开源中文对话预训练模型调研
文章目录
总结了一下当前(截止2023年4月18日)最新的几个开源的大规模中文预训练开放域对话生成模型。
| M o d e l Model Model | n p a r a m s n_{params} nparams | n l a y e r s n_{layers} nlayers | d m o d e l d_{model} dmodel | d f f d_{ff} dff | n h e a d s n_{heads} nheads | d h e a d d_{head} dhead | n_position |
|---|---|---|---|---|---|---|---|
| E V A 2. 0 B a s e EVA2.0_{Base} EVA2.0Base | 300M | 12 | 768 | 3072 | 12 | 64 | 512 |
| E V A 2. 0 L a r g e EVA2.0_{Large} EVA2.0Large | 970M | 24 | 1024 | 4096 | 16 | 64 | 512 |
| E V A 2. 0 x L a r g e EVA2.0_{xLarge} EVA2.0xLarge | 2.8B | 24 | 2048 | 5120 | 32 | 64 | 512 |
| C D i a l G P T L C C C − b a s e CDialGPT_{LCCC-base} CDialGPTLCCC−base | 104M | 12 | 768 | 3072 | 12 | 64 | 513 |
| C D i a l G P T 2 L C C C − b a s e CDialGPT2_{LCCC-base} CDialGPT2LCCC−base | 104M | 12 | 768 | 3072 | 12 | 64 | 513 |
| C D i a l G P T L C C C − l a r g e CDialGPT_{LCCC-large} CDialGPTLCCC−large | 104M | 12 | 768 | 3072 | 12 | 64 | 513 |
| G P T 2 − c h i t c h a t GPT2-chitchat GPT2−chitchat | 88M | 12 | 768 | 3072 | 12 | 64 | 300 |
| dialogue-bart-base-chinese | 6 | 768 | 3072 | 12 | 64 | 512 | |
| dialogue-bart-large-chinese | 12 | 1024 | 4096 | 16 | 64 | 512 |
1. CDial-GPT
主要工作
- Paper:A Large-Scale Chinese Short-Text Conversation Dataset
- 开源地址:https://github.com/scutcyr/CDial-GPT
- 主要贡献:(1)发布了一个经过严格过滤清洗后的大规模高质量中文对话语料库LCCC,base版本包括680万个对话,large版本包括1200万(12M)个对话。(2)同时发布了几个大规模预训练对话模型CDialGPT,首先在中文小说数据集上进行预训练,然后在LCCC上进行训练。
LCCC数据集
数据清洗策略
基于规则的清洗
-
删除平台标记:Reply to @***,[dog];
-
删除文本中的URL;
-
大于30轮的对话分割为小于三十轮的多个对话;
-
一个句子中重复6次以上的短语或单词只保留一份;
-
删除回复太长或太短的对话;
-
删除广告(A dataset for research on short-text conversations,EMNLP2013);
-
如果回复中90%的三元语法是高频三元语法,则删除对话;
-
如果回复是具有某些特定形式的通用回复,则删除对话;
-
删除回复与帖子相同的对话;
-
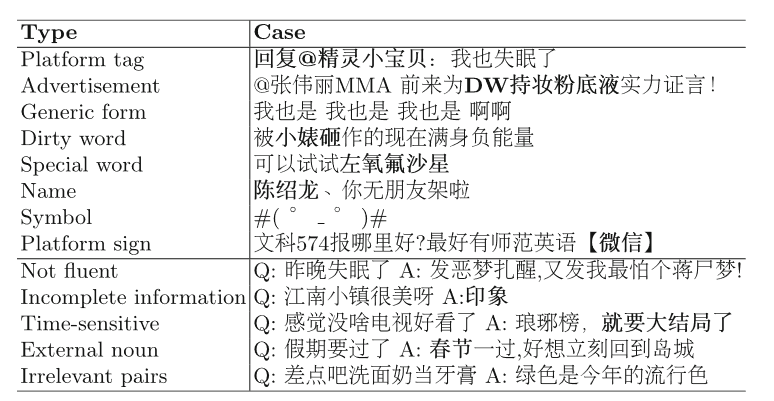
去除含有脏词、敏感词、方言、特殊词如左氧氟沙星、姓名、称呼或者未知的缩写、特殊符号和表情符号、平台标志如广告、图片、视频相关词语的对话。
基于分类器的清洗
(1)人工标注了十万个对话训练一个BERT,识别对话是否为噪声:
- 文本不流利或者严重的拼写错误;
- 回复不完整;
- 时间敏感的;
- 回复中出现节日、地点、性别时间等post没提到的;
- 回复和上下文不相关的;
(2)人工标注了一万个话语训练一个BERT,识别出现外部上下文知识,超出文本,使人难以理解。
模型
输入表征
把所有历史话语拼接成一个长文本序列,输入包括三种embedding之和,分别为word embedding,speaker embedding,position embedding。词嵌入和位置嵌入在预训练阶段学习,说话人嵌入则在后训练(微调)阶段学习。speaker embedding嵌入被用来表明不同的说话人,参考BERT,使用[CLS]和[SEP]表征一个句子的开始符和结束符。
训练
参考DialoGPT,基于Chinese-GPT(GPT-Novel),在LCCC上进行训练。对于多轮对话,将第二个到最后一个句子都作为对话历史的回复。
GPT(Noval):12层GPT,104M参数;
CDialGPT(LCCC-base):12层GPT,104M参数;
CDialGPT2(LCCC-base):12层GPT2,104M参数;
CDialGPT(LCCC-large):12层GPT,104M参数;
2. GPT2-chitchat
参考了GPT2-Chinese和DialoGPT。
开源地址:https://github.com/yangjianxin1/GPT2-chitchat。
使用GPT2模型对中文闲聊语料进行训练,根据微软的DialoGPT的思想,在项目中添加了互信息。训练了两个模型:Dialogue Model与MMI Model(maximum mutual information scoring function)。首先使用Dialogue Model生成多个候选response,然后使用MMI Model从候选response中,选取loss最小的作为最终的response。
具体可见:https://zhuanlan.zhihu.com/p/101151633
3. EVA1.0
- Paper:EVA: An Open-Domain Chinese Dialogue System with Large-Scale Generative Pre-Training
- 主要贡献:提出了EVA,一个大规模中文预训练对话模型,参数量为2B;构建了一个严格清洗过滤的大规模中文对话数据集WDC-Dialogue,包含1.4B个对话。
- 开源项目地址:https://github.com/thu-coai/EVA
WDC-DIalogue数据集
数据收集
社交媒体上的交互数据可以分为三类:
- Repost:转发博客,和被转发者产生一个对话;
- Comment:评论和回复;
- Q&A:在线问答,在知乎这类平台多。
数据清洗
参照LCCC的数据清洗策略和方法。
模型
分词
传统的基于字符级的中文分词容易丢失汉语词汇或短语的重要于一,因此构建了一个中文的子词词表,包括中文的字和词,基于Sentencepiece的unigram language model。总共包含3万个词。
预训练细节
-
Encoder-Decoder型架构;
-
对于n个utterance,以n-1个utterances编码,生成第n个utterance。
-
最大编码和解码长度设置为128。
-
为了解决短utterance被大量pad的效率瓶颈,提出了一个新的数据采样策略,将多个context-response pairs拼成一个样本,引入新的attention-mask来区分它们,确保它们不会互相干扰。
-
EVA采用和T5一样的相对位置编码。
实验
实验比较发现,EVA生成性能比CDialGPT好,主要体现在生成结果的信息性上,CDialGPT可能更倾向于生成通用回复。
4. EVA2.0
- Paper:EVA2.0: Investigating Open-domain Chinese Dialogue Systems with Large-scale Pre-training
- 开源项目地址:https://github.com/thu-coai/EVA
这是目前开源的参数量最大,性能最好的中文对话预训练模型,相比EVA1.0它进行了更严格的数据清洗和过滤。这篇文章讲述了如何构造一个中文开放域的大规模对话系统,并做了一些严谨的实验去研究对训练结果造成影响的因素,如模型层数设置、预训练方法、解码策略,并且说明了对话系统仍然存在一致性、知识性、安全性的问题。
5. dialogue-bart-chinese
HIT-TMG开源的基于BART的中文对话模型,模型在四个语料库上训练。Chinese Persona Chat、LCCC (CPC)、Emotional STC (ESTC)、KdConv。
详情可见:
https://huggingface.co/HIT-TMG/dialogue-bart-base-chinese
https://huggingface.co/HIT-TMG/dialogue-bart-large-chinese