Application:
Standard NN
real estate
Online advertising
CNN
RNN
Speech recognition
Machine translation
Custom/hybrid RNNs
(
x
,
y
)
,
x
∈
R
n
x
,
y
∈
{
0
,
1
}
(x,y), x∈R^{n_x} ,y∈\{0,1\}
( x , y ) , x ∈ R n x , y ∈ { 0 , 1 } m training example {
(
x
(
1
)
,
y
(
1
)
)
,
(
x
(
2
)
,
y
(
2
)
)
,
.
.
.
,
(
x
(
m
)
,
y
(
m
)
)
(x^{(1)},y^{(1)}),(x^{(2)},y^{(2)}),...,(x^{(m)},y^{(m)})
( x ( 1 ) , y ( 1 ) ) , ( x ( 2 ) , y ( 2 ) ) , . . . , ( x ( m ) , y ( m ) )
X
=
[
.
.
.
.
.
−
.
.
.
.
.
∣
x
(
1
)
x
(
2
)
.
.
.
.
.
.
x
(
m
)
n
x
.
.
.
.
.
∣
.
.
.
.
.
−
<
−
m
−
>
]
X= \left[ \begin{matrix} . & . & . & . & .& -\\ . & . & . & . & . &|\\ x^{(1)} & x^{(2)} & ... & ... & x^{(m)} & n_x\\ . & . & . & . & .& | \\ . & . & . & . & .& -\\ <- & & m & & ->& \\ \end{matrix} \right]
X = ⎣ ⎢ ⎢ ⎢ ⎢ ⎢ ⎢ ⎡ . . x ( 1 ) . . < − . . x ( 2 ) . . . . . . . . . m . . . . . . . . . x ( m ) . . − > − ∣ n x ∣ − ⎦ ⎥ ⎥ ⎥ ⎥ ⎥ ⎥ ⎤
X
∈
R
n
x
∗
m
,
Y
=
[
y
(
1
)
,
y
(
2
)
,
.
.
,
y
(
m
)
]
,
Y
∈
R
1
∗
m
X∈R^{n_x * m }, Y=[y^{(1)},y^{(2)},..,y^{(m)}], Y∈R^{1* m}
X ∈ R n x ∗ m , Y = [ y ( 1 ) , y ( 2 ) , . . , y ( m ) ] , Y ∈ R 1 ∗ m
x.shape(nx,m) y.shape=(1,m)
x
∈
R
n
x
,
w
a
n
t
:
y
^
=
P
(
y
=
1
∣
x
)
,
s
o
0
≤
y
^
≤
1
x∈R^{n_x}, want: \hat{y}=P(y=1|x),so 0≤\hat{y}≤1
x ∈ R n x , w a n t : y ^ = P ( y = 1 ∣ x ) , s o 0 ≤ y ^ ≤ 1
p
a
r
a
m
e
t
e
r
s
:
w
∈
R
n
x
,
b
∈
R
parameters: w∈R^{n_x},b∈R
p a r a m e t e r s : w ∈ R n x , b ∈ R
O
u
t
p
u
t
:
y
^
=
σ
(
w
T
x
+
b
)
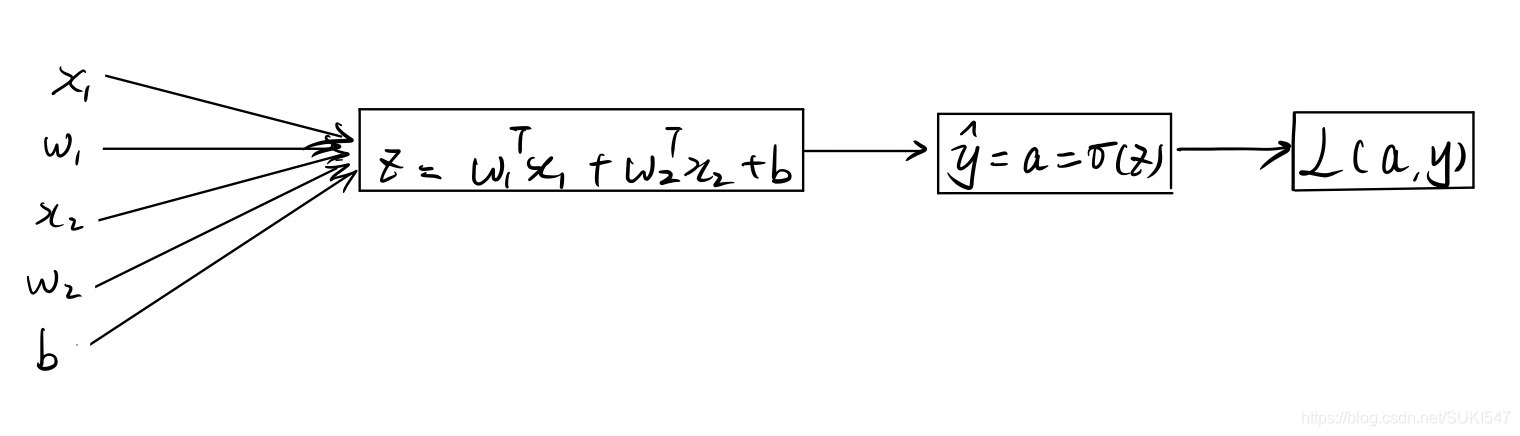
Output: \hat{y}=\sigma (w^Tx+b)
O u t p u t : y ^ = σ ( w T x + b )
σ
\sigma
σ is activation function
σ
(
z
)
=
1
1
+
e
(
−
z
)
\sigma (z)= \frac{1}{1+e^{(-z)}}
σ ( z ) = 1 + e ( − z ) 1
y
^
(
i
)
=
σ
(
w
T
x
(
i
)
+
b
)
\hat{y}^{(i)}= \sigma(w^Tx^{(i)}+b)
y ^ ( i ) = σ ( w T x ( i ) + b )
given {
(
x
(
1
)
,
y
(
1
)
)
,
(
x
(
2
)
,
y
(
2
)
)
,
.
.
.
,
(
x
(
m
)
,
y
(
m
)
)
(x^{(1)},y^{(1)}),(x^{(2)},y^{(2)}),...,(x^{(m)},y^{(m)})
( x ( 1 ) , y ( 1 ) ) , ( x ( 2 ) , y ( 2 ) ) , . . . , ( x ( m ) , y ( m ) )
y
^
(
i
)
≈
y
(
i
)
\hat{y}^{(i)} \approx y^{(i)}
y ^ ( i ) ≈ y ( i )
usually can use
L
(
y
^
,
y
)
=
1
2
(
y
^
−
y
)
2
L(\hat{y},y)=\frac{1}{2}(\hat{y}-y)^2
L ( y ^ , y ) = 2 1 ( y ^ − y ) 2
to measure the gap but later gradient descent may not work well because it’s non-convex function
y
^
=
σ
(
w
T
x
+
b
)
,
w
h
e
r
e
:
σ
(
z
)
=
1
1
+
e
−
z
,
i
n
t
e
r
p
r
e
t
:
y
^
=
P
(
y
=
1
∣
x
)
\hat{y}=\sigma (w^Tx+b),where: \sigma(z)=\frac{1}{1+e^{-z}},interpret :\hat{y}=P(y=1|x)
y ^ = σ ( w T x + b ) , w h e r e : σ ( z ) = 1 + e − z 1 , i n t e r p r e t : y ^ = P ( y = 1 ∣ x )
y
=
1
:
P
(
y
∣
x
)
=
y
^
y=1:P(y|x)=\hat{y}
y = 1 : P ( y ∣ x ) = y ^
y
=
0
:
P
(
y
∣
x
)
=
1
−
y
^
y=0:P(y|x)=1-\hat{y}
y = 0 : P ( y ∣ x ) = 1 − y ^
combine the function above
P
(
y
∣
x
)
=
y
^
y
(
1
−
y
^
)
1
−
y
P(y|x)=\hat{y}^y(1-\hat{y})^{1-y}
P ( y ∣ x ) = y ^ y ( 1 − y ^ ) 1 − y
log
\log
log
log
P
(
y
∣
x
)
=
y
log
y
^
+
(
1
−
y
)
log
(
1
−
y
^
)
\log P(y|x)=y\log\hat{y}+(1-y)\log(1-\hat{y})
log P ( y ∣ x ) = y log y ^ + ( 1 − y ) log ( 1 − y ^ )
−
log
P
(
y
∣
x
)
=
−
[
y
log
y
^
+
(
1
−
y
)
log
(
1
−
y
^
)
]
L
(
y
^
,
y
)
=
−
[
y
log
y
^
+
(
1
−
y
)
log
(
1
−
y
^
)
]
\begin{aligned} -\log P(y|x)=&-[y\log\hat{y}+(1-y)\log(1-\hat{y})]\\ L(\hat{y},y)=&-[y\log\hat{y}+(1-y)\log(1-\hat{y})] \end{aligned}
− log P ( y ∣ x ) = L ( y ^ , y ) = − [ y log y ^ + ( 1 − y ) log ( 1 − y ^ ) ] − [ y log y ^ + ( 1 − y ) log ( 1 − y ^ ) ]
this is the cost function with single example
under IID
P
(
l
a
b
e
l
s
−
i
n
−
t
r
a
i
n
i
n
g
−
s
e
t
)
=
∏
i
=
1
m
P
(
y
(
i
)
∣
x
(
i
)
)
P(labels-in-training-set) =\prod_{i=1}^mP(y^{(i)}|x^{(i)})
P ( l a b e l s − i n − t r a i n i n g − s e t ) = i = 1 ∏ m P ( y ( i ) ∣ x ( i ) )
log
\log
log
log
P
(
l
a
b
e
l
s
−
i
n
−
t
r
a
i
n
i
n
g
−
s
e
t
)
=
log
∏
i
=
1
m
P
(
y
(
i
)
∣
x
(
i
)
)
=
∑
i
=
1
m
log
P
(
y
(
i
)
∣
x
(
i
)
)
=
∑
i
=
1
m
−
L
(
y
^
(
i
)
,
y
(
i
)
)
=
1
m
∑
i
=
1
m
−
L
(
y
^
(
i
)
,
y
(
i
)
)
\begin{aligned} \log P(labels-in-training-set) =&\log \prod_{i=1}^mP(y^{(i)}|x^{(i)})\\ =&\sum_{i=1}^m \log P(y^{(i)}|x^{(i)})\\ =&\sum_{i=1}^m-L(\hat{y}^{(i)},y^{(i)})\\ =&\frac{1}{m}\sum_{i=1}^m-L(\hat{y}^{(i)},y^{(i)}) \end{aligned}
log P ( l a b e l s − i n − t r a i n i n g − s e t ) = = = = log i = 1 ∏ m P ( y ( i ) ∣ x ( i ) ) i = 1 ∑ m log P ( y ( i ) ∣ x ( i ) ) i = 1 ∑ m − L ( y ^ ( i ) , y ( i ) ) m 1 i = 1 ∑ m − L ( y ^ ( i ) , y ( i ) )
add
1
m
\frac{1}{m}
m 1
J
(
w
,
b
)
=
1
m
∑
i
=
1
m
L
(
y
^
(
i
)
,
y
(
i
)
)
J(w,b)=\frac{1}{m}\sum_{i=1}^m L(\hat{y}^{(i)},y^{(i)})
J ( w , b ) = m 1 i = 1 ∑ m L ( y ^ ( i ) , y ( i ) )
remove the nagative for minimize the cost function
J
(
w
,
b
)
J(w,b)
J ( w , b ) convex func , that is the particular reason to be chosen for cost function
Repeat:{
w
:
=
w
−
α
d
J
(
w
,
b
)
d
w
w:= w-\alpha \frac{dJ(w,b)}{dw}
w : = w − α d w d J ( w , b )
b
:
=
b
−
α
d
J
(
w
,
b
)
d
b
b:= b-\alpha \frac{dJ(w,b)}{db}
b : = b − α d b d J ( w , b )
α
\alpha
α
from right to left
d
L
d
a
=
−
y
a
+
1
−
y
1
−
a
\frac{dL}{da}=-\frac{y}{a}+\frac{1-y}{1-a}
d a d L = − a y + 1 − a 1 − y
d
L
d
z
=
d
L
d
a
⋅
d
a
d
z
=
(
−
y
a
+
1
−
y
1
−
a
)
(
a
(
1
−
a
)
)
=
a
−
y
=
d
z
\frac {dL}{dz}=\frac{dL}{da}\cdot \frac{da}{dz}=(-\frac{y}{a}+\frac{1-y}{1-a})(a(1-a))=a-y=dz
d z d L = d a d L ⋅ d z d a = ( − a y + 1 − a 1 − y ) ( a ( 1 − a ) ) = a − y = d z
d
L
d
w
1
=
d
L
d
z
⋅
d
z
d
w
1
=
d
z
⋅
x
1
=
d
w
1
\frac {dL}{dw_{1}}=\frac{dL}{dz}\cdot \frac{dz}{dw_1}=dz \cdot x_1=dw_1
d w 1 d L = d z d L ⋅ d w 1 d z = d z ⋅ x 1 = d w 1
d
L
d
w
2
=
d
L
d
z
⋅
d
z
d
w
2
=
d
z
⋅
x
2
=
d
w
2
\frac {dL}{dw_{2}}=\frac{dL}{dz}\cdot \frac{dz}{dw_2}=dz \cdot x_2=dw_2
d w 2 d L = d z d L ⋅ d w 2 d z = d z ⋅ x 2 = d w 2
d
L
d
b
=
d
L
d
z
⋅
d
z
d
b
=
d
z
=
d
b
\frac {dL}{db}=\frac{dL}{dz}\cdot \frac{dz}{db}=dz=db
d b d L = d z d L ⋅ d b d z = d z = d b so in single example :
ω
1
:
=
ω
1
−
α
d
z
⋅
x
1
\omega_1:= \omega_1-\alpha dz\cdot x_1
ω 1 : = ω 1 − α d z ⋅ x 1
ω
2
:
=
ω
2
−
α
d
z
⋅
x
2
\omega_2:= \omega_2-\alpha dz\cdot x_2
ω 2 : = ω 2 − α d z ⋅ x 2
b
:
=
b
−
α
d
z
b:= b-\alpha dz
b : = b − α d z
J
(
w
,
b
)
=
1
m
∑
i
=
1
m
L
(
a
(
i
)
,
y
(
i
)
)
,
a
(
i
)
=
y
^
(
i
)
=
σ
(
z
(
i
)
)
=
σ
(
ω
T
x
(
i
)
+
b
)
J(w,b)=\frac{1}{m}\sum_{i=1}^mL(a^{(i)},y^{(i)}), a^{(i)}=\hat{y}^{(i)}=\sigma(z^{(i)})=\sigma(\omega^T x^{(i)}+b)
J ( w , b ) = m 1 i = 1 ∑ m L ( a ( i ) , y ( i ) ) , a ( i ) = y ^ ( i ) = σ ( z ( i ) ) = σ ( ω T x ( i ) + b )
d
J
(
w
1
,
b
)
d
w
1
=
1
m
∑
i
=
1
m
d
L
(
a
(
i
)
,
y
(
i
)
)
d
w
1
=
1
m
∑
i
=
1
m
d
w
1
(
i
)
−
−
u
s
i
n
g
(
x
1
(
i
)
,
y
(
i
)
)
\begin{aligned} \frac{dJ(w_1,b)}{dw_1}=&\frac{1}{m}\sum_{i=1}^m \frac {dL(a^{(i)},y^{(i)})}{dw_1}\\ =&\frac{1}{m}\sum_{i=1}^m dw_1^{(i)} -- using (x_1^{(i)},y^{(i)}) \end{aligned}
d w 1 d J ( w 1 , b ) = = m 1 i = 1 ∑ m d w 1 d L ( a ( i ) , y ( i ) ) m 1 i = 1 ∑ m d w 1 ( i ) − − u s i n g ( x 1 ( i ) , y ( i ) )
J= 0 dw1= 0 dw2= 0 b= 0
for i= 1 to m
z[ i] = w_T* x[ i] + b
a[ i] = sigma( z[ i] )
J[ i] += - [ y[ i] * log( a[ i] ) + ( 1 - y[ i] ) * log( 1 - a[ i] ) ]
dz[ i] = a[ i] - y[ i]
for w in wm
dw[ 1 ] += dz[ i] * x1[ i]
dw[ 2 ] += dz[ i] * x2[ i]
. . .
db += dz[ i]
end
end
dw1= dw1/ m dw2= dw2/ m db= db/ m J= J/ m
There are 2 loops ,less efficiency
⟶
\longrightarrow
⟶ Vectorization
Z
=
ω
T
x
+
b
Z=\omega ^Tx+b
Z = ω T x + b
z= 0
for i in range ( nx) :
z += w[ i] * x[ i]
z = z+ b
vectorization
ω
=
[
.
.
ω
(
i
)
.
.
]
X
=
[
.
.
x
(
i
)
.
.
]
ω
∈
R
n
x
,
x
∈
R
n
x
\omega = \left[ \begin{matrix} . \\ . \\ \omega^{(i)} \\ . \\ . \\ \end{matrix} \right] X = \left[ \begin{matrix} . \\ . \\ x^{(i)} \\ . \\ . \\ \end{matrix} \right] \omega \in R^{n_x},x \in R^{n_x}
ω = ⎣ ⎢ ⎢ ⎢ ⎢ ⎡ . . ω ( i ) . . ⎦ ⎥ ⎥ ⎥ ⎥ ⎤ X = ⎣ ⎢ ⎢ ⎢ ⎢ ⎡ . . x ( i ) . . ⎦ ⎥ ⎥ ⎥ ⎥ ⎤ ω ∈ R n x , x ∈ R n x
dw=np.zeros(n_x,1) x.shape(n_x,1)
so in code
J= 0 b= 0
dw= np. zeros( n_x, 1 )
for i= 1 to m // one loop for x
z[ i] = w_T* x[ i] + b
a[ i] = sigma( z[ i] )
J[ i] += - [ y[ i] * log( a[ i] ) + ( 1 - y[ i] ) * log( 1 - a[ i] ) ]
dz[ i] = a[ i] - y[ i]
dw += dw[ i] * x[ i]
db += dz[ i]
end
dw= dw/ m db= db/ m J= J/ m
z
(
1
)
=
ω
T
x
(
1
)
+
b
,
a
(
1
)
=
σ
(
z
(
1
)
)
z
(
2
)
=
ω
T
x
(
2
)
+
b
,
a
(
2
)
=
σ
(
z
(
2
)
)
.
.
.
z^{(1)}=\omega ^Tx^{(1)}+b ,a^{(1)}=\sigma(z^{(1)})\\ z^{(2)}=\omega ^Tx^{(2)}+b ,a^{(2)}=\sigma(z^{(2)}) \\...
z ( 1 ) = ω T x ( 1 ) + b , a ( 1 ) = σ ( z ( 1 ) ) z ( 2 ) = ω T x ( 2 ) + b , a ( 2 ) = σ ( z ( 2 ) ) . . .
X
=
[
.
.
.
.
.
.
.
.
.
.
x
(
1
)
x
(
2
)
.
.
.
.
.
.
x
(
m
)
.
.
.
.
.
.
.
.
.
.
]
X= \left[ \begin{matrix} . & . & . & . & .\\ . & . & . & . & .\\ x^{(1)} & x^{(2)} & ... & ... & x^{(m)} \\ . & . & . & . & .\\ . & . & . & . & .\\ \end{matrix} \right]
X = ⎣ ⎢ ⎢ ⎢ ⎢ ⎡ . . x ( 1 ) . . . . x ( 2 ) . . . . . . . . . . . . . . . . . . x ( m ) . . ⎦ ⎥ ⎥ ⎥ ⎥ ⎤
Z
=
[
z
(
1
)
,
z
(
2
)
,
z
(
3
)
,
.
.
.
,
z
(
m
)
]
=
ω
T
X
+
[
b
,
b
,
.
.
.
,
b
]
=
[
ω
T
x
(
1
)
+
b
,
ω
T
x
(
2
)
+
b
,
.
.
.
,
ω
T
x
(
m
)
+
b
]
\begin{aligned} Z=&[z^{(1)},z^{(2)},z^{(3)},...,z^{(m)}]\\=&\omega ^{T}X+[b,b,...,b]\\=&[\omega ^{T}x^{(1)}+b,\omega ^{T}x^{(2)}+b,...,\omega ^{T}x^{(m)}+b] \end{aligned}
Z = = = [ z ( 1 ) , z ( 2 ) , z ( 3 ) , . . . , z ( m ) ] ω T X + [ b , b , . . . , b ] [ ω T x ( 1 ) + b , ω T x ( 2 ) + b , . . . , ω T x ( m ) + b ]
Z =np.dot(w.T,x)+b . //python Broadcasting as a vector
d
z
(
i
)
=
a
(
i
)
−
y
(
i
)
,
d
z
=
[
d
z
(
1
)
,
d
z
(
2
)
,
.
.
.
,
d
z
(
m
)
]
,
A
=
[
a
(
1
)
,
a
(
2
)
,
.
.
,
a
(
m
)
]
,
Y
=
[
y
(
1
)
,
y
(
2
)
,
.
.
.
,
y
(
m
)
]
,
d
z
=
A
−
Y
d
b
=
1
m
∑
i
=
1
m
d
z
(
i
)
dz^{(i)}=a^{(i)}-y^{(i)},\\dz=[dz^{(1)},dz^{(2)},...,dz^{(m)}],\\A=[a^{(1)},a^{(2)},..,a^{(m)}],\\Y=[y^{(1)},y^{(2)},...,y^{(m)}] ,\\dz=A-Y\\ db=\frac {1}{m}\sum^m_{i=1} dz^{(i)}
d z ( i ) = a ( i ) − y ( i ) , d z = [ d z ( 1 ) , d z ( 2 ) , . . . , d z ( m ) ] , A = [ a ( 1 ) , a ( 2 ) , . . , a ( m ) ] , Y = [ y ( 1 ) , y ( 2 ) , . . . , y ( m ) ] , d z = A − Y d b = m 1 ∑ i = 1 m d z ( i )
db=np.sum(dz)/m
d
ω
=
1
m
⋅
X
⋅
d
z
T
d\omega=\frac{1}{m} \cdot X \cdot dz^T
d ω = m 1 ⋅ X ⋅ d z T
d
ω
=
1
m
[
.
.
.
.
.
.
.
.
.
.
x
(
1
)
x
(
2
)
.
.
.
.
.
.
x
(
m
)
.
.
.
.
.
.
.
.
.
.
]
⋅
[
d
(
1
)
d
(
2
)
.
.
d
(
m
)
]
=
1
m
[
x
(
1
)
d
z
(
1
)
+
x
(
2
)
d
z
(
2
)
.
.
.
+
x
(
m
)
d
z
(
m
)
]
d\omega=\frac{1}{m} \left[ \begin{matrix} . & . & . & . & .\\ . & . & . & . & .\\ x^{(1)} & x^{(2)} & ... & ... & x^{(m)} \\ . & . & . & . & .\\ . & . & . & . & .\\ \end{matrix} \right] \cdot \left[ \begin{matrix} d^{(1)} \\ d^{(2)} \\ .\\ . \\ d^{(m)} \\ \end{matrix} \right]=\frac{1}{m}[x^{(1)}dz^{(1)}+x^{(2)}dz^{(2)}...+x^{(m)}dz^{(m)}]
d ω = m 1 ⎣ ⎢ ⎢ ⎢ ⎢ ⎡ . . x ( 1 ) . . . . x ( 2 ) . . . . . . . . . . . . . . . . . . x ( m ) . . ⎦ ⎥ ⎥ ⎥ ⎥ ⎤ ⋅ ⎣ ⎢ ⎢ ⎢ ⎢ ⎡ d ( 1 ) d ( 2 ) . . d ( m ) ⎦ ⎥ ⎥ ⎥ ⎥ ⎤ = m 1 [ x ( 1 ) d z ( 1 ) + x ( 2 ) d z ( 2 ) . . . + x ( m ) d z ( m ) ]
for iter in range ( 2000 ) :
z= np. dot( W. T, X) + b
A= sigmoid( z)
dz= A- Y
dw= np. dot( X, dz. T) / m
db= np. sum ( dz) / m
W= W- alpha * dw
b= b- alpha * db