Logistic 回归

Logistic 回归中用到的元素:

Sigmoid函数
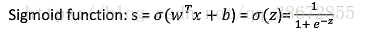
损失函数(衡量了单个训练样本的表现)举例:

我们一般使用第二种损失函数。
成本函数(衡量了全体训练样本上的表现)举例:

梯度下降法:

首先,我们运用“计算图”画一个简单的例子来感受(证明)一下求导中的链式法则:

那么,梯度下降法中,单个样本的损失函数的偏导数怎末求呢?我们依靠链式法则去一步步求:
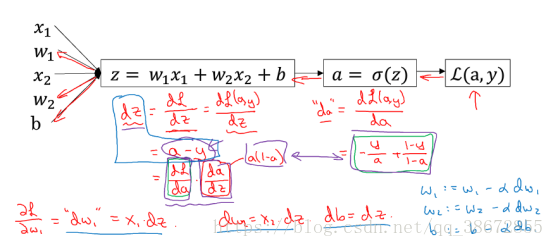
进一步地,所有样本的成本函数(J)的偏导数怎末求呢?我们根据成本函数与损失函数的关系,进行取均值运算即可:

上面的求导过程中的显式FOR循环会降低算法的效率,我们考虑用向量(vector)去优化它。
GPU-图像处理单元;CPU-中央处理器;SIMD-单指令流多数据流。
SIMD可以使得机器并行处理指令;使用vector的函数等内置函数而不是显式FOR循环在底层可充分利用这种并行化,使得程序的速率获得成百倍的提高。因此,应该尽量避免使用显式For循环。
NumPy系统是Python的一种开源的数值计算扩展。这种工具可用来存储和处理大型矩阵,比Python自身的嵌套列表(nested list structure)结构要高效的多(该结构也可以用来表示矩阵(matrix))。
我们抛弃for循环,利用python-numpy库内置的矩阵向量运算函数来高效实现、高效运算梯度下降法(包含正向传播、反向传播):

图中计算矩阵Z的时候,有一个”+b”运算,是由python的”broadcast”(广播)技术实现的。这种技术在优化执行速率时也起着很大的作用。接下来我们研究一下这种技术的细节。
”broadcast”(广播)所做的事情可以看作两步,扩展,然后运算。这使得我们不必写一个for循环去进行这些运算操作,因而提高了coding的速率。”broadcast”(广播)示例如下:

广播等机制灵活而好用,但这也带来了一些缺点。比如你认为应该报错的地方却被成功地运算等等,而引入一些莫名的小错误。在你不能清晰了解其中的内部机制的情况下,这些错误通常是很难debug出来的。这里是一些建议:
1. 不要用“rank 1 array”(秩为1的数组)去表示行向量或列向量;
2. Assert声明、reshape函数几乎是没有运算开销的,所以,尽管使用它们,规范向量的形式,以预防未知错误。
如图:

倒数第二个视频中,介绍了coursera官网上便捷实用的Coursera jupyter ipython用法(类似shell)。
最后一个视频中,简要证明了logistic回归中的成本函数的表达式。(此节待补充...)