文章目录
一 车牌区域检测
1.1 数据集处理及相关文件准备
1.1.1 数据集准备
使用LabelImg工具标注接近578张.jpg图片(以carNO为主,标注3类:car、carNO、person)后,为了增加样本的多样性,在578张图片中挑选几十张图片进行高斯模糊、旋转、畸变、高斯噪声等操作,对新得到的图片进行标注,最终样本扩充到了713张图片。
数据集存放参照Pascal VOC2007数据目录(数据存放在VOCdevkit/VOC2007目录下):
–VOCdevkit
–VOC2007
–JPEGImages
–存储批量.jpg图片
–ImageSets
–Main
–train.txt,训练集图片名称(不带后缀.jpg,一行一个,随机643个)
–val.txt,测试集图片名称(不带后缀.jpg,一行一个,随机70个)
–Annotations
–存储批量标注.xml文件
数据集存储目录情况如上所示,其中JPEGImages文件夹存放所有图片;ImageSets文件夹下有一个Main文件夹,Main下面存放train.txt和val.txt,分别为训练、测试集的图片名称(不带后缀.jpg,一行一个),需提前准备;Annotations文件夹存放图片标注.xml文件。
1.1.2 相关文件准备
- 创建datasetcarmore文件夹
# cd /home/users/py3_project/models/research/object_detection # 程序全部在此目录下运行,root用户,防止权限问题
# mkdir datasetcarmore
- 将准备好的VOCdevkit/VOC2007数据集,放到datasetcarmore目录下
- 复制models\research\object_detection\datasetcarmore_tools\create_pascal_tf_record.py文件到datasetcarmore目录下
- 复制models\research\object_detection\data\pascal_label_map.pbtxt文件到datasetcarmore目录下
- 复制models\research\object_detection\samples\configs\ ssd_mobilenet_v1_pets.config到datasetcarmore目录下
1.2. 转换数据集为tf_record格式
- 将datasetcarmore/pascal_label_map.pbtxt改为自己的标签,如下所示

- 修改datasetcarmore/create_pascal_tf_record.py第160行 :

- 在当前目录/home/users/py3_project/models/research/object_detection下,
执行以下命令:
# mkdir datasetcarmore/image_tfrecord
# python3 datasetcarmore/create_pascal_tf_record.py \
--data_dir=datasetcarmore/VOCdevkit \
--label_map_path=datasetcarmore/pascal_label_map.pbtxt \
--year=VOC2007 \
--set=train \
--output_path=datasetcarmore/image_tfrecord/pascal_train.record
# python3 datasetcarmore/create_pascal_tf_record.py \
--data_dir=datasetcarmore/VOCdevkit \
--label_map_path=datasetcarmore/pascal_label_map.pbtxt \
--year=VOC2007 \
--set=val \
--output_path=datasetcarmore/image_tfrecord/pascal_val.record
1.3 下载预训练模型
# wget http://download.tensorflow.org/models/object_detection/ssd_mobilenet_v1_coco_11_06_2017.tar.gz
# tar -xvf ssd_mobilenet_v1_coco_11_06_2017.tar.gz
将解压好的预训练模型目录重命名为model_ssd,存入datasetcarmore目录下
1.4 修改相关配置文件
1 修改配置文件:
datasetcarmore目录下的ssd_mobilenet_v1_pets.config重命名为ssd_mobilenet_v1_pascal.config
- 修改类别数
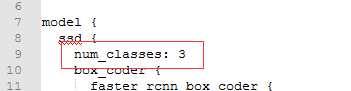
- 修改预训练模型路径
fine_tune_checkpoint: “/home/users/py3_project/models/research/object_detection/datasetcarmore/model_ssd/model.ckpt” - 修改输入训练数据配置信息
train_input_reader: {
tf_record_input_reader {
input_path: “/home/users/py3_project/models/research/object_detection/datasetcarmore/image_tfrecord/pascal_train.record”
}
label_map_path: “/home/users/py3_project/models/research/object_detection/datasetcarmore/pascal_label_map.pbtxt”
} - 修改预测数据配置信息
eval_input_reader: {
tf_record_input_reader {
input_path: “/home/users/py3_project/models/research/object_detection/datasetcarmore/image_tfrecord/pascal_val.record”
}
label_map_path: “/home/users/py3_project/models/research/object_detection/datasetcarmore/pascal_label_map.pbtxt”
shuffle: false
num_readers: 1
}
1.5 进行模型训练
# python3 train.py \
--logtostderr \
--pipeline_config_path=datasetcarmore/ssd_mobilenet_v1_pascal.config \
--train_dir=datasetcarmore/train_dir
1.6 模型预测与检测
# python3 eval.py \
--logtostderr \
--pipeline_config_path=datasetcarmore/ssd_mobilenet_v1_pascal.config \
--checkpoint_dir=datasetcarmore/train_dir/model.ckpt-20202 \
--eval_dir=datasetcarmore/eval_result
1.7 转换为图文件
将model.chk文件转换为graph
# python3 export_inference_graph.py \
--input_type=image_tensor \
--pipeline_config_path=datasetcarmore/ssd_mobilenet_v1_pascal.config \
--trained_checkpoint_prefix=datasetcarmore/train_dir/model.ckpt-20202 \
--output_directory=datasetcarmore/inference_graph
1.8 测试图片
1.8.1 测试修改
- 当前目录/home/users/py3_project/models/research/object_detection下test.py文件,并重命名为test1.py:
- 两个路径修改为自己的路径及NUM_CLASS:

- 修改如下调用函数,增加参数min_score_thresh=0.3,即将输出分数阈值由默认0.5改为0.3,并输出车牌carNO边框carNOboxs:

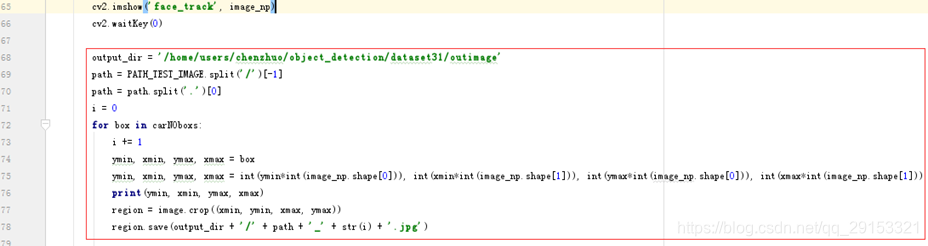
- 增加存储车牌图片代码:将车牌carNO检测区域图片剪裁出来,存入自己的路径
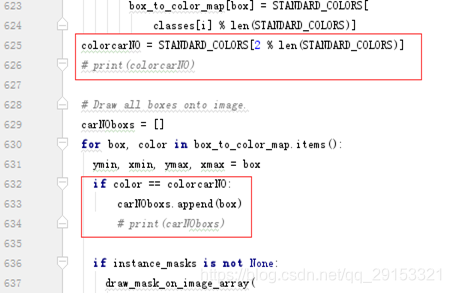
- 修改目录/home/users/py3_project/models/research/object_detection/utils下visualization_utils.py文件,按照carNO给定颜色将车牌carNO的区域挑选出来(实际上是四个位置的比例情况),并把返回改为return image, carNOboxs:
1.8.2 测试执行
使用 VNC-Viewer 客户端
执行依次测试多张图片:
# python3 test1.py datasetcarmore/5.jpg



1.8.3 结果分析
- 准确率:车牌carNO类别检测准确率能达到90%以上
- 检测样本多样性:以往模型对增强性(高斯模糊、高斯噪声等)样本进行测试,准确率很低;这次模型训练中加入了增强性样本后并进行测试,具有较强鲁棒性
- 不足:虽然能够检测倒立样本车牌,但过度倾斜的样本车牌没有检测出来,而车辆car类别能检测出来,说明可能样本的模型迭代次数较少,或者应该增加倾斜度较大的车牌样本进入训练。
二 车牌号预测
参考https://cloud.tencent.com/developer/article/1005199
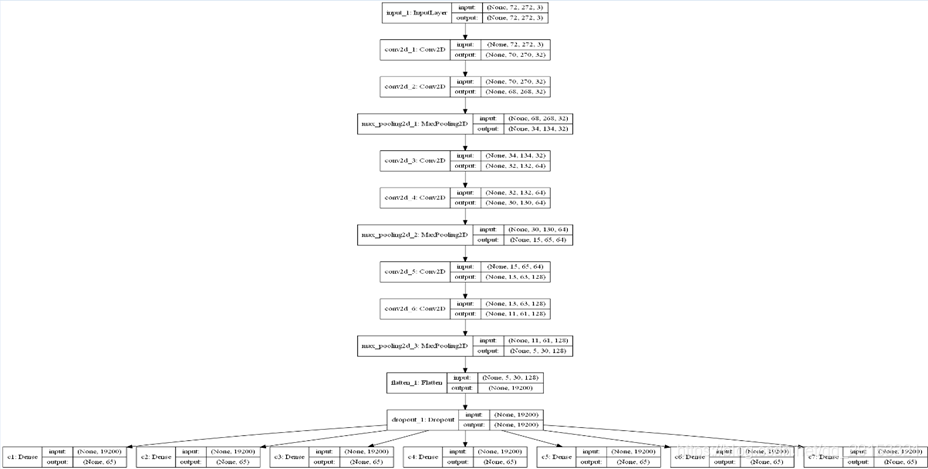
2.1 模型结构
首先使用的是端到端的模型,不需对图片字母进行切割。识别的固定长度为7的车牌号,因为是固定长度,可以用七个模型按照顺序识别。由于卷积神经网络在扫描整张图片的过程中,已经对整个图像的内容以及相对位置关系有所了解,所以,七个模型的卷积层实际上是可以共享的。可以用一个一组卷积层+7个全连接层的架构。
2.2 模型结果
经过10轮的2000次训练之后,模型准确率达到了90%以上。

但是,由于模型中使用的是自动生成的车牌号样本(几十万个),用实际的车牌进行预测时发现结果并不是很理想,说明自动生成的图片与实际图片还是有很大出入,但是实际的车牌号样本数据集又很难收集到。当然,如果有足够的数据集时,也可以同样用深度学习目标检测的方法直接对车牌内的字符识别。
