一、pandas的两大数据类型
Series:一维数组,与Numpy中的一维array类似。二者与Python基本的数据结构List也很相近,其区别是:List中的元素可以是不同的数据类型,而Array和Series中则只允许存储相同的数据类型,这样可以更有效的使用内存,提高运算效率。
Time- Series:以时间为索引的Series。
DataFrame:就是二维的Series。
Panel :三维的数组,可以理解为DataFrame的容器。
在实际使用中,DataFrame是使用最多的一种数据类型。
二、pandas的增删改查操作
一)增——创建一个DataFrame向量
1、根据字典创造:
import pandas as pd
aa={'张三':[1,2,3],'李四':[2,3,4],'王五':[3,4,5]}#线创建一个字典类型
bb=pd.DataFrame(aa)#把字典类型转换成DataFrame类型
print(bb)结果显示如下:

字典中的keys就是DataFrame里面的columns,这里没有指定index的值,所以默认是从零开始计数。
2、从多维数组中创建
思路就是,首先建立一个多维数组,然后为这个数组指定表头(列名)
a=np.array([[1,2,3],[4,5,6],[7,8,9]])
b=pd.DataFrame(a,index=['first','second','third'],columns=['张三','李四','王五'])
print(b)结果显示如下:
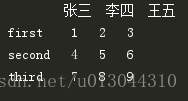
二)改——在原Dataframe数据中新增一列
1、只需要按照添加字典的方式添加即可,但是要注意:①添加维数要和原有的维数相同,否则会报错;②依次智能添加一个
b['赵六']=[8,8,8]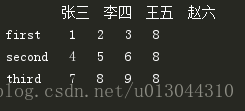
2、joint
三)改——在原Dataframe数据中新增一行
1、df.loc[df.shape[0]+1] = ['元素1','元素2','元素3']
四)改——更改原Dataframe数据的列名
c = b.rename(columns={'王五': '王麻子'}) #选择性更改列名
print(c)
五)改——将两个Dataframe数据合并
【参考:Pandas 合并数据集http://blog.csdn.net/u010414589/article/details/51135840】
concat(objs,axis=0,join='outer',join_axes=None,ignore_index=False,keys=None,levels=None,names=None,verigy_integrity=False)- objs 是需要拼接的对象集合,一般为列表或者字典
- axis=0 是行拼接,拼接之后行数增加,列数也根据join来定,join=’outer’时,列数是两表并集。同理join=’inner’,列数是两表交集。
六)查
在这点上,pandas拥有类似数据库的查询方式,除了与数据库主键的机制有些许不一样外,其他的度非常相似,可谓占尽数据库的优点。
1、通过列查询
2、通过行查询
3、返回某一个列中的出现次数
count = df['列名'].value_counts()
属性:1)normalize = True显示的是频率,默认为False。
2)sort : 布尔值,默认为True.排序控制.
3)ascending : 布尔值,默认为False,以升序排序 。
另外,若只想显示出现频数最到的一项,可以print(count[0]).
三、pandas的数值分析
在这一方面,pandas又妥妥化身为一个excel表格(或者说matlab中的矩阵),可以对数据进行各种姿势的统计(这也是其在大数据中大量运用的一个重要原因)。
在数值分析中,有一下几个函数,
- df.describe():查看数据值列的汇总统计
- df.mean():返回所有列的均值
- df.corr():返回列与列之间的相关系数
- df.count():返回每一列中的非空值的个数
- df.max():返回每一列的最大值
- df.min():返回每一列的最小值
- df.median():返回每一列的中位数
下面展示一个执行df.mean()的前后对比:
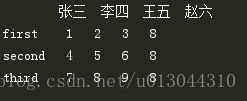
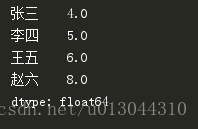
四、pandas的索引操作。
一)重新命名某一行的索引值。
1、df =df.rename_axis({原索引值1:更新后的索引值1,原索引值2:更新后的索引值2})
2、df = df.rename(index = {原索引值1:更新后的索引值1,原索引值2:更新后的索引值2})
五、pandas与其他数据的输入输出。
一)pandas与excel格式文件的转化
1、读取excel中的文件。首先,我们建立一个excel表格,内容如下,命名为“1.xlsx”
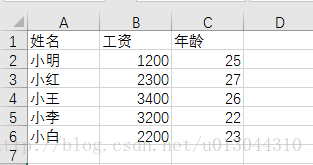
a = pd.read_excel("./biaoge/1.xlsx",sheet_name=0) #sheet_name表示文件中的第几个sheet,默认为0
print(a)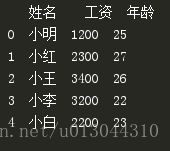
另外,还有几个属性需要关注:
1)index_col
2)na_vales
2、写入excel文件:我们继续接着上边的程序,把读出的数据写入另一个excel中,为了区别,在写入之前用concat函数插入两行数据。代码如下:
a = pd.read_excel("./biaoge/1.xlsx",sheet_name=0) #sheet_name表示文件中的第几个sheet,默认为0
b = np.array([['张三',1000,18],['李四',2000,81]])
bb = pd.DataFrame(b,columns=['姓名','工资','年龄'])
a = pd.concat([a, bb])
print(a)
#写入excel文件。
# 属性:index=None可以去掉索引 header=None可以去掉表头
a.to_excel('2.xlsx', sheet_name = 'sheet1')输出如下:
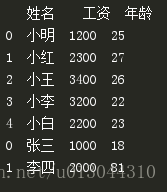
打开“2.xlsx”文件,可以看到,数据已经写入。
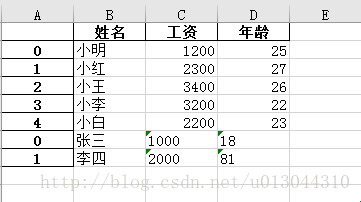
但是,慢着!我们注意到左侧多了一行数据的索引列,如果不需要的话,可以把最后一行函数加上一个属性index=None,即:
a.to_excel('2.xlsx', sheet_name = 'sheet1',index=None)这样就好看多了。

注:因为我们添加数据的时候工资列和年龄列都是数字格式,所以在写入表格后在excel中显示的也是数据格式,不需要的可以在程序中加双引号
二)pandas与CSV格式文件的转化
与读写Excel文件的方式相对应,在读入时执行:
a = pd.read_csv("./biaoge/1.csv")其中,这条语句可以添加两个可选参数:
- header=None:表示头部为空
- sep=' ' :表示数据间使用空格作为分隔符,如果分隔符是逗号,只需换成 ‘,’即可
在写入时只需要:
a.to_csv('2.csv',index=None)即可。
关于Pandas其他函数,可查询这个网址:
最后,奉上一个官方快速入门文档:十分钟入门pandas的官方文档(英文)
