基本问题
维特比算法利用动态规划思想求解概率最大路径(可理解为求图最短路径问题), 其时间复杂度为O(N*L*L),其中N为观察者序列长度,L为隐含状态大小。该算法的核心思想是:通过综合状态之间的转移概率和前一个状态的情况计算出概率最大的状态转换路径,从而推断出隐含状态的序列的情况,即在每一步的所有选择都保存了前继所有步骤到当前步骤当前选择的最小总代价(或者最大价值)以及当前代价的情况下后续步骤的选择。依次计算完所有步骤后,通过回溯的方法找到最优选择路径。
简单来说,在计算第t+1时刻的最短路径时,只需要考虑从开始到当前t时刻下k个状态值的最短路径和当前状态值到第t+1状态值的最短路径即可。如求t=3时的最短路径,等于求t=2时的所有状态结点x2t(见上图-2所示)的最短路径再加上t=2到t=3的各节点的最短路径。
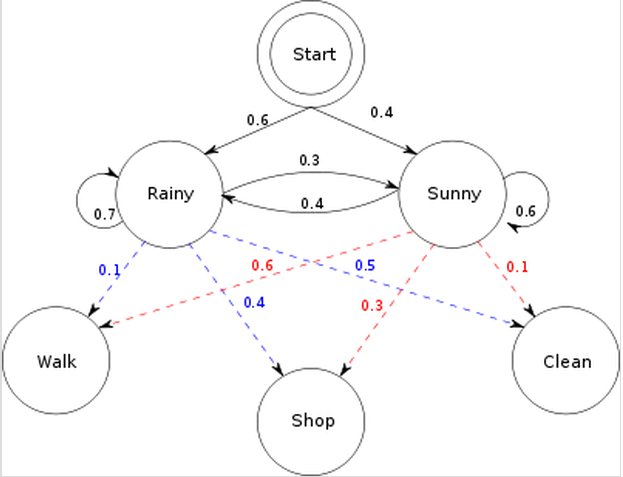
这张图就告诉了我们HMM的模型参数
初始概率π=[ 0.6 0.4]
转移概率(天气(隐状态)之间互相转移)
| rain | sun | |
| rain | 0.7 | 0.3 |
| sun | 0.4 | 0.6 |
| walk | shop | clean | |
| rain | 0.1 | 0.4 | 0.5 |
| sun | 0.6 | 0.3 | 0.1 |
求解:三天对应最可能的天气状态
解答:
【注】δ的下标不是代表第几天,而是当前天的第几个隐状态
①首先初始化,对于每一个天气状态,求当天对应行为的概率
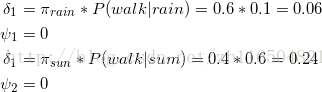
初始化,即第一天不用找最大值,因为第一天哪里知道最可能的路径,路径是链接两个节点的,一个节点无法称为路径
②第一天到达第二天的路径概率
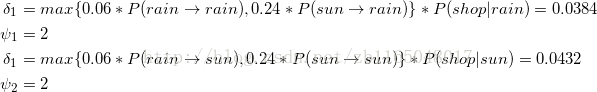
③第二天到第三天的路径概率
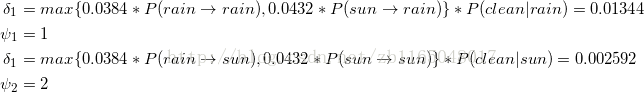
④回溯
找到最后一天最大的概率
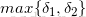
发现第三天对应第一个状态的概率最大,而且此概率通过③中的ψ1是第二天的第一个状态ψ1到达第三天的第一个状态得到的,所以第二天对应的应该是第一个状态。
而到达第二天的第一个状态的最大概率是第一天的第二个状态,通过②中的ψ1能够看出来。
所以合起来就是第一天的第二个状态->第二天的第一个状态->第三天的第一个状态
即三天天气应该是(sun,rain,rain)
public class Viterbi {
private static class TNode {
public int[] v_path; // 节点路径
public double v_prob; // 概率累计值
public TNode( int[] v_path, double v_prob) {
this.v_path = copyIntArray(v_path);
this.v_prob = v_prob;
}
}
private static int[] copyIntArray(int[] ia) { // 数组拷贝
int[] newIa = new int[ia.length];
System.arraycopy(ia, 0, newIa, 0, ia.length); // 较wiki源码有改动
return newIa;
}
private static int[] copyIntArray(int[] ia, int newInt) { // 数组拷贝
int[] newIa = new int[ia.length + 1];
System.arraycopy(ia, 0, newIa, 0, ia.length); // 较wiki的源码稍有改动
newIa[ia.length] = newInt;
return newIa;
}
// forwardViterbi(observations, states, start_probability,
// transition_probability, emission_probability)
public int[] forwardViterbi(String[] y, String[] X, double[] sp,
double[][] tp, double[][] ep) {
TNode[] T = new TNode[X.length];
for (int state = 0; state < X.length; state++) {
int[] intArray = new int[1];
intArray[0] = state;
T[state] = new TNode(intArray, sp[state] * ep[state][0]);
}
for (int output = 1; output < y.length; output++) {
TNode[] U = new TNode[X.length];
for (int next_state = 0; next_state < X.length; next_state++) {
int[] argmax = new int[0];
double valmax = 0;
for (int state = 0; state < X.length; state++) {
int[] v_path = copyIntArray(T[state].v_path);
double v_prob = T[state].v_prob;
double p = ep[next_state][output] * tp[state][next_state];
v_prob *= p; // 核心元语
if (v_prob > valmax) { // 每一轮会增加节点
if (v_path.length == y.length) { // 最终截止
argmax = copyIntArray(v_path);
} else {
argmax = copyIntArray(v_path, next_state); // 增加新的节点
}
valmax = v_prob;
}
} // the number 3 for
U[next_state] = new TNode(argmax, valmax);
} // the number 2 for
T = U;
}
// apply sum/max to the final states:
int[] argmax = new int[0];
double valmax = 0;
for (int state = 0; state < X.length; state++) {
int[] v_path = copyIntArray(T[state].v_path);
double v_prob = T[state].v_prob;
if (v_prob > valmax) {
argmax = copyIntArray(v_path);
valmax = v_prob;
}
}
return argmax;
}
}