一、前言
n-gram模型,称为N元模型,可用于定义字符串中的距离,也可用于中文的分词;该模型假设第n个词的出现只与前面n-1个词相关,与其他词都不相关,整个语句的概率就是各个词出现概率的乘积;而这些概率,利用语料,统计同时出现相关词的概率次数计算得到;常用的模型是Bi-gram和Tri-gram模型。
n-gram的应用:模糊匹配
二、算法推论
假设一个字符串s由m个词组成,因此我们需要计算出P(w1,w2,⋯,wm)的概率,根据概率论中的链式法则得到如下:
P(w1,w2,…,wm) = P(w1)*P(w2|w1)*P(w3|w1,w2|)…P(wm|w1,w2…wm-1)
直接计算这个概率的难度有点大,根据n-gram的假设,当前词仅与前面几个词相关,即
P(wi|w1,w2…wi-1) = P(wi|wi-n+1+1,wi-1),其中i为某个词的位置,n为定义的相关的前几个词,因此得到如下:
当n=1时,即一元模型(Uni-gram)
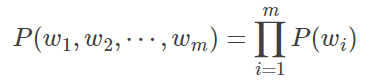
但 n=2时,即二元模型(Bi-gram)
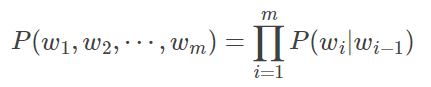
当n=3时,即三元模型(Tri-gram)
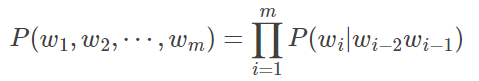
缺点:在语料训练的时候,存在着数据稀疏的情况,因此需要用平滑的技术手段进行处理。
三、实验
3.1最大化概率2-gram分词算法
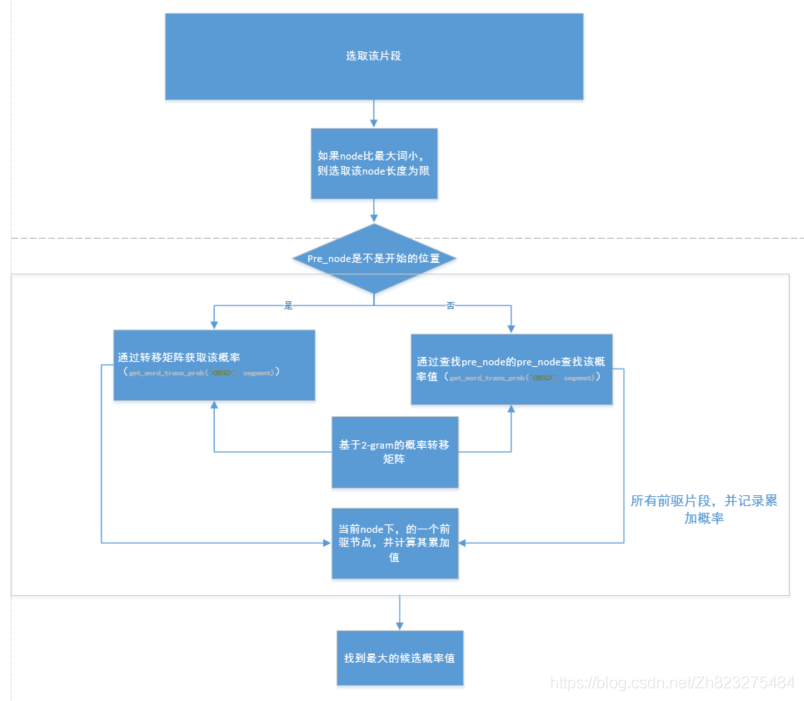
3.1.1算法描述:
1、将带分词的字符串从左到右切分为w1,w2,…,wi;
2、计算当前词与所有前驱词的概率
3、计算该词的累计概率值,并筛选最大的累计概率则为最好的前驱点;
4、重复步骤3,直到该字符串结束;
5、从wi开始,按照从右到左的顺序,依次将没歌词的最佳前驱词输出,即字符串的分词结束。
3.1.2算法框架

3.1.3代码如下:
word_dict = {}# 用于统计词语的频次
transdict = {} # 用于统计该词后面词出现的个数
def train(train_data_path):
transdict['<BEG>'] = {}#<beg>表示开始的标识
word_dict['<BEG>'] = 0
for sent in open(train_data_path,encoding='utf-8'):
word_dict['<BEG>'] +=1
sent = sent.strip().split(' ')
sent_list = []
for word in sent:
if word !='':
sent_list.append(word)
for i,word in enumerate(sent_list):
if word not in word_dict:
word_dict[word] = 1
else:
word_dict[word] +=1
# 统计transdict bi-gram<word1,word2>
word1,word2 = '',''
# 如果是句首,则为<beg,word>
if i == 0:
word1,word2 = '<BEG>',word
# 如果是句尾,则为<word,END>
elif i == len(sent_list)-1:
word1,word2 = word,'<END>'
else:
word1,word2 = word,sent_list[i+1]
# 统计当前次后接词出现的次数
if word not in transdict.keys():
transdict[word1]={}
if word2 not in transdict[word1]:
transdict[word1][word2] =1
else:
transdict[word1][word2] +=1
return word_dict,transdict
# 最大化概率2-gram分词
import math
word_dict = {}# 统计词频的概率
trans_dict = {}# 当前词后接词的概率
trans_dict_count = {}#记录转移词频
max_wordLength = 0# 词的最大长度
all_freq = 0 # 所有词的词频总和
train_data_path = "D:\workspace\project\\NLPcase\\ngram\\data\\train.txt"
from ngram import ngramTrain
word_dict_count,Trans_dict = ngramTrain.train(train_data_path)
all_freq = sum(word_dict_count)
max_wordLength = max([len(word) for word in word_dict_count.keys()])
for key in word_dict_count:
word_dict[key] = math.log(word_dict_count[key]/all_freq)
# 计算转移概率
for pre_word,post_info in Trans_dict.items():
for post_word,count in post_info:
word_pair = pre_word+' '+post_word
trans_dict_count[word_pair] = float(count)
if pre_word in word_dict_count.keys():
trans_dict[word_pair] = math.log(count/word_dict_count[pre_word])
else:
trans_dict[word_pair] = word_dict[post_word]
# 估算未出现词的概率,平滑算法
def get_unk_word_prob(word):
return math.log(1.0/all_freq**len(word))
# 获取候选词的概率
def get_word_prob(word):
if word in word_dict:
prob = word_dict[word]
else:
prob = get_unk_word_prob(word)
return prob
# 获取转移概率
def get_word_trans_prob(pre_word,post_word):
trans_word = pre_word+" "+post_word
if trans_word in trans_dict:
trans_prob = math.log(trans_dict_count[trans_word]/word_dict_count[pre_word])
else:
trans_prob = get_word_prob(post_word)
return trans_prob
# 寻找node的最佳前驱节点,方法为寻找所有可能的前驱片段
def get_best_pre_nodes(sent,node,node_state_list):
# 如果node比最大词小,则取的片段长度的长度为限
max_seg_length = min([node,max_wordLength])
pre_node_list = []# 前驱节点列表
# 获得所有的前驱片段,并记录累加概率
for segment_length in range(1,max_seg_length+1):
segment_start_node = node - segment_length
segment = sent[segment_start_node:node]# 获取前驱片段
pre_node = segment_start_node# 记录对应的前驱节点
if pre_node == 0:
# 如果前驱片段开始节点是序列的开始节点,则概率为<S>转移到当前的概率
segment_prob = get_word_trans_prob("<BEG>",segment)
else:# 如果不是序列的开始节点,则按照二元概率计算
# 获得前驱片段的一个词
pre_pre_node = node_state_list[pre_node]["pre_node"]
pre_pre_word = sent[pre_pre_node:pre_node]
segment_prob = get_word_trans_prob(pre_pre_word,segment)
pre_node_prob_sum = node_state_list[pre_node]["prob_sum"]
# 当前node一个候选的累加概率值
candidate_prob_sum = pre_node_prob_sum+segment_prob
pre_node_list.append((pre_node,candidate_prob_sum))
# 找到最大的候选概率值
(best_pre_node, best_prob_sum) = max(pre_node_list,key=lambda d:d[1])
return best_pre_node,best_prob_sum
def cut(sent):
sent = sent.strip()
# 初始化
node_state_list = []#主要是记录节点的最佳前驱,以及概率值总和
ini_state = {}
ini_state['pre_node'] = -1
ini_state['prob_sum'] = 0 #当前概率总和
node_state_list.append(ini_state)
# 逐个节点的寻找最佳的前驱点
for node in range(1,len(sent)+1):
# 寻找最佳前驱,并记录当前最大的概率累加值
(best_pre_node,best_prob_sum) = get_best_pre_nodes(sent,node,node_state_list)
# 添加到队列
cur_node ={}
cur_node['pre_node'] = best_pre_node
cur_node['prob_sum'] = best_prob_sum
node_state_list.append(cur_node)
# 获得最优路径,从后到前
best_path = []
node = len(sent)
best_path.append(node)
while True:
pre_node = node_state_list[node]['pre_node']
if pre_node ==-1:
break
node = pre_node
best_path.append(node)
# 构建词的切分
word_list = []
for i in range(len(best_path)-1):
left = best_path[i]
right = best_path[i+1]
word = sent[left:right]
word_list.append(word)
return word_list
3.2、基于ngram的前向后向最大匹配算法
3.2.1 算法描述
1、利用最大向前和向后的算法对待句子进行切分,分别得到两个字符串s1和s2
2、如果得到两个不同的词序列,则根据bi-gram选择概率最大的(此方法可以消除歧义);
3、计算基于bi-garm的句子生成概率;
3.2.2代码如下:
# 最要是基于bi-gram的最大前向后向算法,对中文进行分词
import math
from ngram import ngramTrain
from maxMatch import maxBackforward
from maxMatch import maxForward
train_data_path = "D:\workspace\project\\NLPcase\\ngram\\data\\train.txt"
word_counts = 0# 语料库中的总词数
word_types = 0#语料库中的词种类数目
word_dict,trans_dict = ngramTrain.train(train_data_path)
word_types = len(word_dict)
word_counts = sum(word_dict.values())
# 计算基于ngram的句子生成概率
def compute_likehood(seg_list):
p = 0
# 由于概率很小,对连乘取对数转化为加法
for pos,words in enumerate(seg_list):
if pos < len(seg_list)-1:
# 乘以后面的条件概率
word1,word2 = words,seg_list[pos+1]
if word1 not in trans_dict:
# 加平滑,让个该词至少出现1次
p += math.log(1.0/word_counts)
else:
# 加1平滑
fenzi, fenmu = 1.0,word_counts
# 计算转移概率,如p(w1/w2) 为在转移矩阵中trans_dict[word1][word2]在整行的占比
for key in trans_dict[word1]:
if key == word2:
fenzi +=trans_dict[word1][word2]
fenmu += trans_dict[word1][key]
# log(p(w0)*p(w1|w0)*p(w2|w1)*p(w3|w2)) == log(w0)+ log(p(w1|w0))+ log(p(w2|w1)) + log(p(w3|w2))
p +=math.log(fenzi/fenmu)
# 乘以第一个词的概率
if (pos == 0 and words !='<BEG>') or (pos == 1 and seg_list[0] == '<BEG>'):
if words in word_dict:
p += math.log((float(word_dict[words])+1.0)/word_types+word_counts)
else:
# 加1进行平滑
p +=math.log(1.0/(word_types+word_counts))
return p
# 然后进行分词
def cut_main(sent):
seg_list1 = maxForward.maxForwardCut(sent,5,word_dict)
seg_list2 = maxBackforward.maxBackforwadCut(sent,5,word_dict)
seg_list = []
# differ_list1和differ_list2分布及记录两个句子词序不同的部分,用于消除歧义
differ_list1 = []
differ_list2 = []
# pos1和pos2记录两个句子的当前字的位置,cur1和cur2记录两个句子的第几个词
pos1 = pos2 = 0
cur1=cur2 = 0
while 1:
if cur1 == len(seg_list1) and cur2 == len(seg_list2):
break
if pos1 == pos2:# 位置相同
if len(seg_list1[cur1]) == len(seg_list2[cur2]):# 对应的词的长度也相同
pos1 +=len(seg_list1[cur1])# 移到下一位置
pos2 += len(seg_list2[cur2]) # 移到下一位置
if len(differ_list1)>0:
# 说明此时得到两个不同的词序列,根据bi-gram选择概率大的
# 注意不同的时候哟啊考虑加上前面一个词和后面一个词,拼接的时候在去掉
differ_list1.insert(0,seg_list[-1])
differ_list2.insert(0,seg_list[-1])
if cur1 < len(seg_list1)-1:
differ_list1.append(seg_list1[cur1])
differ_list2.append(seg_list2[cur2])
p1 = compute_likehood(differ_list1)
p2 = compute_likehood(differ_list2)
if p1>p2:
differ_list = differ_list1
else:
differ_list = differ_list2
differ_list.remove(differ_list[0])
if cur1<len(seg_list1)-1:
differ_list.remove(seg_list1[cur1])
for words in differ_list:
seg_list.append(words)
differ_list1 = []
differ_list2 = []
seg_list.append(seg_list1[cur1])
cur1 +=1
cur2 +=1
elif len(seg_list1[cur1]) > len(seg_list2[cur2]):
differ_list2.append(seg_list2[cur2])# 记录的其实是前一个词
pos2 += len(seg_list2[cur2])
cur2 +=1
else:
differ_list1.append(seg_list1[cur1])# 记录的其实是前一个词
pos1 +=len(seg_list1[cur1])
cur1 +=1
else:
if pos1 + len(seg_list1[cur1]) == pos2 + len(seg_list2[cur2]):
differ_list1.append(seg_list1[cur1])
differ_list2.append(seg_list2[cur2])
pos1 += len(seg_list1[cur1])
pos2 += len(seg_list2[cur2])
cur1 += 1
cur2 += 1
elif pos1+len(seg_list1[cur1])>pos2+len(seg_list2[cur2]):
differ_list2.append(seg_list2[cur2])
pos2 += len(seg_list2[cur2])
cur2 += 1
else:
differ_list1.append(seg_list1[cur1])
pos1 += len(seg_list1[cur1])
cur1 += 1
return seg_list
四、总结
最大概率n-gram的方法是借鉴了动态规划方法寻找最大概率的路径,从而找到最佳的分词方法。主要难点主要在于基于n-gram的前后向匹配算法,在分词过程中,需要用两个指针(记录字的位置和记录词的位置),找到不同的部分,在计算其句子生成的概率,从而消除具有歧义的分词的算法,这个可以避免前后向匹配算法造成的缺点。
本文主要是用于学习笔记记录,方便本人学习。
五、参考资料
https://blog.csdn.net/baimafujinji/article/details/51281816
https://blog.csdn.net/chase1998/article/details/83247192
https://www.cnblogs.com/xlturing/p/8467021.html
https://github.com/liuhuanyong/WordSegment/blob/master/biward_ngram.py