这里先来简单复习一下概率论中的一些基本知识:
1. 基本概念
事件A在另外一个事件B已经发生条件下的发生概率,称为条件概率,记为P(A|B)。
两个事件共同发生的概率称为联合概率。A与B的联合概率表示为 P(AB) 或者P(A,B)。进而有,P(AB) = P(B)P(A|B)=P(A)P(B|A)。这也就导出了最简单形式的贝叶斯公式,即P(A|B)=P(B|A)*P(A)/P(B)
以及条件概率的链式法则
P(A1,A2,…,An) = P(An|A1,A2,…,An-1)P(An-1|A1,A2,…,An-2)…P(A2|A1)P(A1)
概率论中还有一个全概率公式:
由此可进一步导出完整的贝叶斯公式:
马尔科夫假设:
如果是确定性的系统,也即是每个状态和状态的额转移都已知,那就很容易理解和分析。但是在实际当中还存在许多不确定性系统。在日常生活当中,我们总是希望根据当前天气的情况来预测未来天气情况,我们不能依靠现有知识确定天气情况的转移,但是我们还是希望能得到一个天气的模式。一种办法就是假设这个模型的每个状态都只依赖于前一个的状态,这个假设被称为马尔科夫假设,这个假设可以极大简化这个问题。显然,这个假设也是一个非常糟糕的假设,导致很多重要的信息都丢失了。
马尔可夫过程 :
谈到 HMM,首先简单介绍一下马尔可夫过程 (Markov Process),它因俄罗斯数学家安德烈·马尔可夫而得名,代表数学中具有马尔可夫性质的离散随机过程。该过程中,每个状态的转移只依赖于之前的 n 个状态,这个过程被称为1个 n 阶的模型,其中 n 是影响转移状态的数目。最简单的马尔科夫过程就是一阶过程,每一个状态的转移只依赖于其之前的那一个状态。注意这和确定性系统不一样,因为这种转移是有概率的,而不是确定性的。
马尔可夫链:
马尔可夫链是随机变量 X1, … , Xn 的一个数列。这些变量的范围,即他们所有可能取值的集合,被称为“状态空间”,而 Xn 的值则是在时间 n 的状态。如果 Xn+1 对于过去状态的条件概率分布仅是 Xn 的一个函数,则
这里 x 为过程中的某个状态。上面这个恒等式可以被看作是马尔可夫性质。
而一阶马尔科夫过程定义了以下三个部分:
- 状态
- 初始向量
- 状态转移矩阵
所有的能被这样描述的系统都是一个马尔科夫过程。
隐马尔科夫:
隐马尔可夫模型(Hidden Markov Model,HMM)是用来描述一个含有隐含未知参数的马尔可夫过程。典型的就是掷筛子的例子。。
https://www.zhihu.com/question/20962240/answer/33438846
这个例子应该是大部分讲到隐马尔可夫模型时都会提起的一个简单易懂的例子,这里不再重复讲述,但会和下面要讲的中文分词联系起来,这样更便于理解。
对 HMM 来说,有如下三个重要假设,尽管这些假设是不现实的。
假设1:马尔可夫假设(有限历史性假设)
假设2:齐次性假设(状态与具体时间无关)
假设3:输出独立性假设(输出也即是观察值仅与当前状态有关)
2. 统计中文分词
原理:
隐含马尔科夫模型在中文分词中的应用是将分词作为字在字符串中的序列标注任务来实现的:每个字在构成一个特定的词语时都会占据着一个确定的构词位置(词位),这里每个字只有四个位置:即B(词首)、M(词中)、E(词尾)、S(单独成词)。例如:
应该分为:小明/硕士/毕业于/中国/科学院/计算/所
对应标注:BE/BE/BME/BE/BME/BE/S
这也是我们最终要求的标注序列。
数学抽象为:用 代表输入的句子,n代表句子的长度, 表示字, 代表输出得标注结果,那么此时我们要求的就是 ,可以理解为输入一个句子,我们要求的是一组输出标注,使得此时的条件概率最大。这里的 即为B,M,E,S这4种标记之一。
这里如果直接计算上述的条件概率,
是关于2n个变量的条件概率,且n不固定,因此计算有一定的难度,这个时候就引入了观测独立性假设,此时就得到:
这个时候通过观测独立性假设,目标问题得到了极大的简化,然而该方法完全没有考虑到上下文,且会出现不合理的标注,比如很可能会得到:BBB、BEM等
怎么办?这个时候就要引入HMM:
我们一直期望的是
,这时通过贝叶斯公式得到:
此时最大化 就等价于最大化:
这时引入上述的HMM输出独立性假设:
同时对 有:
这里引入HMM的另一个假设:有限历史性假设,每一个输出仅与上一个输出有关,得到:
这里其实是一个二元语言模型,当每个输出与前两个有关时,就变成了三元语言模型,当然复杂度也随之变大。
到这里,通过贝叶斯公式,HMM的三个基本假设,得到了:
这里面的 称为发射概率, 称为转移概率。通过设置 可以排除BBB、EM等不合理的情况。
而在HMM中,求解 的常用方法就是维特比算法。核心思想是:如果最终的最优路径经过某个 ,那么从初始节点到 点的路径也是一个最优路径(因为每一个节点只会影响前后两个 和 )
以上是一些基本的原理,下面是具体的实现代码:
class HMM(object):
# 初始化一些全局信息
def __init__(self):
import os
# 主要是用于存取算法中间结果,不用每次都训练模型
self.model_file = './hmm_model.pkl'
# 状态值集合
self.state_list = ['B', 'M', 'E', 'S']
# 参数加载,用于判断是否需要重新加载model_file
self.load_para = False
# 用于加载已计算的中间结果,当需要重新训练时,需初始化清空结果
def try_load_model(self, trained):
if trained:
import pickle
with open(self.model_file, 'rb') as f:
self.A_dic = pickle.load(f)
self.B_dic = pickle.load(f)
self.Pi_dic = pickle.load(f)
self.load_para = True
else:
# 状态转移概率(状态->状态的条件概率)
self.A_dic = {}
# 发射概率(状态->词语的条件概率)
self.B_dic = {}
# 状态的初始概率
self.Pi_dic = {}
self.load_para = False
# 计算转移概率、发射概率以及初始概率
def train(self, path):
# 重置几个概率矩阵
self.try_load_model(False)
# 统计状态出现次数,求p(o)
Count_dic = {}
# 初始化参数函数
def init_parameters():
for state in self.state_list:
self.A_dic[state] = {s: 0.0 for s in self.state_list}
self.Pi_dic[state] = 0.0
self.B_dic[state] = {}
Count_dic[state] = 0
# 为每个读进来的字打标签,也即是状态值
def makeLabel(text):
out_text = []
if len(text) == 1:
out_text.append('S')
else:
# 列表的加操作,也即是列表的元素扩展
out_text += ['B'] + ['M'] * (len(text) - 2) + ['E']
return out_text
init_parameters()
#print('init_parameters:',self.A_dic)
line_num = -1
# 观察者集合,主要是字以及标点等
words = set()
with open(path, encoding='utf8') as f:
for line in f:
line_num += 1
#if line_num==2: # 测试用
#break
line = line.strip() # 用于移除字符串头尾指定的字符(默认为空格或换行符)或字符序列
#print('here:',line)
if not line:
continue
word_list = [i for i in line if i != ' ']
#print('word_list:',word_list)
words |= set(word_list) # 更新字的集合,这里用的是集合的并操作
linelist = line.split() # 按空格分割字串
#print('there:',linelist)
line_state = []
for w in linelist:
line_state.extend(makeLabel(w))
#print('line_state:',line_state)
assert len(word_list) == len(line_state)
for k, v in enumerate(line_state): # 这里的k:元素下标 v:元素值
#print('k,v:',k,v)
Count_dic[v] += 1
if k == 0:
self.Pi_dic[v] += 1 # 每个句子的第一个字的状态,用于计算初始状态概率
else:
# 计算转移pinlv:[line_state[k - 1]][v]用的非常好
self.A_dic[line_state[k - 1]][v] += 1
#print('B_dic[line_state[k]]:',self.B_dic[line_state[k]].get(word_list[k], 0))
# 计算发射频率,dict.get(key, default=None)
self.B_dic[line_state[k]][word_list[k]] = \
self.B_dic[line_state[k]].get(word_list[k], 0) + 1.0
#print('self.B_dic:',self.B_dic)
#print('A_dic:\n',self.A_dic)
#print('self.Pi_dic:',self.Pi_dic)
# 计算初始概率:用每行开头字的状态值除以所有行
self.Pi_dic = {k: v * 1.0 / line_num for k, v in self.Pi_dic.items()}
#print('self.Pi_dic:',self.Pi_dic)
#print('Count_dic:',Count_dic)
# 状态转移概率:4x4的矩阵的每一个转移状态值除以该状态出现的总数(count(M/B)/count(B))
self.A_dic = {k: {k1: v1 / Count_dic[k] for k1, v1 in v.items()}
for k, v in self.A_dic.items()}
#print('self.A_dic~:',self.A_dic)
#加1平滑(发射概率计算同状态转移计算方式大致一样)
self.B_dic = {k: {k1: (v1 + 1) / Count_dic[k] for k1, v1 in v.items()}
for k, v in self.B_dic.items()}
#序列化
import pickle
with open(self.model_file, 'wb') as f:
pickle.dump(self.A_dic, f)
pickle.dump(self.B_dic, f)
pickle.dump(self.Pi_dic, f)
# 返回对象本身
return self
def viterbi(self, text, states, start_p, trans_p, emit_p):
#print('start_p:',start_p,'\n','trans_p:', trans_p,'\n','emit_p:',emit_p)
V = [{}]
path = {}
for y in states:
#print('TT:',emit_p[y].get(text[0], 0))
V[0][y] = start_p[y] * emit_p[y].get(text[0], 0)
path[y] = [y]
for t in range(1, len(text)):
V.append({})
newpath = {}
# 检验训练的发射概率矩阵中是否有该字
neverSeen = text[t] not in emit_p['S'].keys() and \
text[t] not in emit_p['M'].keys() and \
text[t] not in emit_p['E'].keys() and \
text[t] not in emit_p['B'].keys()
#print(text[t],neverSeen)
for y in states:
#设置未知字单独成词
emitP = emit_p[y].get(text[t], 0) if not neverSeen else 1.0
(prob, state) = max([(V[t - 1][y0] * trans_p[y0].get(y, 0) *emitP, y0)
for y0 in states if V[t - 1][y0] > 0])
#print('prob:',prob,'state:',state,'——>',y)
V[t][y] = prob
#print('V[t]:~',V[t])
newpath[y] = path[state] + [y]
#print('newpath:',newpath)
path = newpath
if emit_p['M'].get(text[-1], 0)> emit_p['S'].get(text[-1], 0):
(prob, state) = max([(V[len(text) - 1][y], y) for y in ('E','M')])
else:
(prob, state) = max([(V[len(text) - 1][y], y) for y in states])
return (prob, path[state])
def cut(self, text):
import os
if not self.load_para:
self.try_load_model(os.path.exists(self.model_file))
prob, pos_list = self.viterbi(text, self.state_list, self.Pi_dic, self.A_dic, self.B_dic)
begin, next = 0, 0
for i, char in enumerate(text):
pos = pos_list[i]
if pos == 'B':
begin = i
elif pos == 'E':
yield text[begin: i+1]
next = i+1
elif pos == 'S':
yield char
next = i+1
if next < len(text):
yield text[next:]
hmm = HMM()
hmm.train('./trainCorpus.txt_utf8')
#hmm.train('./test.txt_utf8')
text = '这是一个非常棒的方案!'
res = hmm.cut(text)
print(text)
print(str(list(res)))运行结果:
这是一个非常棒的方案!
['这是', '一个', '非常', '棒', '的', '方案', '!']代码流程:
- 首先是加载训练数据,这里的语料库采用的是人民日报的分词语料
- 通过统计语料信息,得到HMM所需要的初始概率、转移概率、以及发射概率。
这里的初始概率计算中的频次是统计是每一行句子的第一个字所对应的状态值的个数。转移概率( )计算中的频次是统计每个字的状态(也即是BMES)到下一个字的状态的个数。而发射概率( )计算中的频次是统计相应的状态对应其字的个数。 - 最后就是进行相应的马尔科夫的计算过程。
这里如果直接进行分词的算法流程分析,很可能会被代码所迷惑,可以对比经典案例“活动预测相应的天气”。
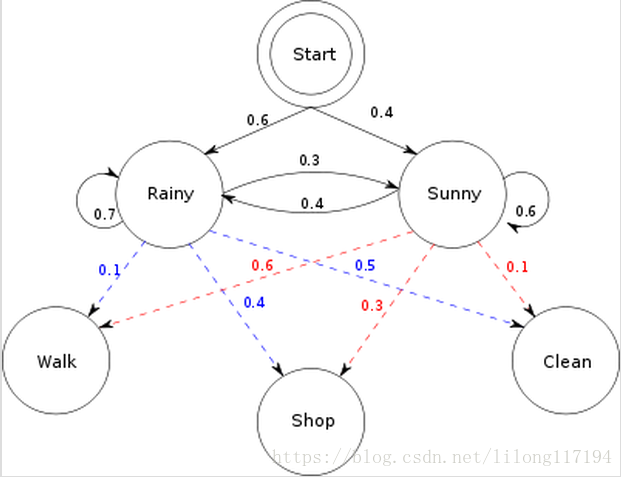
初始概率π=[ 0.6 0.4]
转移概率(天气(隐状态)之间互相转移)
| rain | sun | |
|---|---|---|
| rain | 0.7 | 0.3 |
| sun | 0.4 | 0.6 |
混淆矩阵(每种天气(隐状态)对应行为(可观测)的概率)
| walk | shop | clean | |
|---|---|---|---|
| rain | 0.1 | 0.4 | 0.5 |
| sun | 0.6 | 0.3 | 0.1 |
已知模型参数,以及三天的行为(walk,shop,clean)
求解:三天对应最可能的天气状态
①首先初始化,对于每一个天气状态,求当天对应行为的概率
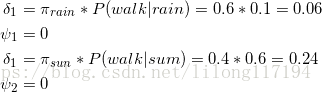
初始化,即第一天不用找最大值,因为第一天哪里知道最可能的路径,路径是链接两个节点的,一个节点无法称为路径
②第一天到达第二天的路径概率

③第二天到第三天的路径概率

④回溯
找到最后一天最大的概率,这个时候就可以得到隐藏的最大概率的路径。
在这里把分词的过程和上面例子对应起来:天气转换对应着分词中上一个字的状态值到下一个字对应的状态值的转移概率;相应天气下的活动的概率对应着相应状态值下的该字的发射概率。不同的是天气的例子中的初始概率转移矩阵是给定的,而本分词的例子是通过训练语料统计得到的。
其实该算法还有很多细节性的问题,这里不再讨论。。
参考:《pytho自然语言处理实战 核心技术与算法》
源码地址:https://github.com/nlpinaction/learning-nlp