1. 原理-分词算法
1.1. 基于词典的分词
1、最大匹配分词算法:寻找最优组合的方式是将匹配到的最长词组合在一起。其缺点是严重依赖词典,无法很好地处理分词歧义和未登录词。优点是由于这种方法简单、速度快、且分词效果基本可以满足需求,因此在工业界仍然很受欢迎。
2、最短路径分词算法:将一句话中的所有词匹配出来,之后寻找从起始点到终点的最短路径作为最佳组合方式
基于Dijkstra算法求解最短路径、N-最短路径分词算法
3、基于n-gram model的分词算法:将基于词的语言模型所统计出的概率分布应用到词图中,求解最大概率的路径
1.2. 基于字的分词
把一个字标记成B(Begin), I(Inside), O(Outside), E(End), S(Single)。
1、生成式模型分词算法:n-gram模型、HMM隐马尔可夫模型、朴素贝叶斯分类等,基于Python的jieba分词器和基于Java的HanLP分词器都使用了HMM
2、判别式模型分词算法:感知机、CRF条件随机场等
1.3. 神经网络分词算法
目前公认效果最好的模型是BiLSTM+CRF
2. 实践部分
参考中文分词:中文有7000多个常用字,56000多个常用词
2.1. 规则、统计分词普通算法
https://blog.csdn.net/qiang12qiang12/article/details/81589386
https://github.com/liuhuanyong/WordSegment
正向最大匹配法
逆向最大匹配法
双向最大匹配算法
Ngram
HMM
1、数据集
3种匹配算法:25006个词

Ngram、HMM:人民日报预料29W句子

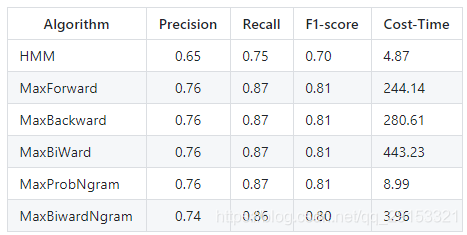
2、效果
评测语料:微软评测语料,共3985个句子
性能比较
2.2. CRF普通算法
https://github.com/liuhuanyong/HuanNLP
数据集、效果无详细介绍
2.3. BiLSTM+CRF
https://github.com/GlassyWing/bi-lstm-crf
1、词性标注实例
嫌 疑 人 赵 国 军 。 B-N I-N I-N B-NR I-NR I-NR S-W
其中B表示一个词语的开头,I表示非一个词语的开头,S表示单字成词。
2、数据集
选用人民日报2014年的80万语料作为训练语料
词数:20744
行数:317

已提供代码将语料转化为(1、)词性标注实例效果
2、效果
Recall: 0.939404
Precision: 0.949798
2.4. BiLSTM+CRF(算法同上)
https://github.com/EricLingRui/NLP-tools
在人民日报上的分词能达到正确率97%
https://github.com/howl-anderson/PaddleTokenizer
人民日报训练集,效果未写
https://github.com/stephen-v/zh-segmentation-keras
2.5. Universal Transformer (Encoder) + CRF
https://github.com/GlassyWing/transformer-word-segmenter
1、词性标注实例
嫌 疑 人 赵 国 军 。 B-N I-N I-N B-NR I-NR I-NR S-W
2、数据集
选用人民日报2014年的80万语料作为训练语料
词数:20744
行数:317

可代码转化为词性标注实例效果
3、效果
Recall: 0.962784
Precision: 0.960839
2.6. 快速神经网络分词包
https://github.com/yaoguangluo/Deta_Parser
版本号:11.1.0支持标点符号分离(因为标点特别多, 未做病句标点分析, 大家可以自由改 2019-05-14) 契形字符, 目前可混合识别12国语言, 可混合分词70国语言(契形+中(简,繁)日,韩,象形, 无标点,歧义,绕口令,带病句快速混分高质量算法研究同时保证1800万+/每秒混分速度和99.9%分词准确率(deta的科研目标是准确率上99.999999% (中文分析错误率小于亿分之一)) 和商业闭源语料库版(65000+中文简体词汇和35万12国词汇). 20190504
2.7. Jieba分词
https://github.com/fxsjy/jieba
涉及算法:
基于前缀词典实现词图扫描,生成句子中汉字所有可能成词情况所构成的有向无环图(DAG),采用动态规划查找最大概率路径,找出基于词频的最大切分组合;
对于未登录词,采用了基于汉字成词能力的 HMM模型,采用Viterbi算法进行计算;
基于Viterbi算法的词性标注;
分别基于tfidf和textrank模型抽取关键词;
用法:覆盖jieba中dict.txt语料词典
1、数据集
已分词汇349046个(后面词性可不需要)

3. 总结
目前分词实践主要有三类情况:
1、规则和统计分词等普通算法,很大程度依赖于词典,准确率约为65%-75%。
2、神经网络算法,准确率在90%以上,但需调研是否能用于其他语言标注的训练。
3、已有分词工具改变其词典,如jieba分词,准确率未知,算法原理基于规则和统计分词等普通算法。
数据集要求:
中文有7000多个常用字,56000多个常用词,上面实践中最少也标注了上万的词,针对其他的语言可以先标注部分语料进行测试。
