前言:以前对SSD算法只有一个比较粗浅的理解,这周为了在组会上讲清楚SSD算法,自己又仔细看了好几遍论文,自己觉得算是抠得比较细的一篇论文了,总结一下。
一、背景
当前基于深度学习的通用目标检测框架主要分为两大类,一类是基于候选区域选择的深度学习目标检测算法,该方法将检测分两步完成,其基本步骤是:第一步生成可能存在目标的区域,第二步将每个该区域都输入分类器中进行分类,去掉置信度较低的候选区域,并修置信度较高的目标区域边框的位置。这类方法的优点是准确率相对高,但缺点是需要运行两次卷积神经网络,运行速度较慢,如 Faster-RCNN
另一类是基于回归方法的深度学习目标检测算法,他们一步到位,其基本步骤是: 给定一张图像, 通过设定合理的输出向量,使用回归的方式输出这个目标的边框和类别,一步到位。这种算法的优点是速度快,但是对于密集的小样本来说检测比较困难。比如 YOLO、SSD 等。
YOlO和SSD算法作为“一步到位”算法的代表,他们的主要区别就是yolo只利用了末端特征图的信息,而SSD利用了最后几层特征图的信息,所以,从理论上说,SSD算法较yolo(起码是yolov1)来说,精确度必然更高。
二、SSD算法是什么
卷积神经网络其实相当于我们人眼通过一个小孔看一张图片。在浅层的神经网络里,我们相当于把这张图片贴着小孔。只能看到图片的细节和纹理信息,就如管中窥豹。随着网络层数的加深,相当于把图片往后移动一段距离。这样才能够感知到图片的整体信息。

其实一些论文里已经证明了这个结论。比如在《Visualizing and Understanding Convolutional Networks》这篇论文中,已经证明了卷积层的前几层主要提取了图像的细节信息,后几层更偏向于图像的抽象信息。

总之,各层特征信息主要有如下区别:
1、低层卷积可以捕捉到更多的细节信息,高层卷积可以捕捉到更多的抽象信息。
2、低层特性更关心“在哪里”,但分类准确度不高,而高层特性更关心“是什么”,但丢失了物体的位置信息。
SSD正是利用不同尺度检测图片中不同大小和类别的目标物体,获得了很好的效果。
三、SSD网络结构
SSD网络结构如下图所示,前端使用VGG16网络,然后在VGG16的基础上新增了5个卷积层来获得更多的特征图以用于检测。

所用到的特征图以及其大小如下表所示:
| feature map | 大小 |
|---|---|
| Conv4_3 | 38*38 |
| Conv7 | 19*19 |
| Conv8_2 | 10*10 |
| Conv9_2 | 5*5 |
| Conv10_2 | 3*3 |
| Conv11_2 | 1*1 |
对于每个特征图来说,SSD引入初始框的概念,也就是说在每个特征图的单元格的中心设置一系列尺度和大小不同的初始框,这些初始框都会反向映射到原图的某一个位置,如果某个初始框的位置正好和真实目标框的位置重叠度很高,那么就通过损失函数预测这个初始框的类别,同时对这些初始框的形状进行微调,以使其符合我们标记的真实目标框。


四、初始框的设置
初始框主要有两个参数:尺度Scale和长宽比a。
对于不同的特征图,SSD总的尺度设计原则就是:随着网络层数加深(特征图的变小),初始框的尺度线性增加。最小的初始框尺度为0.2,最大的初始框尺度为0.9。
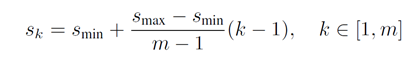
这样,每个特征图上的初始框尺度如下表:

【注:这是论文中的描述方法,实际给出的官方源码中,SSD貌似将第一个特征图的初始框单独设置为0.1的尺度,剩下的采用以下公式,而且每个特征图上的尺度稍微有微调,网上也有各种解释版本,感兴趣的话可以看源码。】
对于长宽比,作者直接采用了
五种比例,这样,每个特征图上的初始框长、宽可以用以下公式得出:
对于比例为1的初始框,作者又多增加了一个正方形的初始框:
五、训练过程
1、执行步骤
(1)生成初始框
按照上述初始框生成规则在每个特征图的单元格中心生成初始框即可,这个步骤无需利用输入训练图像数据。
(2)先验框匹配
在训练过程中,首先要确定训练图片中的目标真实框与哪个先验框来进行匹配,与之匹配的先验框所对应的边界框将负责预测它。若某个真实框和初始框的IOU大于某个阈值(一般是0.5),那么该初始框就与这个真实框进行匹配。能够与真实目标框匹配的初始框就是正样本,其他的都是负样本。
(3)计算损失值
根据真实目标框的类别以及初始框相对于目标框的偏移,计算损失值。
损失函数如下,
为两个损失函数的连接权重:
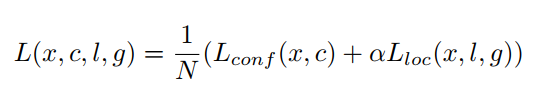
其中,
为类别损失,公式表示如下:
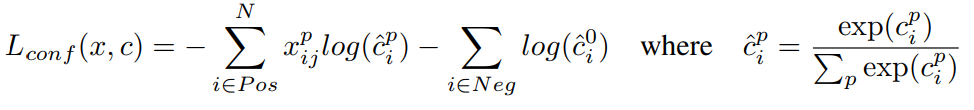
可以看到本质上就是个softmax损失函数,只是需要注意的是,如果要预测N个类别,那么需要有N+1个输出,多出的那个类别是背景类别。
为位置损失,公式表示如下:
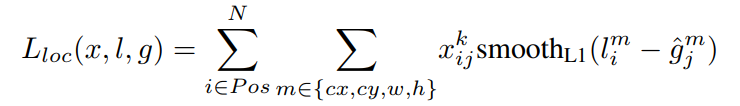
其中,
,是一个枚举变量,如果某个初始框可以和真是目标框进行匹配,那么这个值为1,否则为0.

2、训练过程的问题
在一张图片中目标的个数一般不会太多,而在上述训练过程中,会产生8000多个初始框,所以能和真实目标框匹配的初始框非常少,这样导致正样本的个数远远小于负样本的个数,导致训练收敛困难。
(2)减少负样本的个数。尽管使用了(1)来尽量增加正样本的个数,但是真实目标框相对初始框来说数量还是少了太多,所以负样本相对正样本还是会很多。为了保证正负样本尽量平衡,我们删除一部分负样本。具体做法是:将执行完(1)之后剩余的初始框按照背景置信度做一个排序,只选取置信度最高的几个框来计算损失函数,丢弃掉剩余的负样本初始框。保证负样本和正样本的比例最高不超过 3:1。
预测过程
预测过程比较简单,首先将待预测的图片输入网络,将初始框根据输出的目标类别和偏移量进行对应调整,得到预测框,并根据类别置信度确定其类别,过滤掉属于背景的预测框。然后根据置信度阈值(如0.5)过滤掉阈值较低的预测框。对于留下的预测框执行NMS算法,过滤掉那些重叠度较大的预测框。最后剩余的预测框就是检测结果了。
六、实验
1、验证性实验
因为深度学习本来就是个凭经验调(lian)参(dan)的过程,作者设计的一些结构,可能真的是一拍脑袋想出来的,但是,好歹得证明这样设计有优势吧,所以,先是做了几组验证性实验。
(1)1:2,1:3比例的初始框对模型精确度的影响
作者的验证方法是:逐渐移除1:3,1:2的初始框,观察模型的表现效果。

可以看到,移除1:3的初始框之后,模型进度大约降了0.6个百分点,进一步移除1:2的初始框之后,模型精度又降了2.1个百分点,充分证明不同大小比例初始框的设置对模型精度有很大的影响。
(2)不同尺度特征图对模型精确度的影响
通过逐渐移除特征图来测试不同特征图对模型精度的影响。作者为了公平起见,就算移除了某一个特征图,也会在其他特征图上补充一些初始框,保证了所有模型的总初始框的个数几乎相同。

可以看到,随着用于检测的特征图逐渐减少,模型精度从74.3%降到62.4%,说明利用多尺度特征图信息来检测确实可以提高模型精度。这里,可以发现,移除conv11_2特征图之后,模型精度反倒上升了,作者给出的解释是:因为这个特征图上放置着实际大小是270*270左右的初始框,训练集中并没有这么大的错误,导致反倒引入了一些错误。(这也进一步说明初始框的大小设置对模型精度影响很大)。
2、与其他算法的比较
这是与Fast-RCNN和Faster-RCNN在不同目标物体上的识别精度的一个比较。

SSD和Faster-RCNN的精度几乎不相上下。
这是两者速度方面的一个比较,可以看到,SSD有明显的速度优势,而且也是唯一一个MAP超过70%的实时检测算法。

七、写在最后
SSD论文和实际源码有一些区别,尤其是在初始框选择那一部分,本文主要以论文为主进行解读,其实尤其是计算机领域这种更偏向于实用类的论文,有些思想还是很难写出来的,如果能够找到源码,还是需要多体会源码,才能更好地理解这个算法。如果有出入,那么以作者的源码为准。我只跑过类SSD算法,以后有机会,再通过源码来体会SSD的奇妙吧。
最后,衷心佩服作者的这个新奇的思想,只是2016年之后原作者没有什么更加创新性的改进,YOLO都更新到V3版了,RCNN系列也有第三代了,SSD作者要加油鸭。

