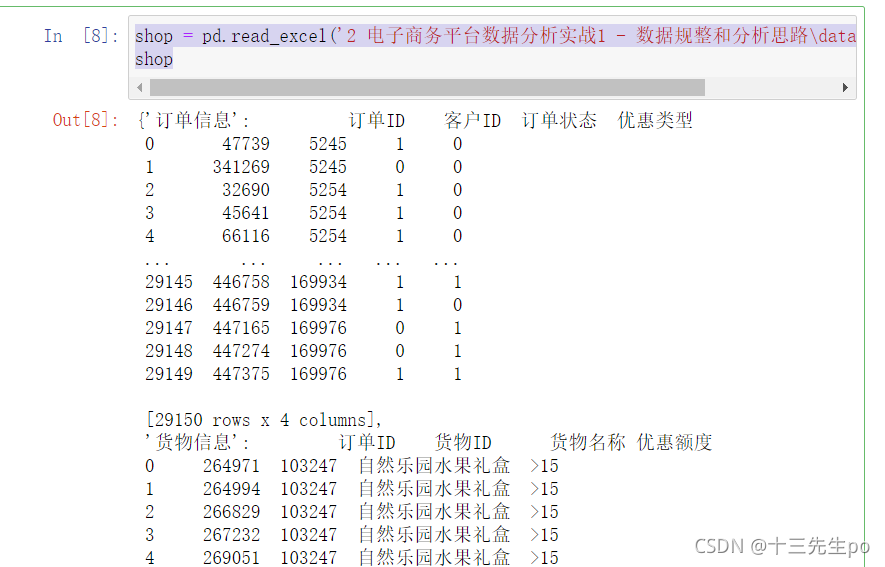
5.4.1 pd.read_excel(‘路径’,None)
- None 可以读取文件的所有表格
shop = pd.read_excel('2 电子商务平台数据分析实战1 - 数据规整和分析思路\data\shop.xlsx',None)
shop
5.5 拓展
优先选择使用HDF5文件存储
- HDF5在存储的是支持压缩,使用的方式是blosc,这个是速度最快的也是pandas默认支持的
- 使用压缩可以提磁盘利用率,节省空间
- HDF5还是跨平台的,可以轻松迁移到hadoop 上面
6 高级处理-缺失值处理
6.1 如何处理nan
对于NaN的数据,在numpy中我们是如何处理的?在pandas中我们处理起来非常容易
- 判断数据是否为NaN:pd.isnull(df),pd.notnull(df)
处理方式: - 存在缺失值nan,并且是np.nan:
- 1、删除存在缺失值的:dropna(axis=‘rows’)
- 注:不会修改原数据,需要接受返回值
- 2、替换缺失值:fillna(value, inplace=True)
- value:替换成的值
- inplace:True:会修改原数据,False:不替换修改原数据,生成新的对象
- 1、删除存在缺失值的:dropna(axis=‘rows’)
- 不是缺失值nan,有默认标记的
6.2 电影数据的缺失值处理
电影数据文件获取
# 6 高级处理-缺失值处理
# 6.2 电影数据的缺失值处理
# 读取电影数据
st = pd.read_csv('pandas_day.csv')
st
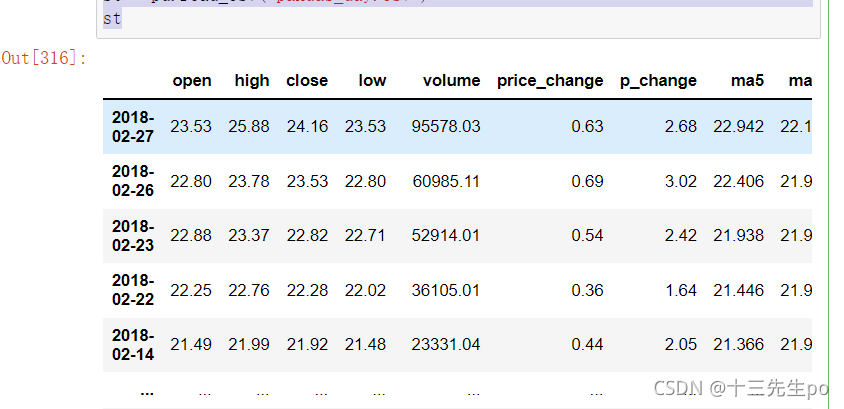
6.2.1 判断缺失值是否存在
- pd.notnull()
- pd.isnull()
# 6.2.1 判断缺失值是否存在
pd.notnull(st)
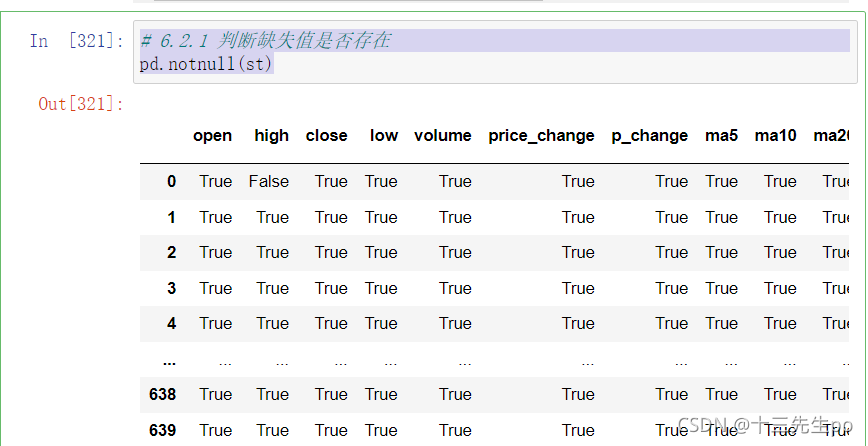
6.2.2 存在缺失值nan,并且是np.nan
1、删除
pandas删除缺失值,使用dropna的前提是,缺失值的类型必须是np.nan
# 6.2.2 存在缺失值nan,并且是np.nan
# 删除
# 不修改原数
st.dropna()
# 可以定义新的变量接受或者用原来的变量名
st1 = st.dropna()
st1
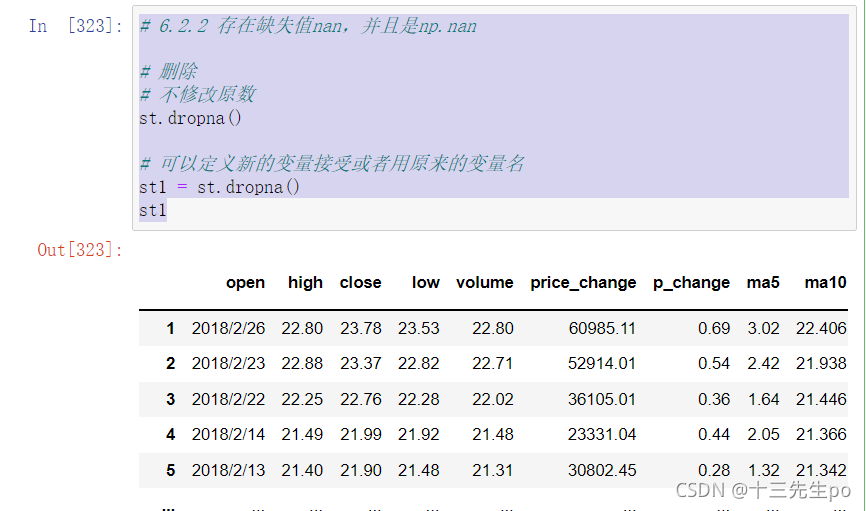
6.2.2 存在缺失值nan,并且是np.nan
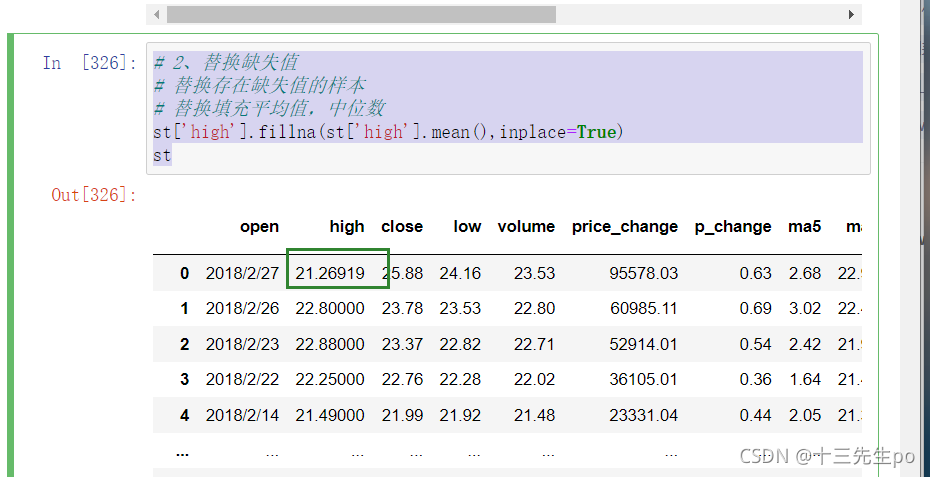
# 2、替换缺失值
# 替换存在缺失值的样本
# 替换填充平均值,中位数
st['high'].fillna(st['high'].mean(),inplace=True)
st
6.2.3 不是缺失值nan,有默认标记的
数据是这样的:
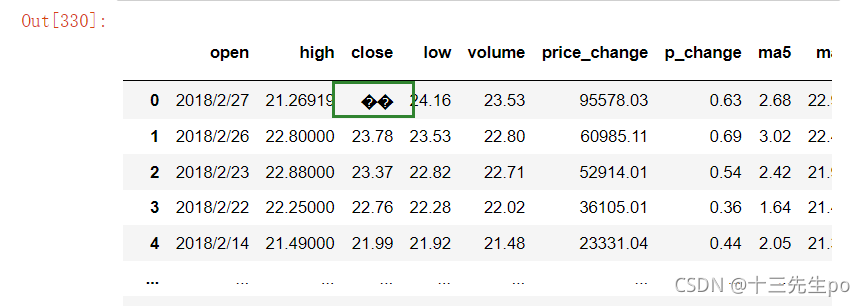
处理思路分析:
- 1、先替换‘?’为np.nan
- df.replace(to_replace=, value=)
- to_replace:替换前的值
- value:替换后的值
- df.replace(to_replace=, value=)
# 6.2.3 不是缺失值nan,有默认标记的
st = st.replace(to_replace='��',value=np.nan)
st
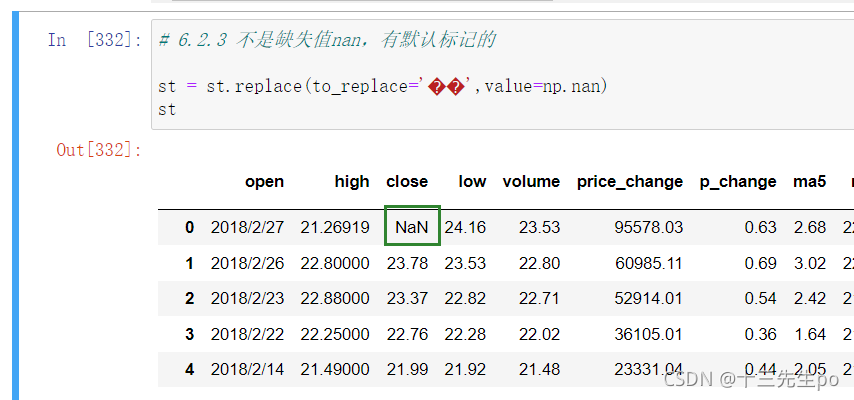
- 2、进行缺失值的处理
目前发现对缺失值的处理不能使用fillna替换,查看修改成nan值之后的整份文件的每一列数据的mean()时,无法查阅到close列的mean()值
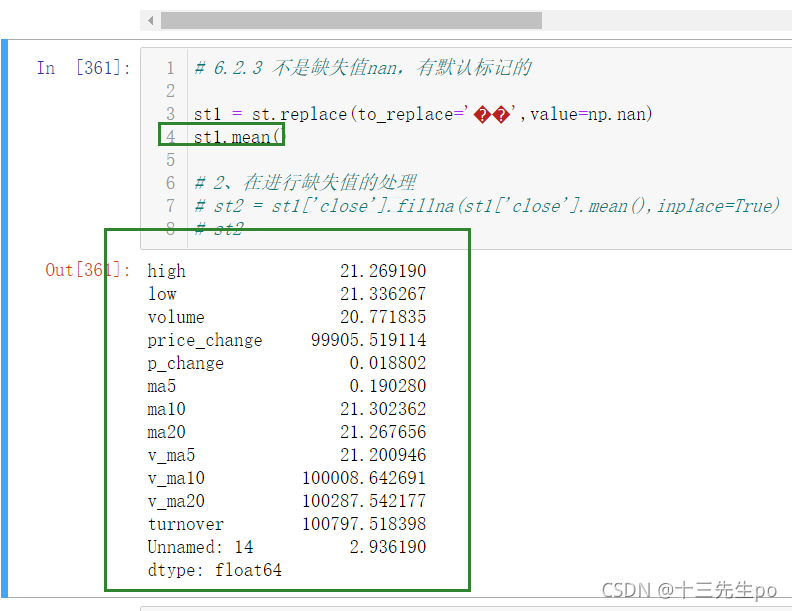
由于错误值的存在,已经将整列的数据类型变成了object字符串类型,不能使用fillna()方法来替换
方法1:直接删除
# 6.2.3 不是缺失值nan,有默认标记的
st1 = st.replace(to_replace='��',value=np.nan)
st1.mean()
st1
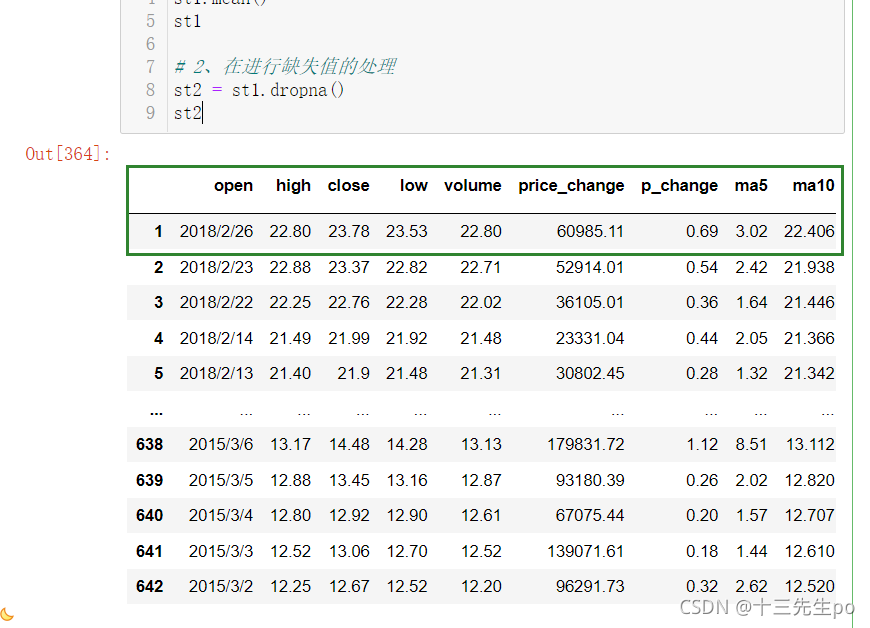
# 2、在进行缺失值的处理
# 删除
st2 = st1.dropna()
st2
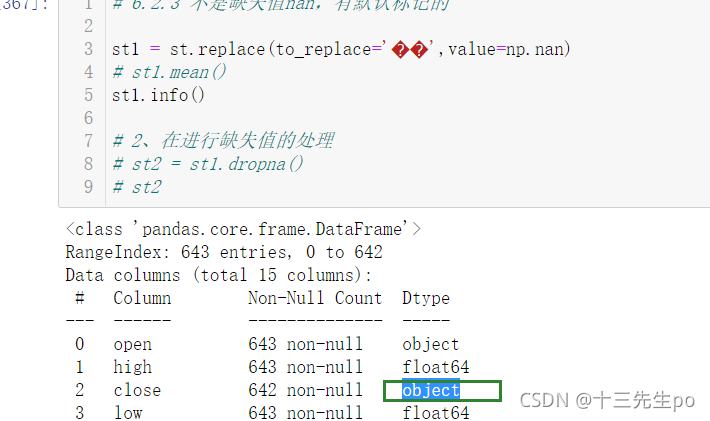
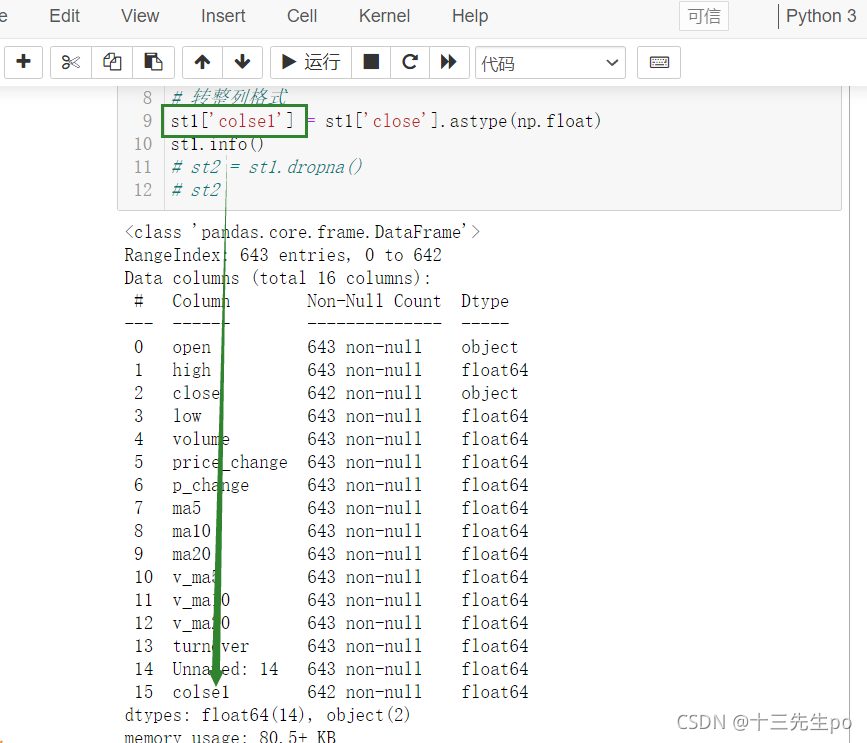
方法2:使用列数据类型转换方法
- astype(np.float)
给原数据增加个新列,把修改后的列赋值过去,删除旧列,或者直接用新列覆盖旧列
先看前者,增加新的列
st1['colse1'] = st1['close'].astype(np.float)
st1.info()
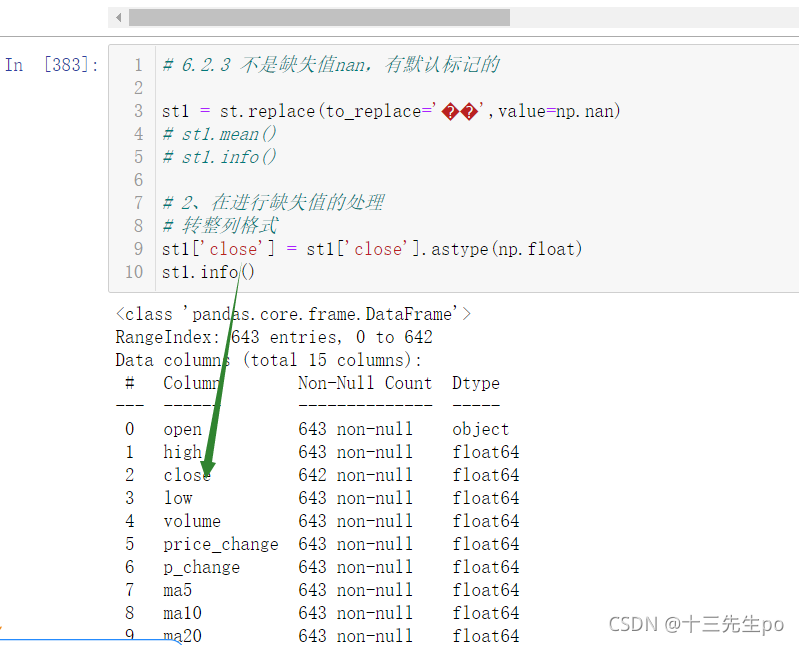
然后令旧的列等于该列即可,我们直接用新列覆盖旧列
# 6.2.3 不是缺失值nan,有默认标记的
st1 = st.replace(to_replace='��',value=np.nan)
# st1.mean()
st1.info()
# 2、在进行缺失值的处理
# 转整列格式
# 直接用新列覆盖旧列
st1['close'] = st1['close'].astype(np.float)
st1.info()
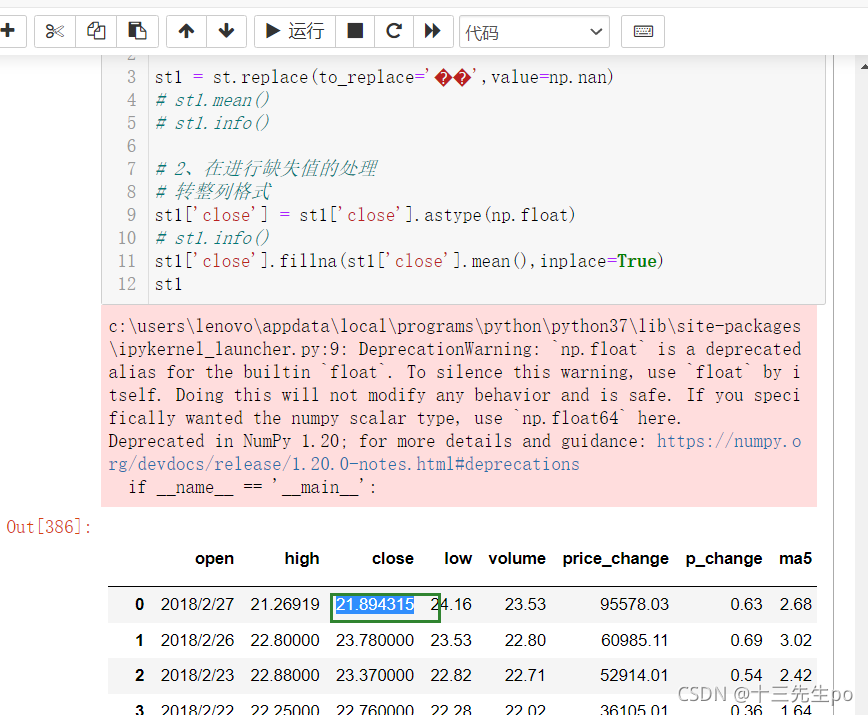
再使用fillna进行值的转换,修改成功
st1['close'].fillna(st1['close'].mean(),inplace=True)
st1
7 高级处理-数据离散化
7.1 什么是数据的离散化
连续属性的离散化就是将连续属性的值域上,将值域划分为若干个离散的区间,最后用不同的符号或整数 值代表落在每个子区间中的属性值。
离散化有很多种方法,这使用一种最简单的方式去操作
- 原始的身高数据:165,174,160,180,159,163,192,184
- 假设按照身高分几个区间段:(150, 165], (165, 180], (180, 195]
这样我们将数据分到了三个区间段,我可以对应的标记为矮、中、高三个类别,最终要处理成一个“哑变量”矩阵。

7.2 为什么要离散化
连续属性离散化的目的是为了简化数据结构,数据离散化技术可以用来减少给定连续属性值的个数。离散化方法经常作为数据挖掘的工具。
7.3 如何实现数据的离散化
案例:股票的涨跌幅离散化
我们对股票每日的"p_change"进行离散化
7.3.1 读取股票的数据
先读取股票的数据,筛选出p_change数据
# 7.3 如何实现数据的离散化
d1 = pd.read_csv('stock_day.csv')
d1
7.3.2 将股票涨跌幅数据进行分组
使用的工具:
- pd.qcut(data, bins):
对数据进行分组将数据分组 一般会与value_counts搭配使用,统计每组的个数 - series.value_counts():统计分组次数
自行分组
# 自行分组
qcut = pd.qcut(p_change,10)
# qcut
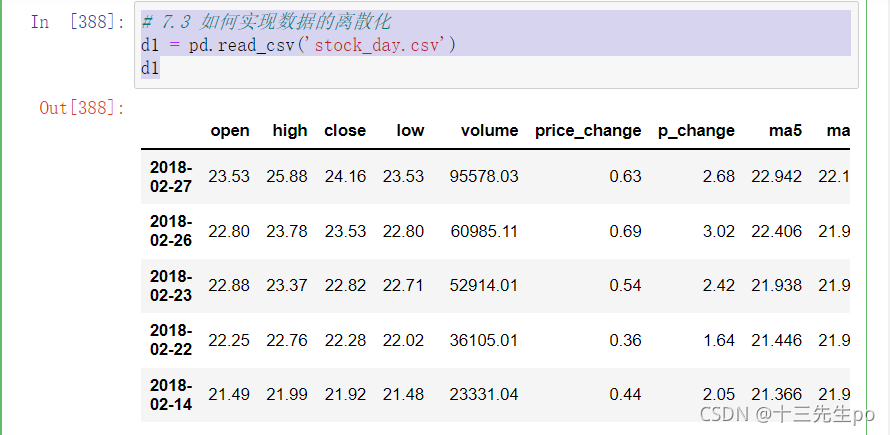
# 计算分到每个组数据个数
qcut.value_counts()
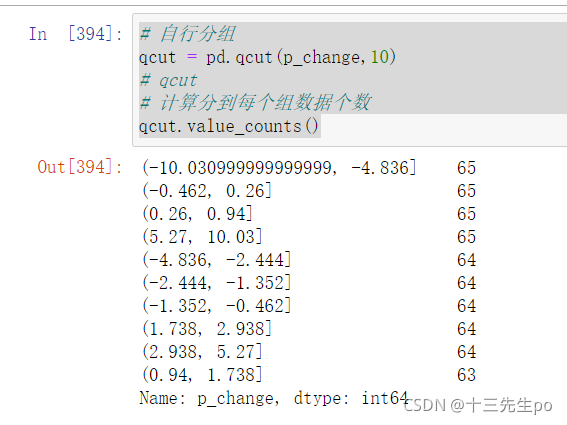
# 自行分组
qcut = pd.qcut(p_change,10)
qcut
直接输出qcut的内容会显示区间
自定义区间分组:
- pd.cut(data, bins)
# 自己指定分组区间
bins = [-100, -7, -5, -3, 0, 3, 5, 7, 100]
qcut1 = pd.cut(p_change,bins)
qcut1.value_counts()

7.3.3 股票涨跌幅分组数据变成one-hot编码
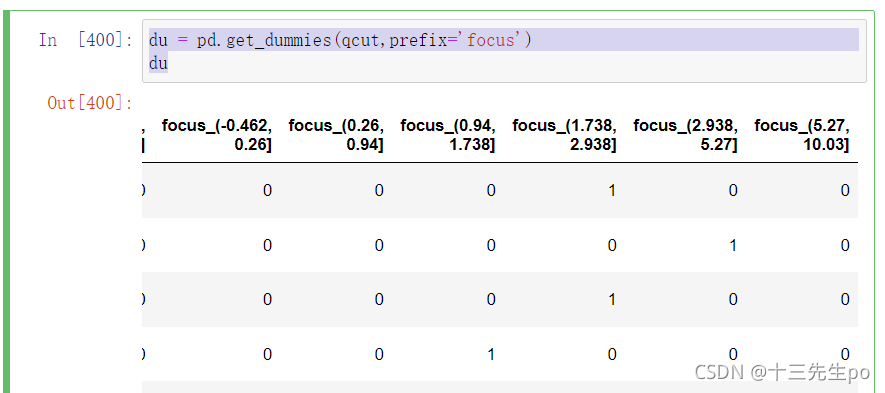
- pandas.get_dummies(data, prefix=None)
- data:array-like, Series, or DataFrame
- prefix:分组名字
du = pd.get_dummies(qcut,prefix='focus')
du
8 高级处理-合并
如果你的数据由多张表组成,那么有时候需要将不同的内容合并在一起分析
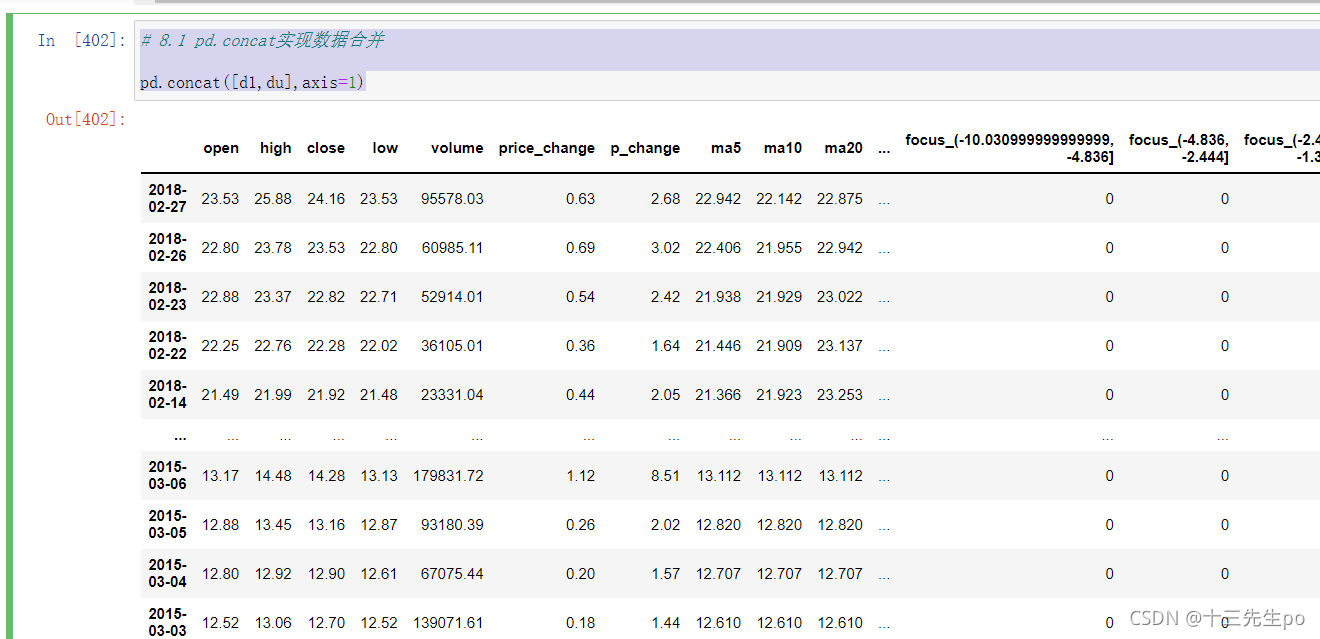
8.1 pd.concat实现数据合并
- pd.concat([data1, data2], axis=1)
- 按照行或列进行合并,axis=0为列索引,axis=1为行索引
比如我们将刚才处理好的one-hot编码与原数据合并
# 8.1 pd.concat实现数据合并
pd.concat([d1,du],axis=1)
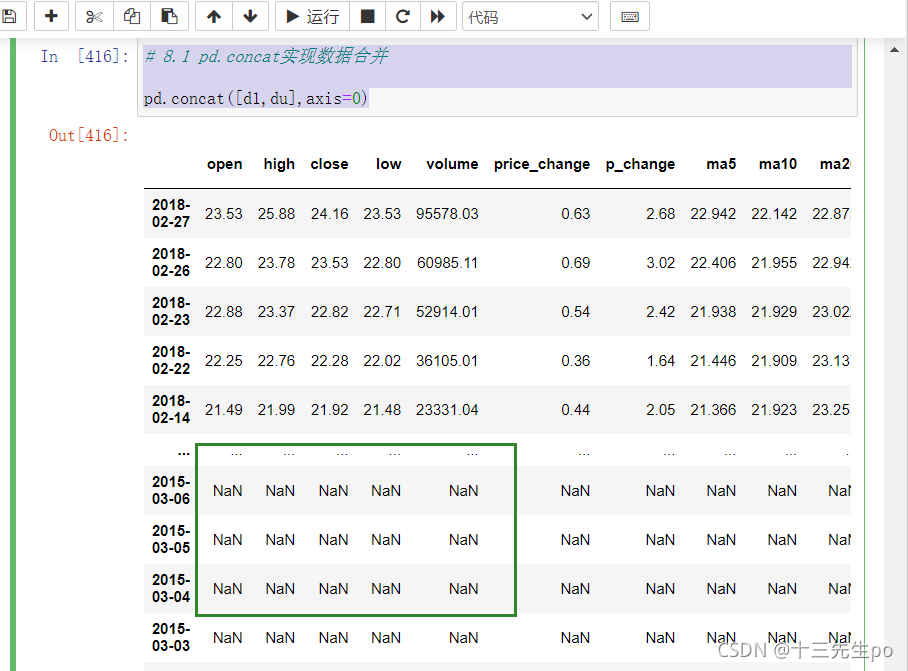
如果按列索引合并,可以发现有nan值
# 8.1 pd.concat实现数据合并
pd.concat([d1,du],axis=0)
8.2 pd.merge
- pd.merge(left, right, how=‘inner’, on=None, left_on=None, right_on=None,left_index=False,
right_index=False, sort=True,suffixes=(‘x’, ‘y’), copy=True, indicator=False,validate=None)- 可以指定按照两组数据的共同键值对合并或者左右各自
- left : A DataFrame object
- right : Another DataFrame object
- on : Columns (names) to join on. Must be found in both the left and right DataFrame objects.
- left_on=None, right_on=None:指定左右键

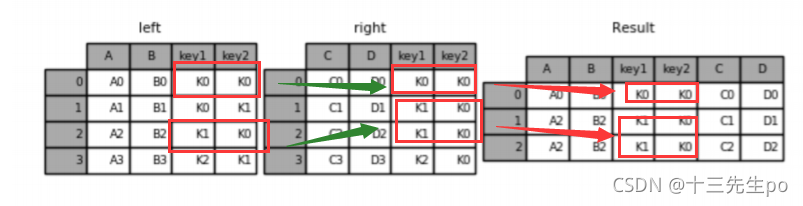
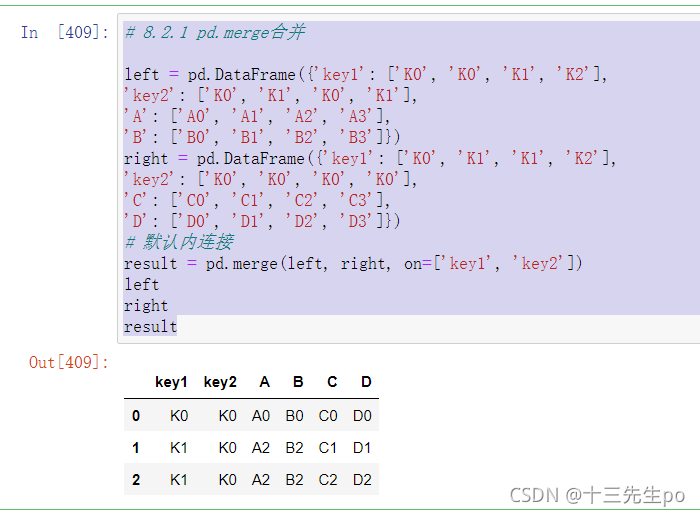
- 内连接(默认)
只有相同的才给你做连接
如图中left的key1,key2和right的两行关联了两次,就将left的这一行复制一次变成两行
# 8.2.1 pd.merge合并
left = pd.DataFrame({'key1': ['K0', 'K0', 'K1', 'K2'],
'key2': ['K0', 'K1', 'K0', 'K1'],
'A': ['A0', 'A1', 'A2', 'A3'],
'B': ['B0', 'B1', 'B2', 'B3']})
right = pd.DataFrame({'key1': ['K0', 'K1', 'K1', 'K2'],
'key2': ['K0', 'K0', 'K0', 'K0'],
'C': ['C0', 'C1', 'C2', 'C3'],
'D': ['D0', 'D1', 'D2', 'D3']})
# 默认内连接
result = pd.merge(left, right, on=['key1', 'key2'])
left
right
result
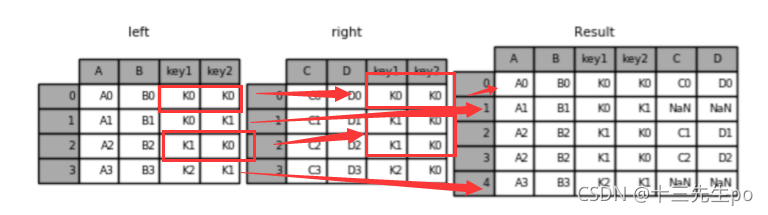
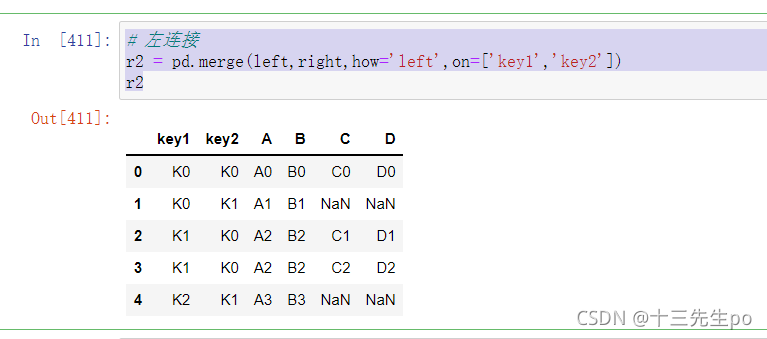
- 左连接
前者有的,后者必须要有,否则后者自行补齐(补nan值)
如图所示,第一行key值全部匹配直接合并,第二行key不匹配直接输出并补全nan值,第三行有两次相同的key值则复制一行填充
# 左连接
r2 = pd.merge(left,right,how='left',on=['key1','key2'])
r2
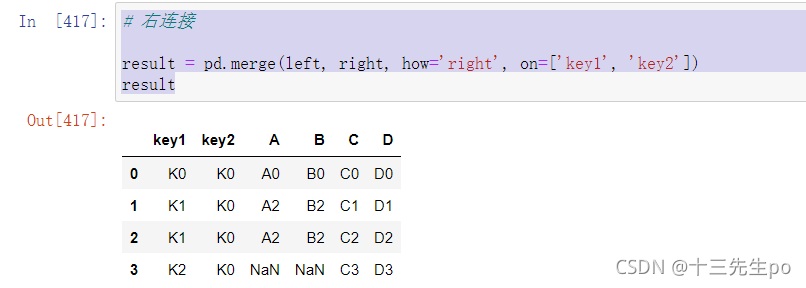
- 右连接
意思和左连接相反
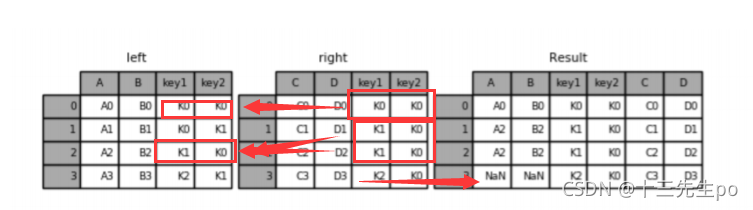
# 右连接
result = pd.merge(left, right, how='right', on=['key1', 'key2'])
result
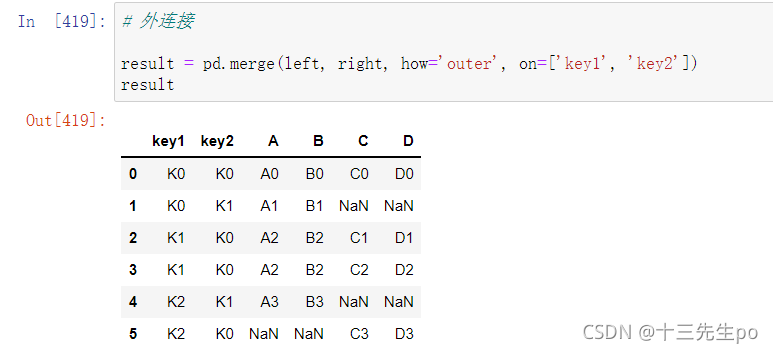
- 外链接
和内连接相反,但有一点不同的就是要所有数值都要有,匹配失败的地方用nan值补齐

# 外连接
result = pd.merge(left, right, how='outer', on=['key1', 'key2'])
result
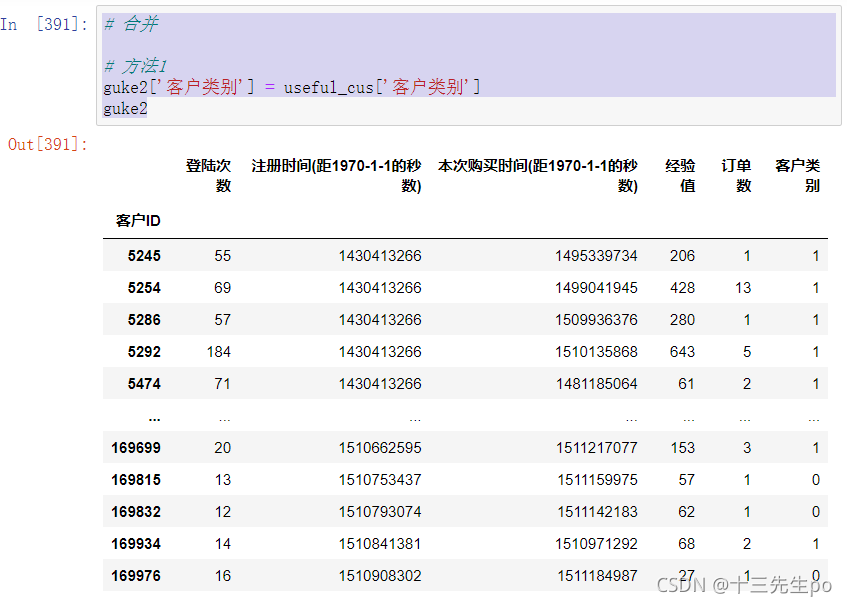
8.3 直接相等
直接相等,适用于索引项类型相同的情形
# 合并
# 方法1
guke2['客户类别'] = useful_cus['客户类别']
guke2
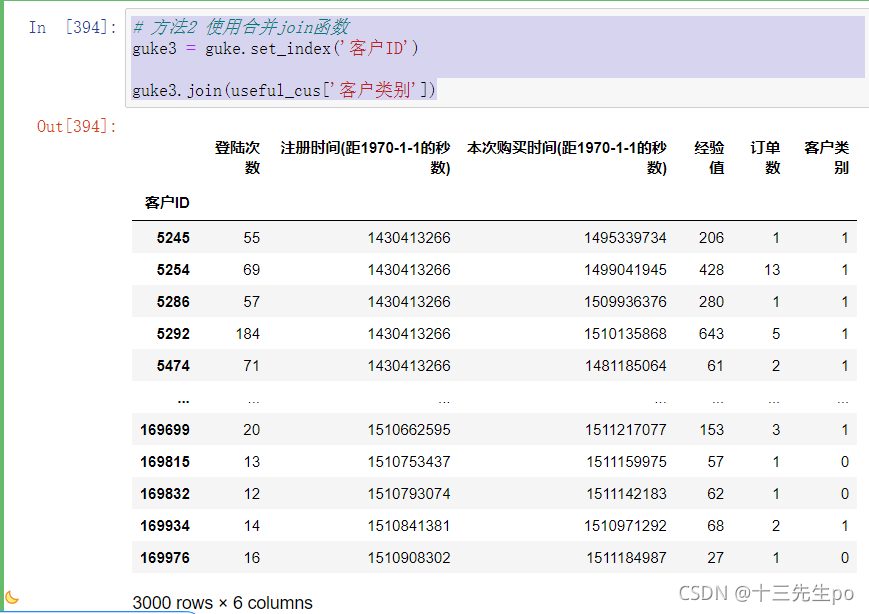
8.4 join方法
使用合并join函数
# 方法2 使用合并join函数
guke3 = guke.set_index('客户ID')
guke3.join(useful_cus['客户类别'])
8.5 总结
- concat进行按照索引的合并
- merge进行按照键合并
9 高级处理-交叉表与透视表
9.1 交叉表与透视表什么作用
探究股票的涨跌与星期几有关?
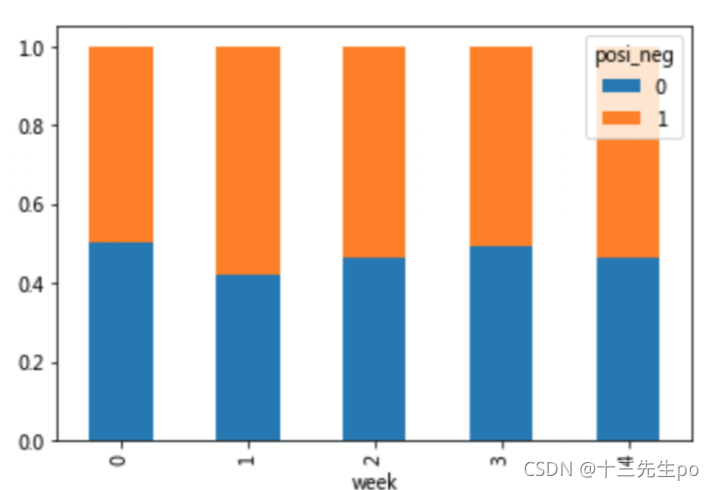
以下图当中表示,week代表星期几,1,0代表这一天股票的涨跌幅是好还是坏,里面的数据代表比例可以理解为所有时间为星期一等等的数据当中涨跌幅好坏的比例
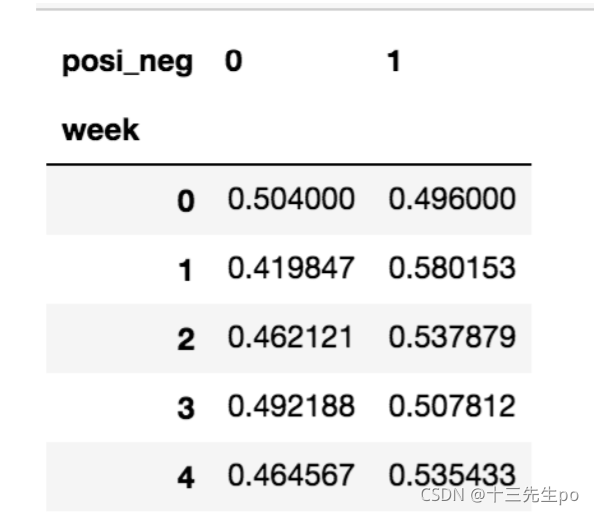
交叉表和透视表的区别
透视表是将原有的DataFrame的列分别作为行索引和列索引,然后对指定的列应用聚集函数
交叉表用于统计分组频率的特殊透视表
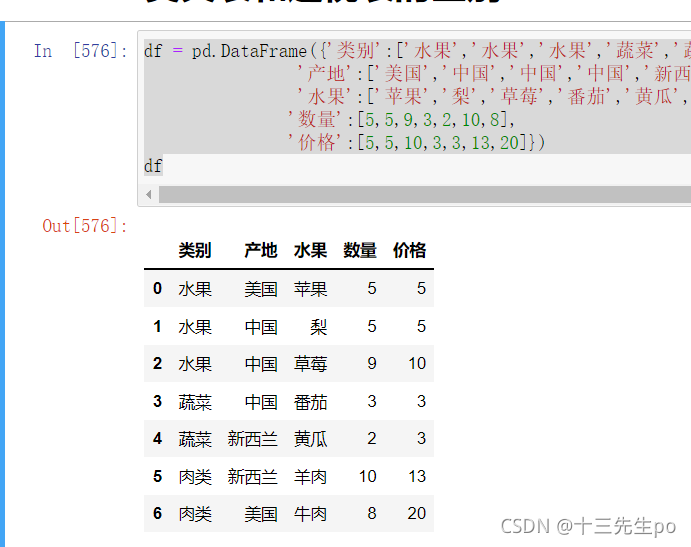
df = pd.DataFrame({'类别':['水果','水果','水果','蔬菜','蔬菜','肉类','肉类'],
'产地':['美国','中国','中国','中国','新西兰','新西兰','美国'],
'水果':['苹果','梨','草莓','番茄','黄瓜','羊肉','牛肉'],
'数量':[5,5,9,3,2,10,8],
'价格':[5,5,10,3,3,13,20]})
df
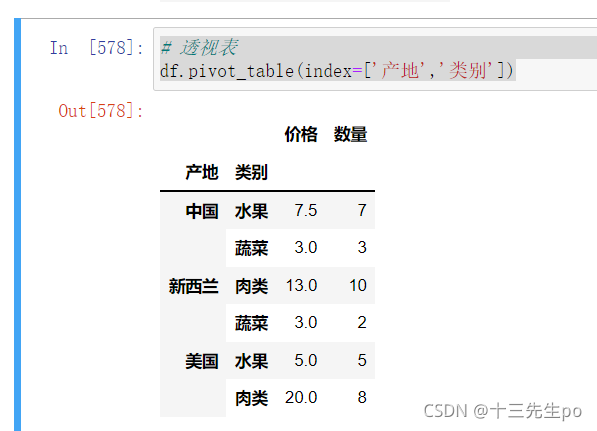
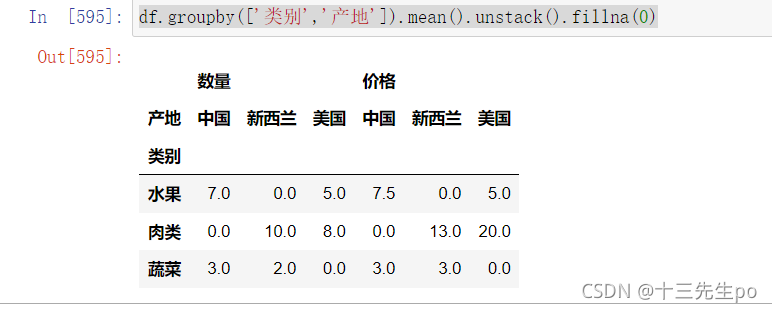
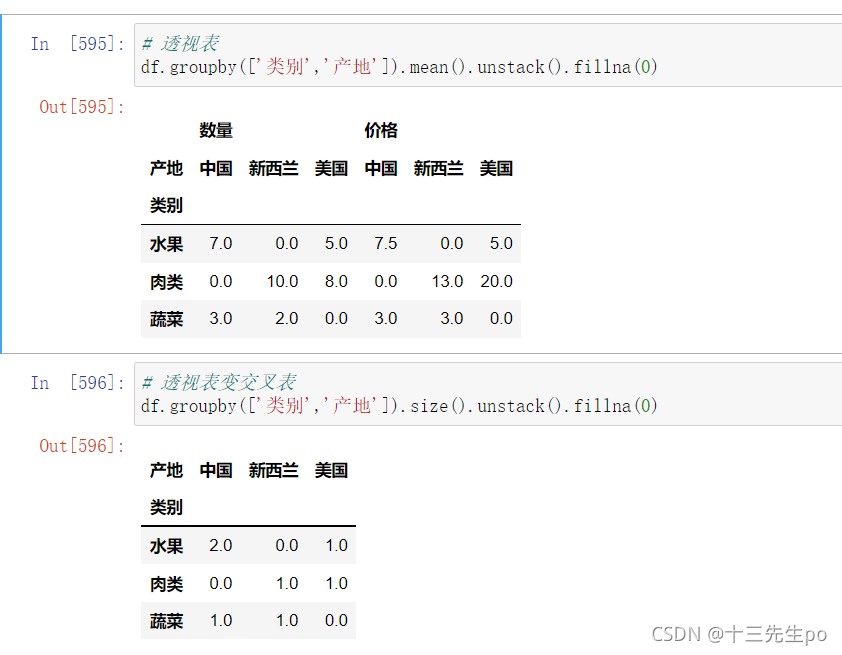
- 使用透视表
# 透视表
df.pivot_table(index=['产地','类别'])
- 使用交叉表
# 交叉表
pd.crosstab(df['类别'],df['产地'])

pd.crosstab(df['产地'],df['类别'])

透视表和交叉表的区别在代码上可能就是某个方法的转换,如mean()方法改成size()方法就是交叉表了
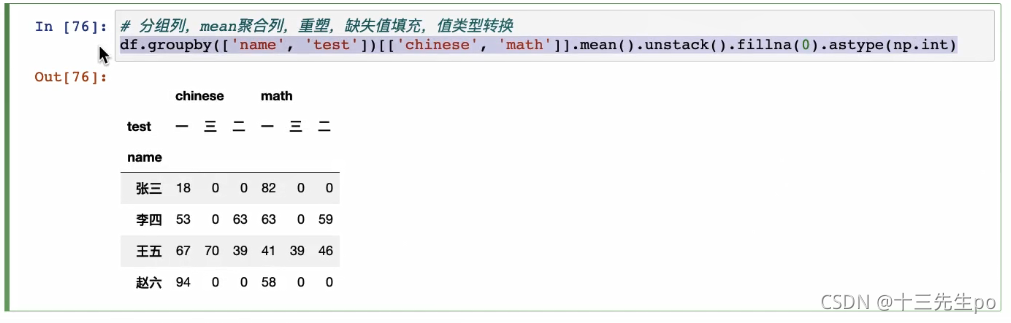
df.groupby(['类别','产地']).mean().unstack().fillna(0)
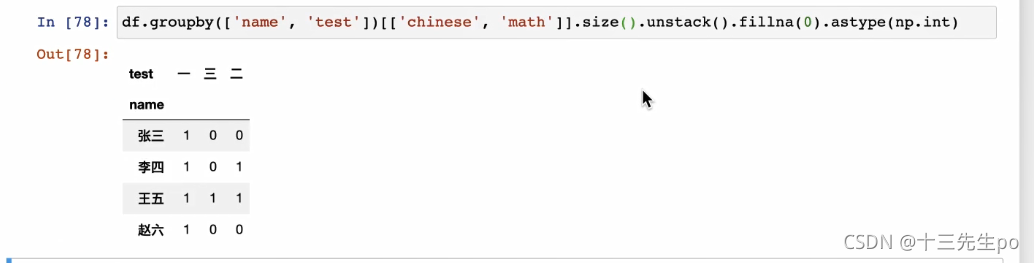
df.groupby(['类别','产地']).size().unstack().fillna(0)

交叉表就是用于统计分组频率的特殊透视表
9.2 使用crosstab(交叉表)实现上图
- 交叉表:
交叉表用于计算一列数据对于另外一列数据的分组个数(寻找两个列之间的关系),用于统计分组频率的特殊透视表- pd.crosstab(value1, value2)
- 透视表:
透视表是将原有的DataFrame的列分别作为行索引和列索引,然后对指定的列应用聚集函数- DataFrame.pivot_table([], index=[])
9.3 案例分析
所用数据如下
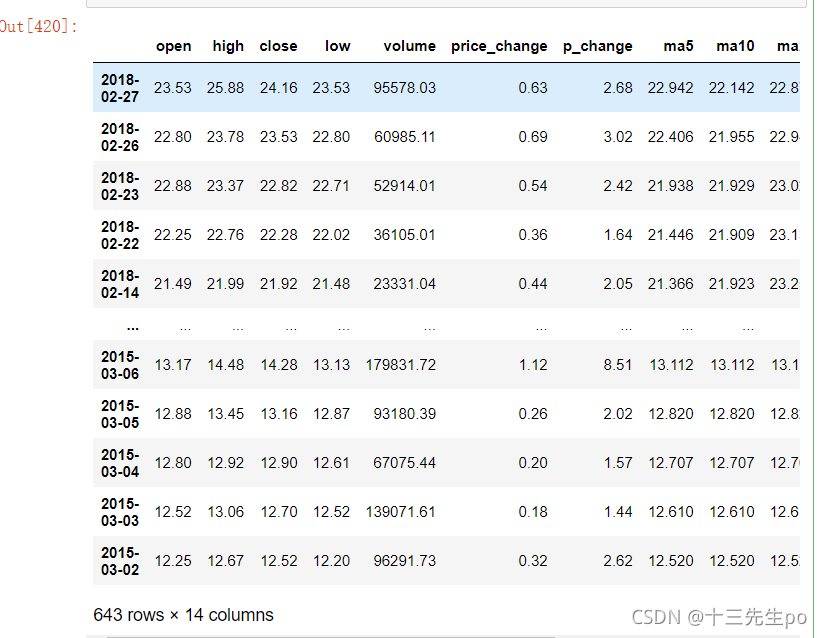
# 9.2 使用crosstab(交叉表)
# 寻找星期几跟股票涨跌的关系
import numpy as np
# 1、先根据对应的日期找到星期几
date = pd.to_datetime(d1.index).weekday
# 创建新列加入周值
d1['week'] =date
# 2、把p_change按照大小分类,以0为界限
# 查看每一列的数据类型
type(d1['p_change']) # pandas.core.series.Series
# pandas的数据也可以使用numpy的三元运算
d1['p_judge'] = np.where(d1['p_change']>0,1,0)
# 通过交叉表找寻两列数据的关系
count = pd.crosstab(d1['week'],d1['p_judge'])
count
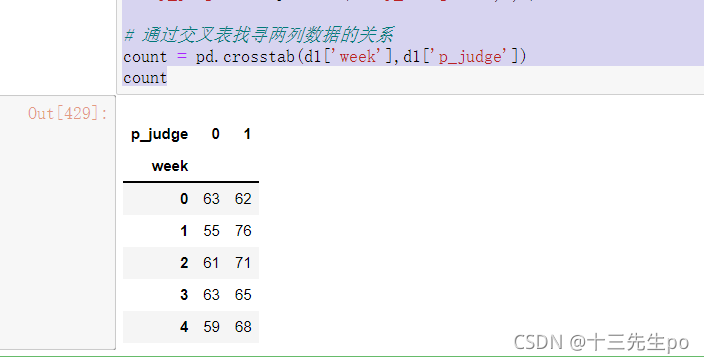
但是我们看到count只是每个星期日子的好坏天数,并没有得到比例,该怎么去做?
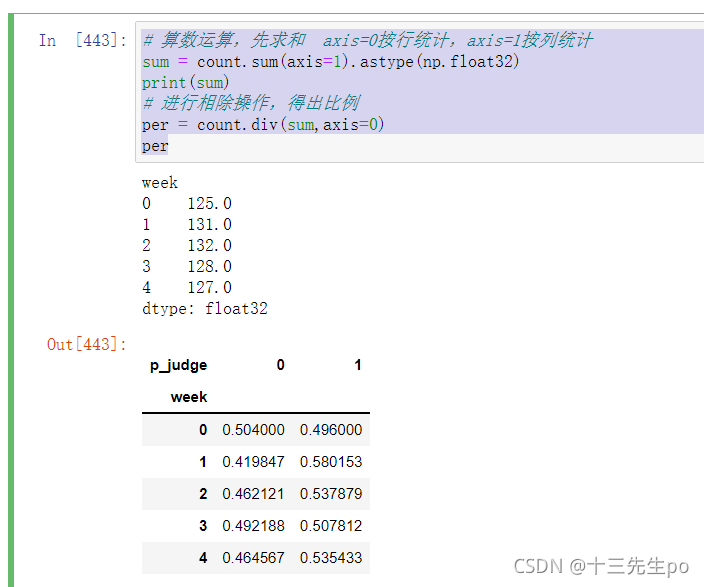
- 对于每个星期一等的总天数求和,运用除法运算求出比例
# 算数运算,先求和 axis=0按行统计,axis=1按列统计
sum = count.sum(axis=1).astype(np.float32)
print(sum)
# 进行相除操作,得出比例
per = count.div(sum,axis=0)
per
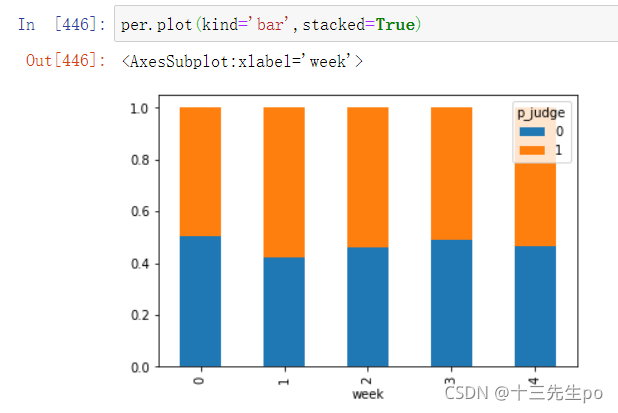
9.3.2 查看效果
使用plot画出这个比例,使用stacked的柱状图
per.plot(kind='bar',stacked=True)
9.3.3 使用pivot_table(透视表)实现
使用透视表,刚才的过程更加简单
它根据一个或多个键对数据进行聚合,并根据行和列上的分组键将数据分配到各个矩形区域中
- pd.pivot_table([‘单独查询的列’],index=‘索引项’,columns=‘行值’,fill_value=0,aggfunc=len)
- fill_value=0 令所有空值为0
- aggfunc=0 起到计数(计算频率)作用,不写这一行只记录了是否有出现过这种情况或者记录第一次检索到的值?
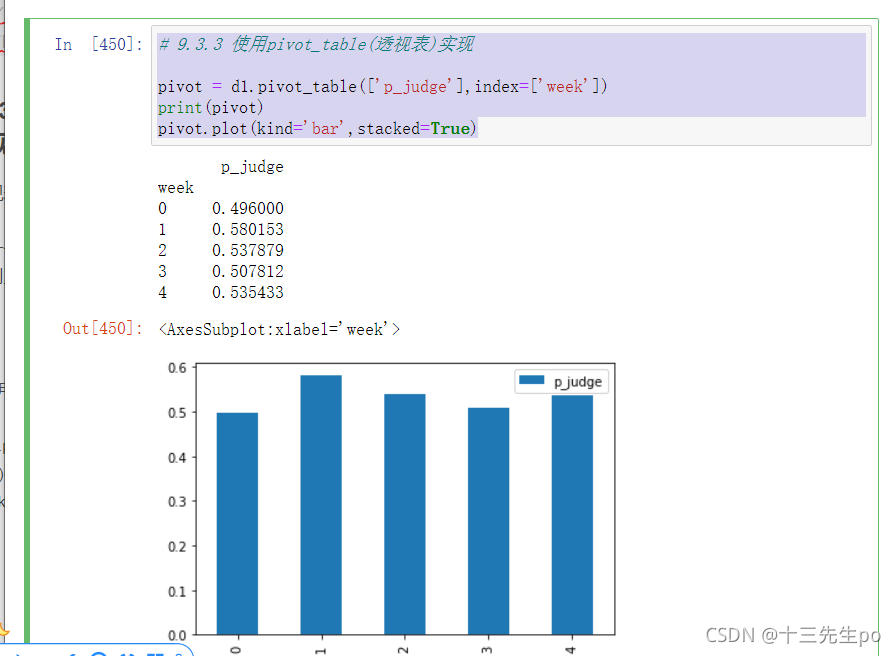
# 9.3.3 使用pivot_table(透视表)实现
pivot = d1.pivot_table(['p_judge'],index=['week'])
print(pivot)
pivot.plot(kind='bar',stacked=True)
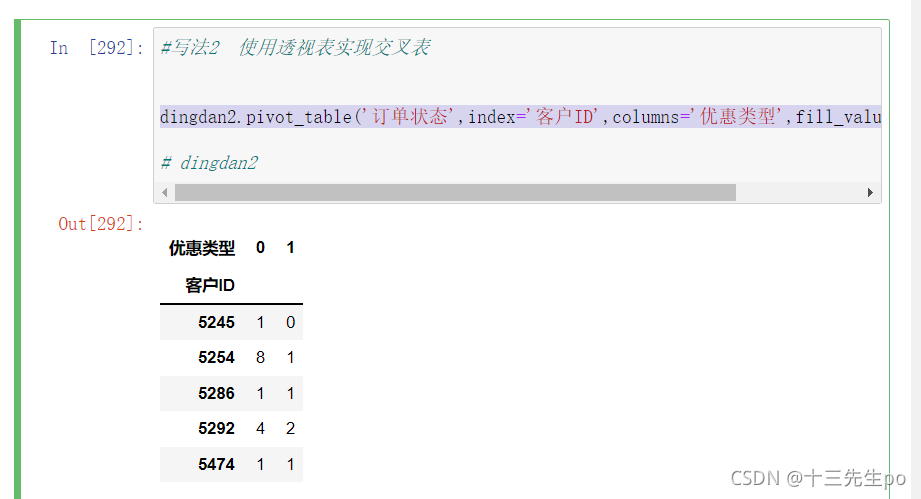
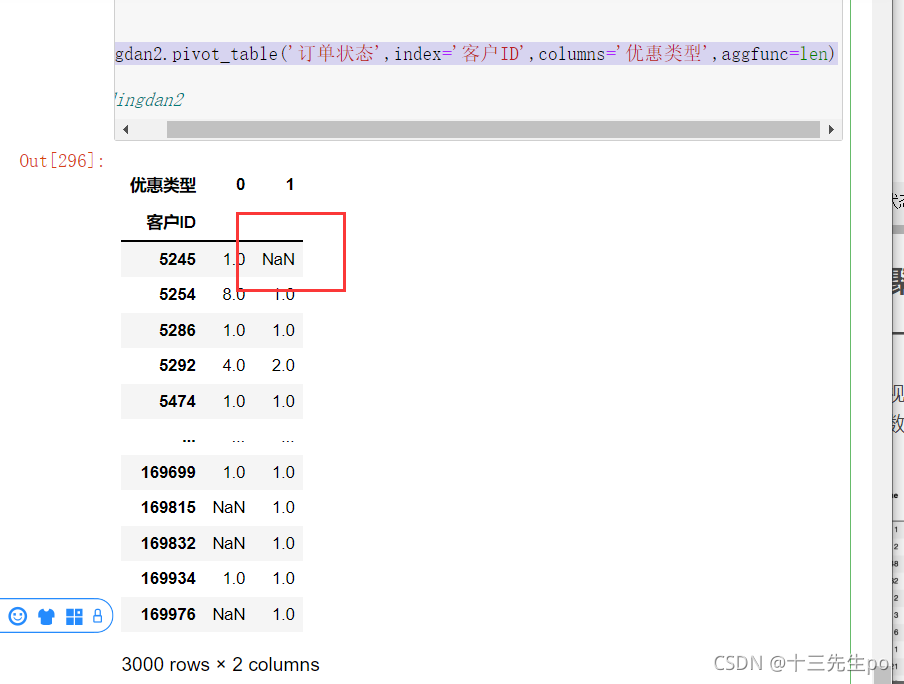
dingdan2.pivot_table('订单状态',index='客户ID',columns='优惠类型',fill_value=0,aggfunc=len)
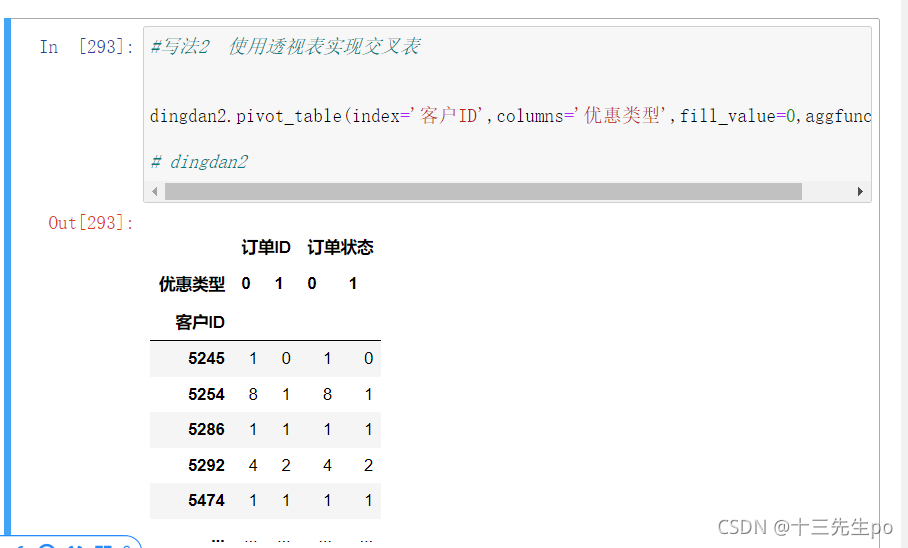
- 区别一下不同写法时输出的pandas值
- 没有[‘单独查询的列’]
dingdan2.pivot_table(index='客户ID',columns='优惠类型',fill_value=0,aggfunc=len)
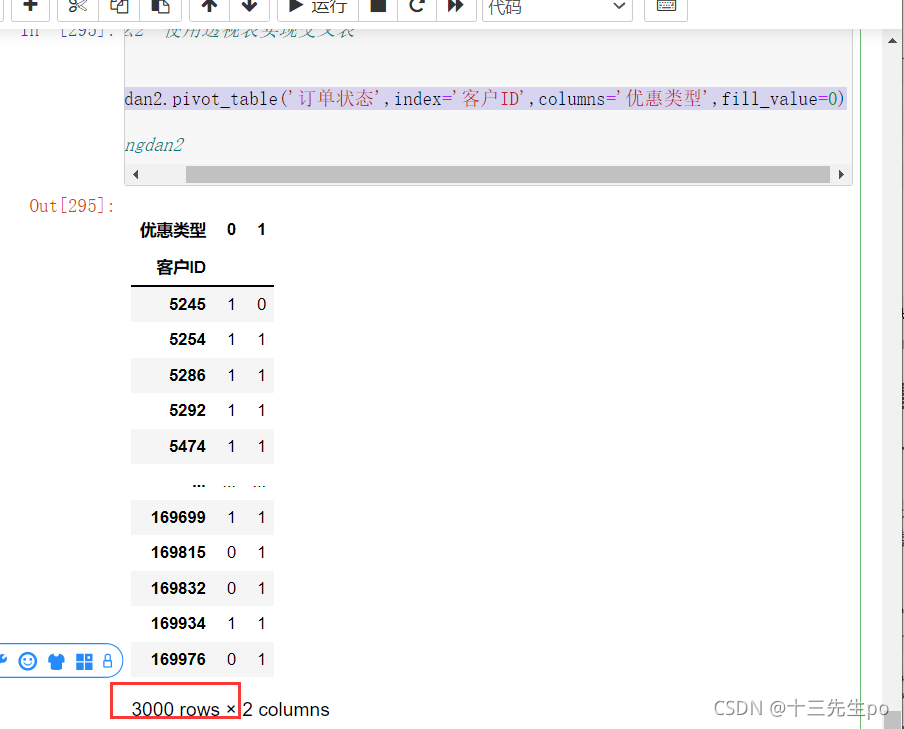
- 没有aggfunc=len
dingdan2.pivot_table('订单状态',index='客户ID',columns='优惠类型',fill_value=0)
行数没有变化,但是只记录了是否有出现过0或者1的情况,并非计数
- 没有fill_value = 0
dingdan2.pivot_table('订单状态',index='客户ID',columns='优惠类型',aggfunc=len)
10 高级处理-分组与聚合
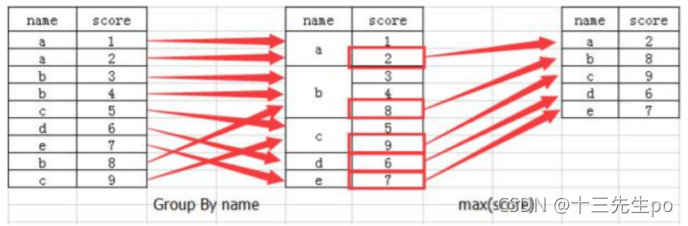
分组与聚合通常是分析数据的一种方式,通常与一些统计函数一起使用,查看数据的分组情况
想一想其实刚才的交叉表与透视表也有分组的功能,所以算是分组的一种形式,只不过他们主要是计算次数或者计算比例!!看其中的效果:
10.1 什么是分组与聚合
10.2 分组API
- DataFrame.groupby(key, as_index=False)
- key:分组的列数据,可以多个
groupby下的方法
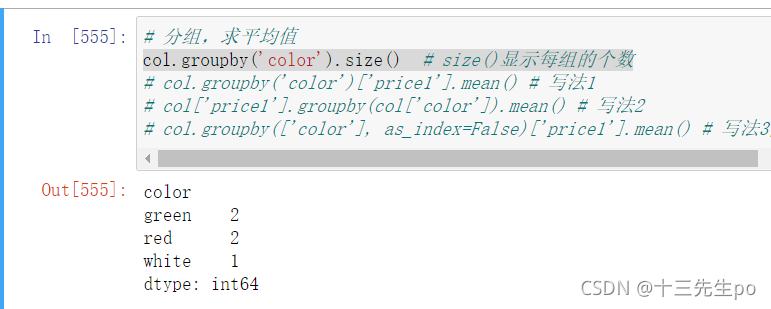
- size() 显示个数,可用于直接求交叉表
col.groupby('color').size() # size()显示每组的个数
- count() 显示聚合计数
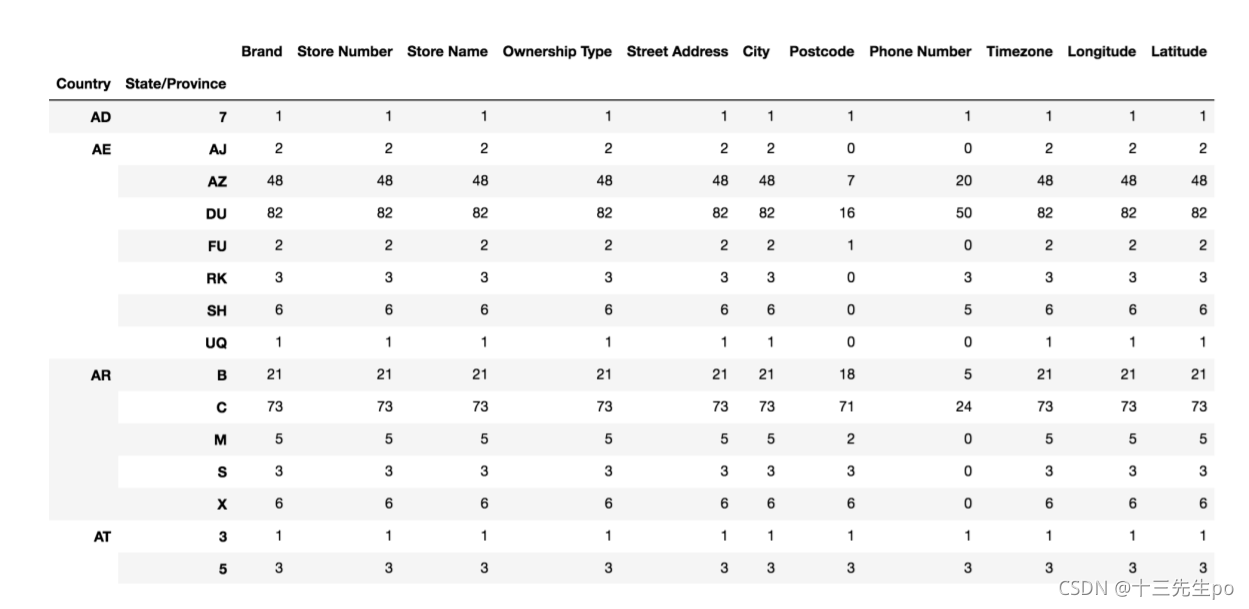
stbuck.groupby(['Country','State/Province']).count()
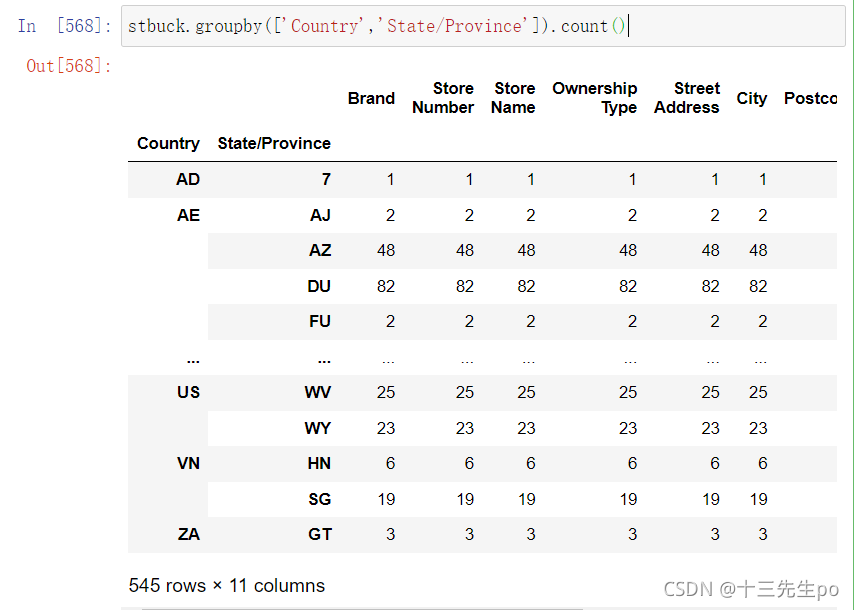
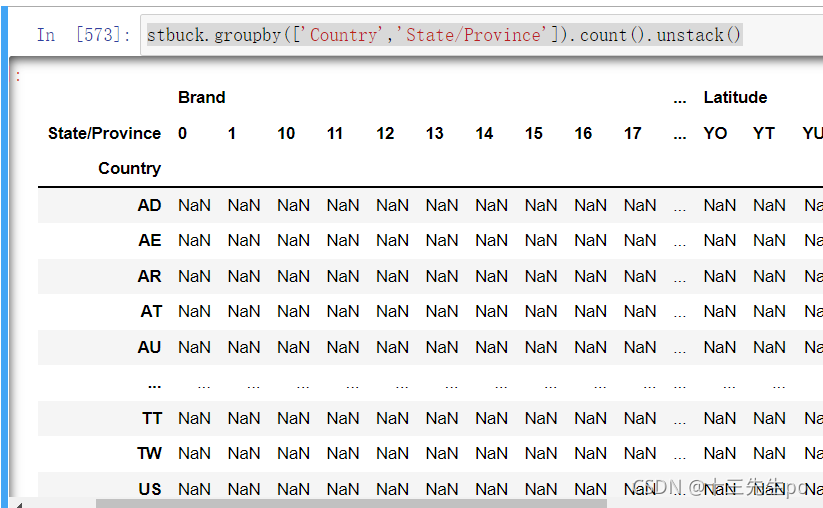
- 方法.unstank() 旋转显示
stbuck.groupby(['Country','State/Province']).count().unstack()
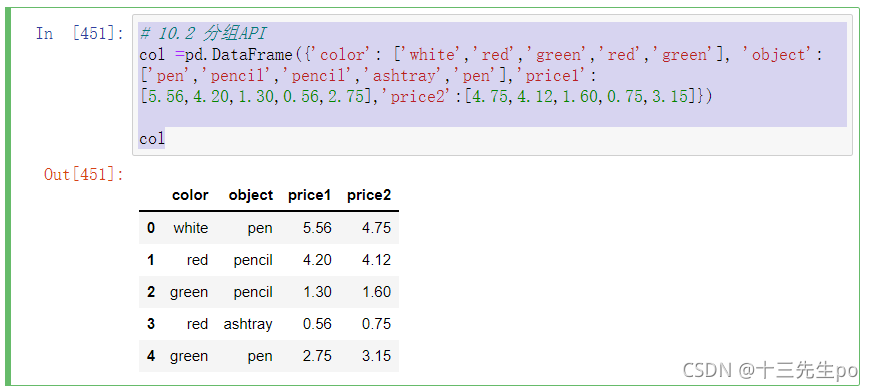
案例:不同颜色的不同笔的价格数据
# 10.2 分组API
col =pd.DataFrame({'color': ['white','red','green','red','green'], 'object':
['pen','pencil','pencil','ashtray','pen'],'price1':
[5.56,4.20,1.30,0.56,2.75],'price2':[4.75,4.12,1.60,0.75,3.15]})
col
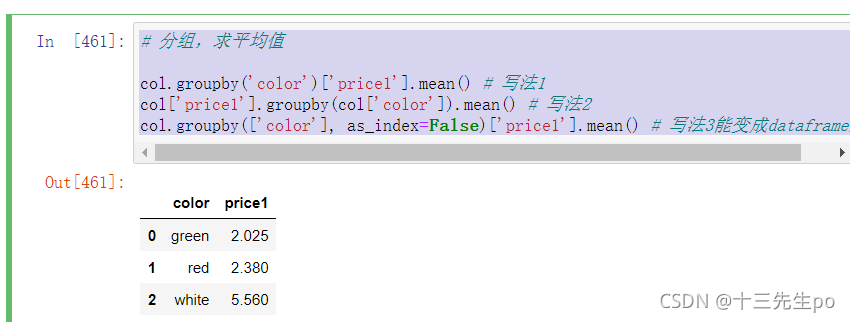
- 进行分组,对颜色分组,price进行聚合
# 分组,求平均值
col.groupby('color')['price1'].mean() # 写法1
col['price1'].groupby(col['color']).mean() # 写法2
col.groupby(['color'], as_index=False)['price1'].mean() # 写法3能变成dataframe结构
10.3 星巴克零售店铺数据
现在我们有一组关于全球星巴克店铺的统计数据,如果我想知道美国的星巴克数量和中国的哪个多,或者我想知道中国每个省份星巴克的数量的情况,那么应该怎么办?
数据来源:https://www.kaggle.com/starbucks/store-locations/data
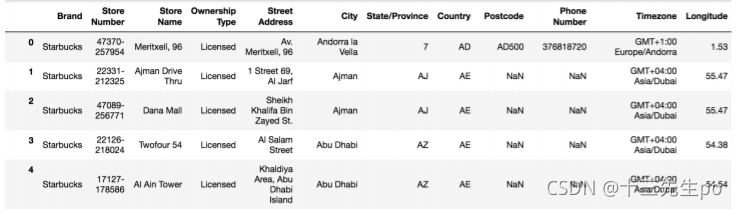
10.3.1 数据获取
# 10.3 星巴克零售店铺数据
# 导入星巴克店的数据
stbuck = pd.read_csv('directory.csv')
stbuck
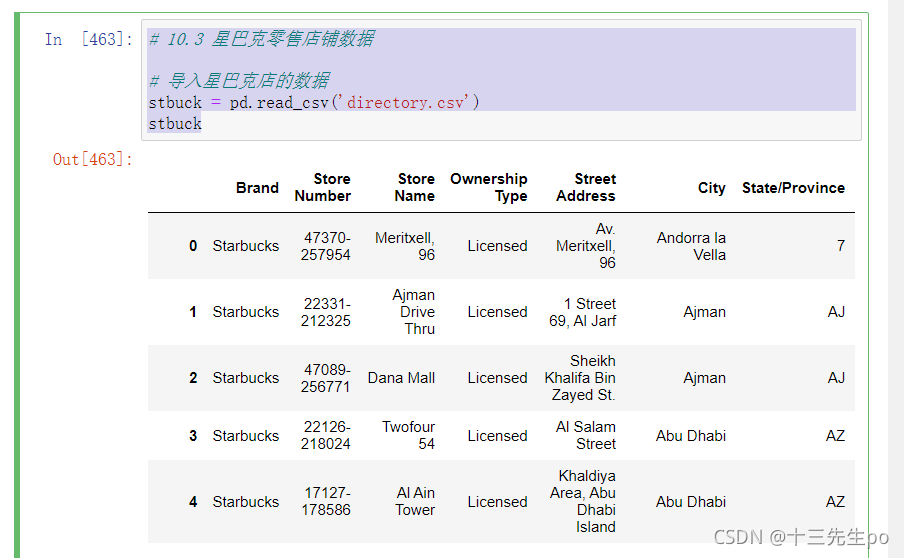
10.3.2 进行分组聚合
# 按照国家分组,求出每个国家的星巴克零售店数量
country = stbuck.groupby(['Country']).count()
# country
# 画图显示结果
country['Brand'].plot(kind='bar',figsize=(20,8))
plt.show()
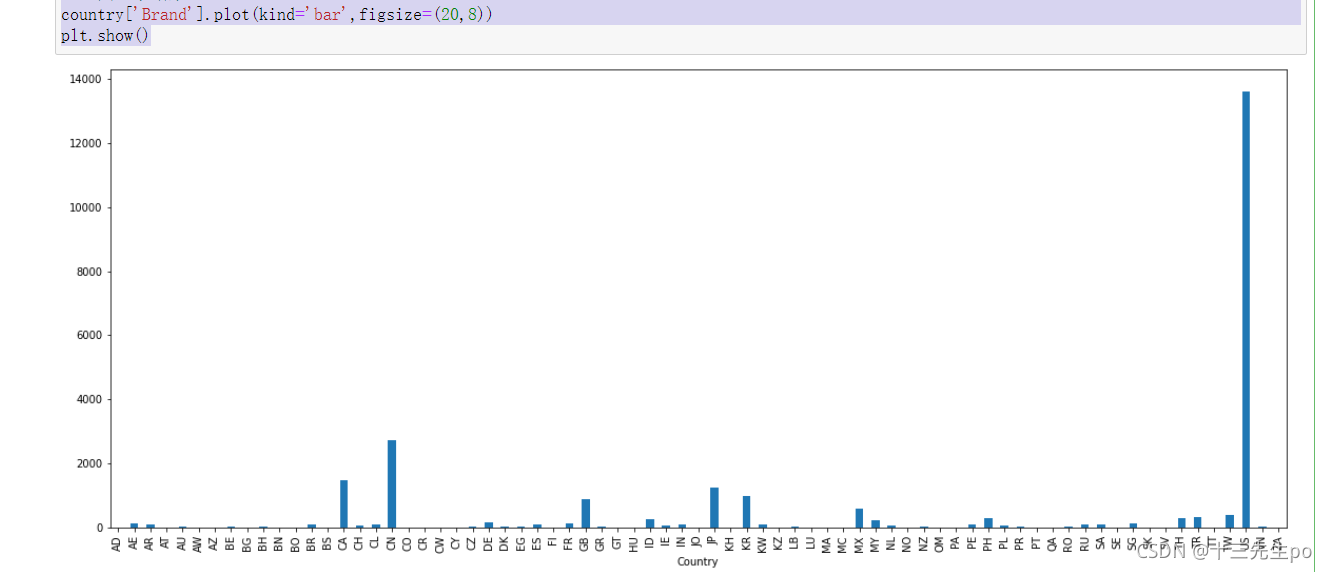
设置多个索引
- 假设我们加入省市一起进行分组
# 10.3 星巴克零售店铺数据
# 假设我们加入省市一起进行分组
# 设置多个索引
stbuck.groupby(['Country','State/Province']).count()
11 综合案例:电影数据
11.1 需求
现在我们有一组从2006年到2016年1000部最流行的电影数据,数据来源(可能没用了):https://www.kaggle.com/d
amianpanek/sunday-eda/data
- 问题1:我们想知道这些电影数据中评分的平均分,导演的人数等信息,我们应该怎么获取?
- 问题2:对于这一组电影数据,如果我们想rating,runtime的分布情况,应该如何呈现数据?
- 问题3:对于这一组电影数据,如果我们希望统计电影分类(genre)的情况,应该如何处理数据?
11.2 实现
- 获取数据
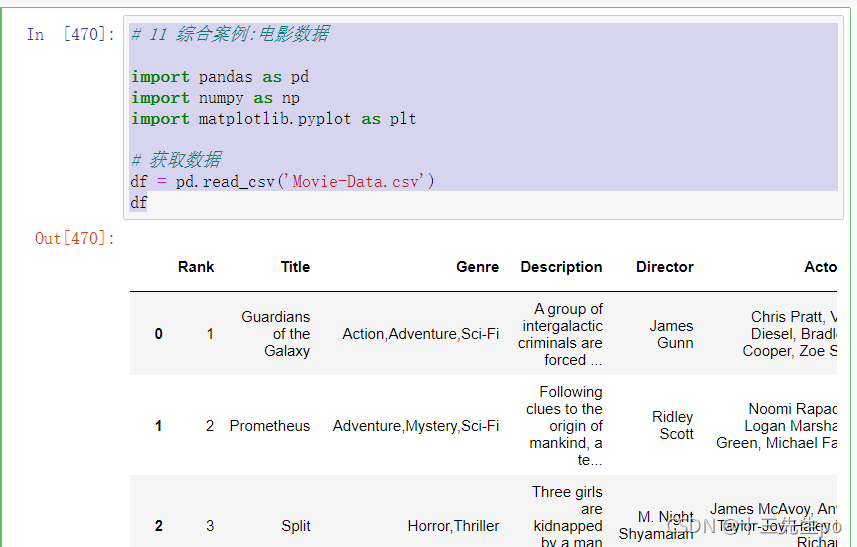
# 11 综合案例:电影数据
import pandas as pd
import numpy as np
import matplotlib.pyplot as plt
# 获取数据
df = pd.read_csv('Movie-Data.csv')
df
11.2.1 电影数据中评分的平均分,导演的人数等信息
pandas模块和numpy模块可以综合使用解决问题,例如numpy的unique去重方法、shape方法
# 11 综合案例:电影数据
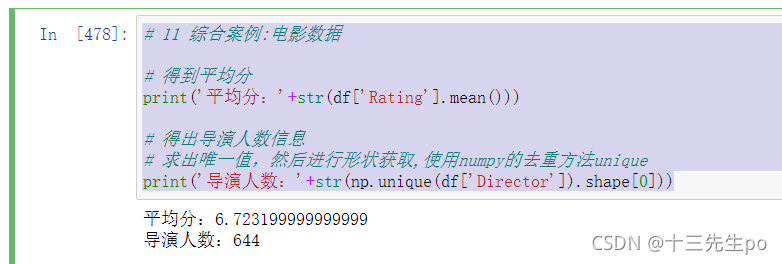
# 得到平均分
print('平均分:'+str(df['Rating'].mean()))
# 得出导演人数信息
# 求出唯一值,然后进行形状获取,使用numpy的去重方法unique
print('导演人数:'+str(np.unique(df['Director']).shape[0]))
11.2.2 Rating,Runtime (Minutes)的分布情况
- 以直方图的形式直接呈现
选择分数列数据,进行plot
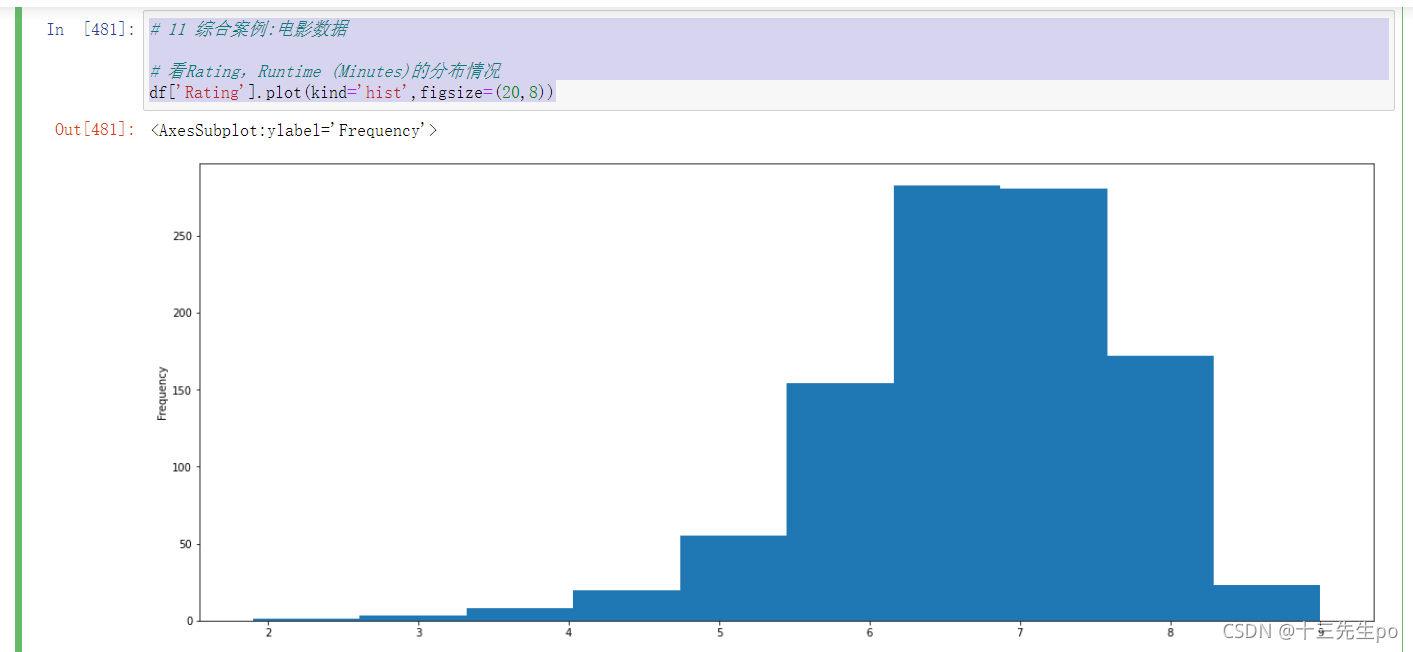
# 11 综合案例:电影数据
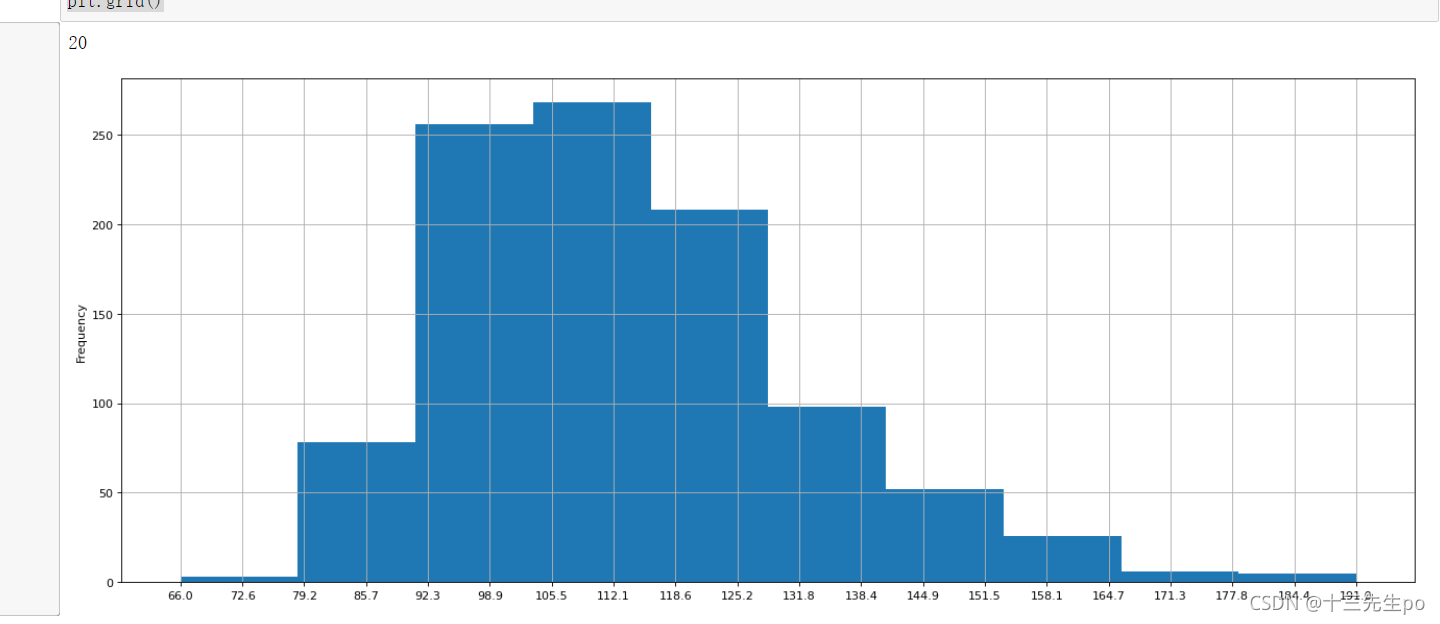
# 看Rating,Runtime (Minutes)的分布情况
df['Rating'].plot(kind='hist',figsize=(20,8))
- Rating 分布展示
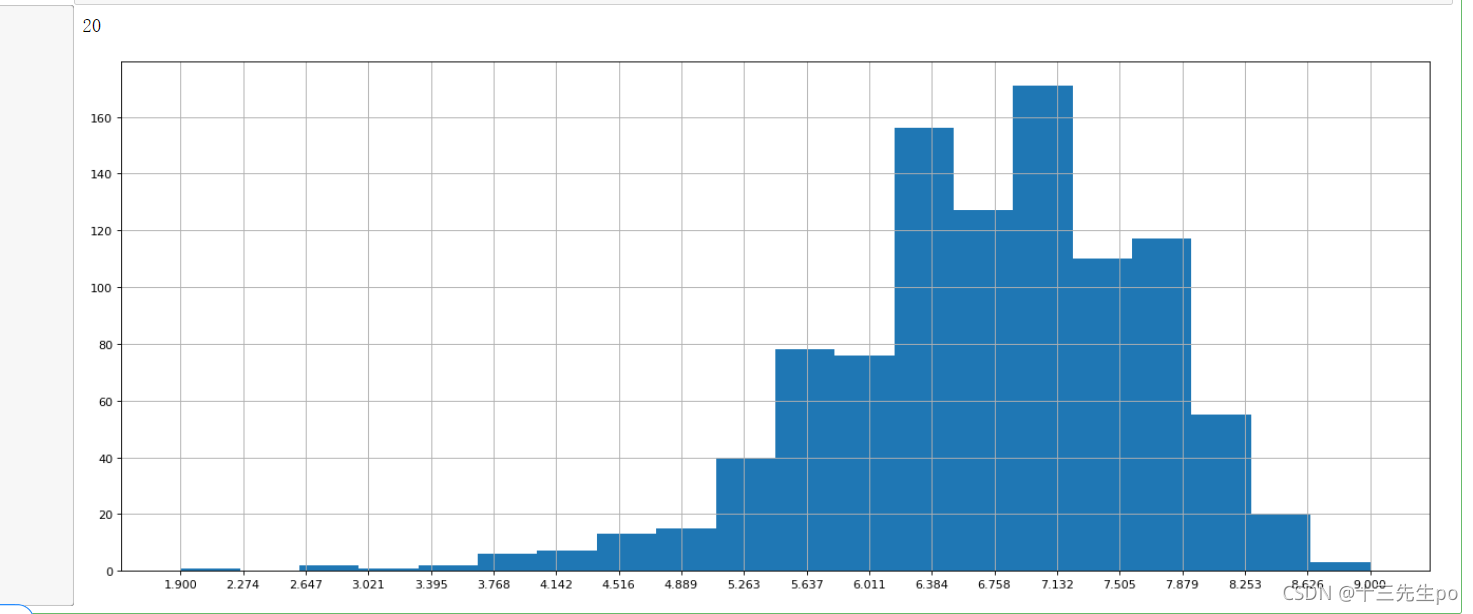
# Rating进行分布展示
# 提取Rating列
# df['Rating']
# 提取rating列的所有数值
# df['Rating'].values
# 绘制直方图
plt.figure(figsize=(20,8),dpi=80)
plt.hist(df['Rating'].values,bins=20)
# 辅助显示
# 修改刻度的间隔
# 求出最大最小值
max_s = df['Rating'].max()
min_s = df['Rating'].min()
# 生成刻度列表
t1 = np.linspace(min_s,max_s,num=20)
print(len(t1))
# 修改刻度
plt.xticks(t1)
# 添加网格
plt.grid()
- Runtime (Minutes)进行分布展示,一样的做法
# Runtime (Minutes)进行分布展示
plt.figure(figsize=(20,8),dpi=80)
df['Runtime (Minutes)'].plot(kind='hist',figsize=(20,8))
# 辅助显示
# 修改刻度的间隔
# 求出最大最小值
max_s = df['Runtime (Minutes)'].max()
min_s = df['Runtime (Minutes)'].min()
# 生成刻度列表
t1 = np.linspace(min_s,max_s,num=20)
print(len(t1))
# 修改刻度
plt.xticks(t1)
# 添加网格
plt.grid()
11.2.3 统计电影分类(genre)的情况
思路分析
- 思路
- 1、创建一个全为0的dataframe,列索引置为电影的分类
- 2、遍历每一部电影,gen_df中把分类出现的列的值置为1
- 3、求和
1、创建一个全为0的dataframe,列索引置为电影的分类
# 11.2.3 统计电影分类(genre)的情况
# 每一部电影的分类可能并非单一
# for i in df['Genre']:
# print(i)
# 进行字符串分割
temp_list = [i.split(',') for i in df['Genre']]
# for i in temp_list:
# print(i)
# 获取电影的分类,遍历种类中的每一个值,
# 放进一个新列表里面,并进行np.unique区中,得到了所有的种类
# for i in temp_list:
# for j in i:
# print(j)
gen_list = np.unique([j for i in temp_list for j in i])
gen_list
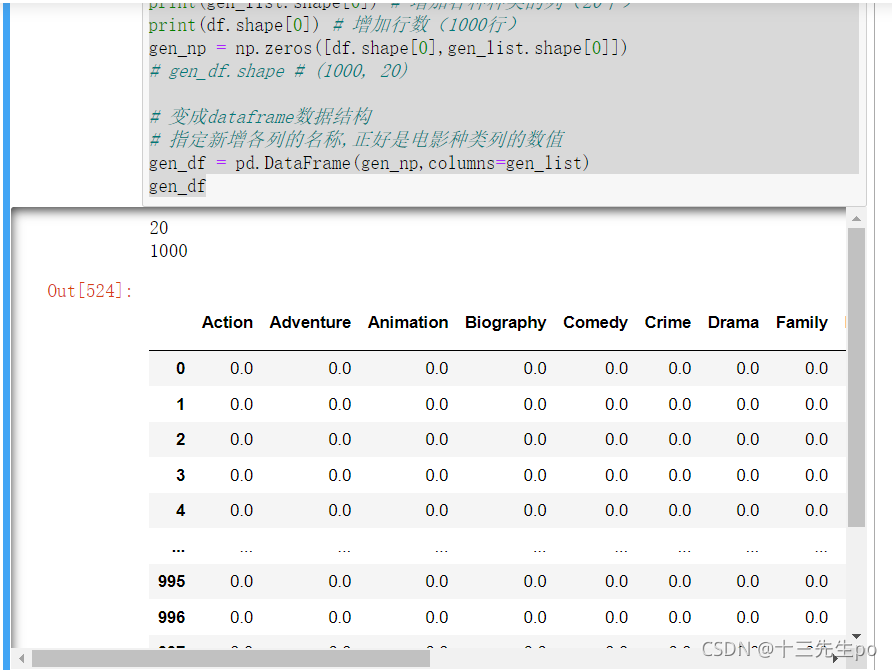
# 在原来的dataframe数据df中增加新的列,使用np.zeros方法生成0和1的数组
print(gen_list.shape[0]) # 增加各种种类的列(20个)
print(df.shape[0]) # 增加行数(1000行)
gen_np = np.zeros([df.shape[0],gen_list.shape[0]])
# gen_df.shape # (1000, 20)
# 变成dataframe数据结构
# 指定新增各列的名称,正好是电影种类列的数值
gen_df = pd.DataFrame(gen_np,columns=gen_list)
gen_df
2、遍历每一部电影,gen_df中把分类出现的列的值置为1
分析匹配的方法
- temp_list中有电影的种类标签,和gen_df的长度是对应的
- 用temp_list的行标签,gen_df的列标签来匹配到对应的种类
- 使用pd.loc方法匹配行数和列的名称,注意不要使用iloc方法,iloc方法是用来匹配列的位置下标
# 2、遍历每一部电影,temp_df中把分类出现的列的值置为1
# 2.1 temp_list中有电影的种类标签,和gen_df的长度是对应的
# temp_list
# 2.2 使用temp_list的行标签,gen_df的列标签来匹配到对应的种类
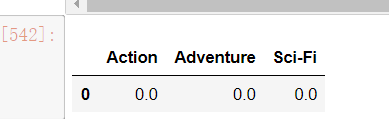
# 使用pd.loc方法匹配行数和列的名称,注意不要使用iloc方法,iloc方法是用来匹配列的位置下标
temp_list[0] # ['Action', 'Adventure', 'Sci-Fi']
gen_df.loc[[0],temp_list[0]]
- 遍历赋值
# 遍历赋值
for i in range(df.shape[0]):
gen_df.loc[[i],temp_list[i]] = 1
# gen_df
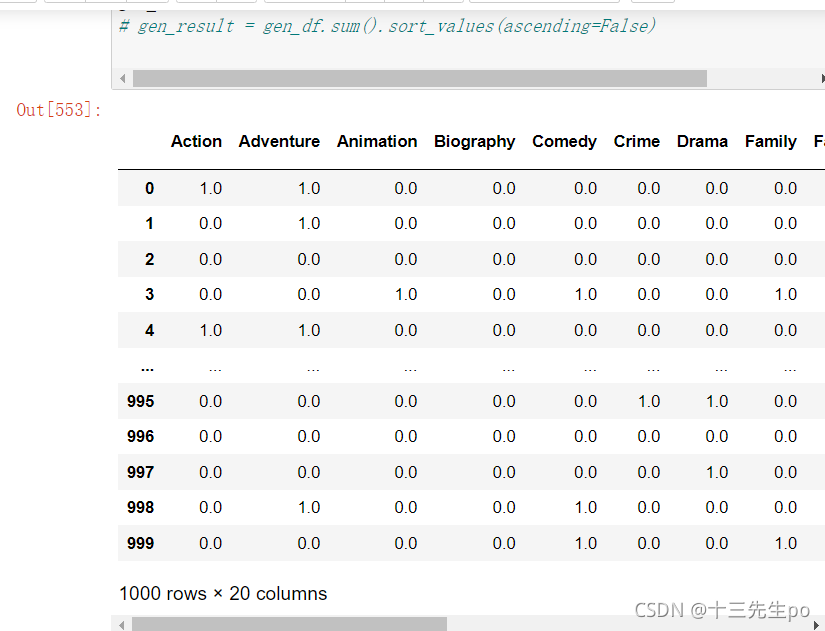
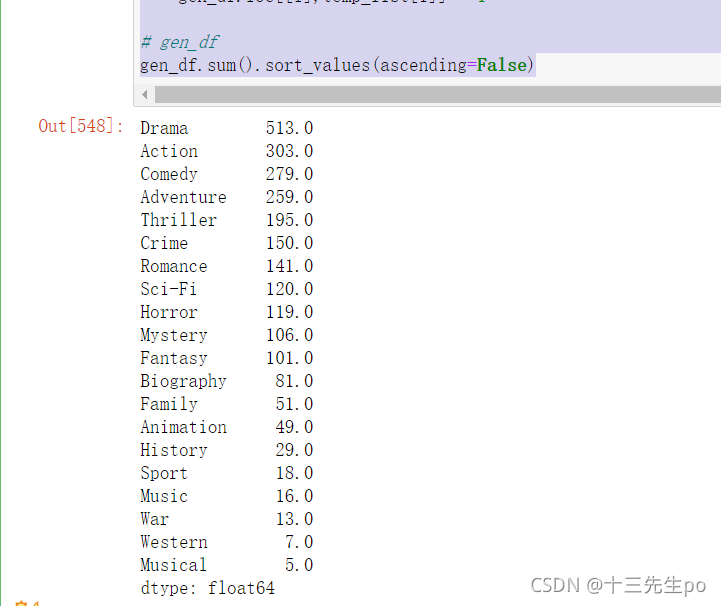
3、求和
# gen_df
# 求和并排序
gen_result = gen_df.sum().sort_values(ascending=False)
# 画图显示
gen_result.plot(kind='bar',figsize=(20,8),fontsize=20,colormap='cool')
