有情怀,有干货,微信搜索【荒古传说】关注这个不一样的程序员。
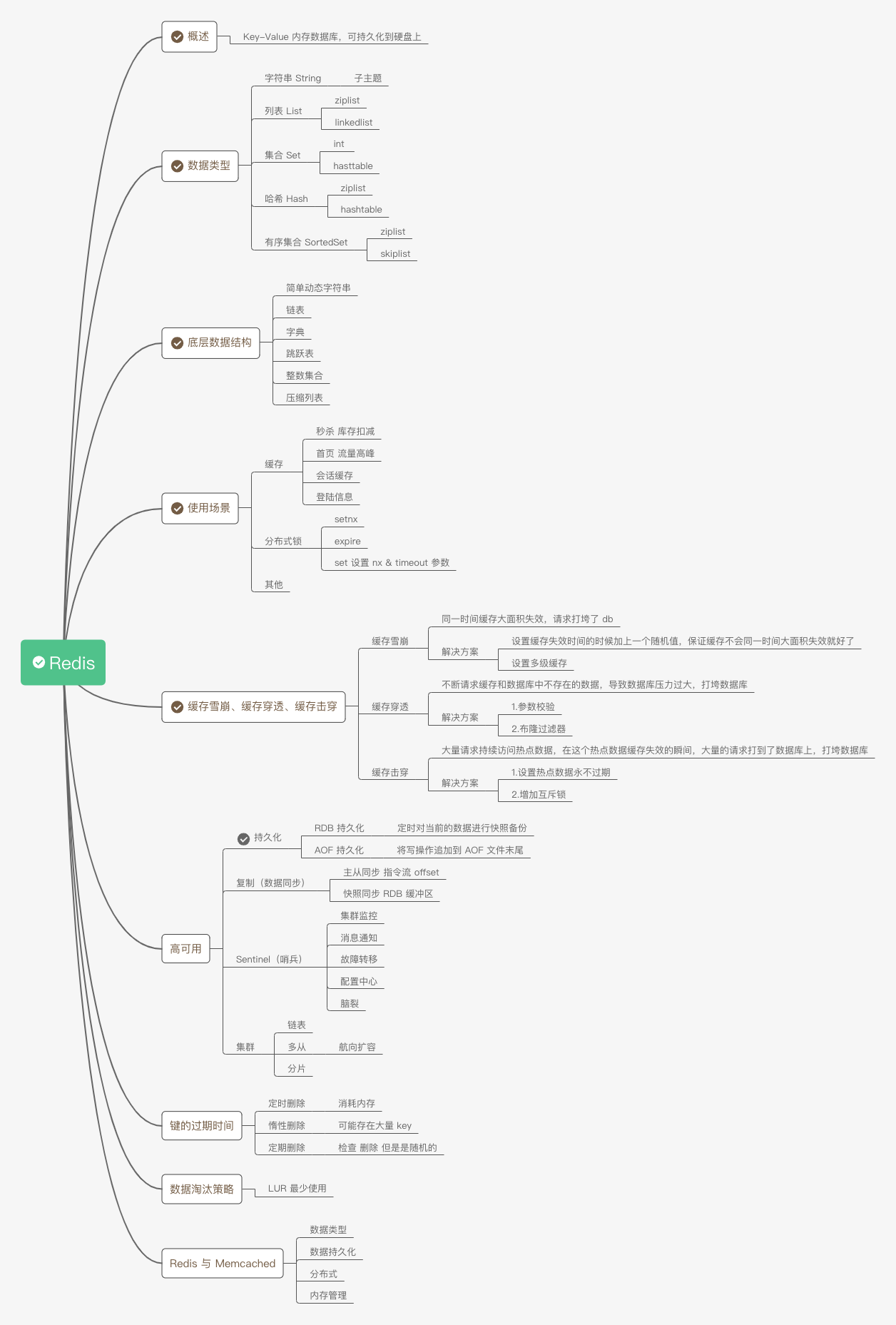
概述
Redis 是一个 key-value 内存数据库,可持久化到硬盘上。健的类型只能是字符串,但是值的类型可以是字符串、列表、哈希表、集合、有序集合。
数据类型
Redis 的数据类型有5种,分别是:字符串、列表、哈希表、集合、有序集合。
Redis 的编码(底层实现)有8种,分别是:long 类型的整数、embstr 编码的简单动态字符串、简单动态字符串、字典、双端链表、压缩列表、整数集合、跳跃表和字典。
字符串

字符串对象的编码可以是 int、raw 或者 embstr。
如果一个字符串对象保存的是整数值,并且这个整数值可以用 long 类型来表示,那么字符串对象会将整数值保存在字符串对象结构的 ptr 属性里面(将 void* 转换成 long),并将字符串对象的编码设置为 int。
如果字符串对象保存的是一个字符串值,并且这个字符串值的长度大于39字节,那么字符串对象将使用一个简单动态字符串(SDS)来保存这个字符串值,并将对象的编码设置为raw。
如果字符串对象保存的是一个字符串值,并且这个字符串值的长度小于等于39字节,那么字符串对象将使用 embstr 编码的方式来保存这个字符串值。
> set hello world
OK
> get hello
"world"
> del hello
(integer) 1
> get hello
(nil)
列表
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-xhOv3PHP-1603168774635)(https://raw.githubusercontent.com/haxianhe/pic/master/image/20200513150726.png)]
列表对象的编码可以是 ziplist 或者 linkedlist。
ziplist 编码的列表对象使用压缩列表作为底层实现,每个压缩列表节点保存了一个列表元素。
linkedlist 编码的列表对象使用双端链表作为底层实现,每个双端链表节点都保存了一个字符串对象,而每个字符串对象都保存了一个列表元素。
> rpush list-key item
(integer) 1
> rpush list-key item2
(integer) 2
> rpush list-key item
(integer) 3
> lrange list-key 0 -1
1) "item"
2) "item2"
3) "item"
> lindex list-key 1
"item2"
> lpop list-key
"item"
> lrange list-key 0 -1
1) "item2"
2) "item"
集合
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-YecB5kUU-1603168774637)(https://raw.githubusercontent.com/haxianhe/pic/master/image/20200513161259.png)]
集合对象的编码可以是 intset 或者 hashtable。
intset 编码的集合对象使用整数集合作为底层实现。
hashtable 编码的集合对象使用字典作为底层实现,字典的每个键都是一个字符串对象,每个字符串对象包含了一个集合元素,而字典的值则全部被设置为 NULL。
> sadd set-key item
(integer) 1
> sadd set-key item2
(integer) 1
> sadd set-key item3
(integer) 1
> sadd set-key item
(integer) 0
> smembers set-key
1) "item"
2) "item2"
3) "item3"
> sismember set-key item4
(integer) 0
> sismember set-key item
(integer) 1
> srem set-key item2
(integer) 1
> srem set-key item2
(integer) 0
> smembers set-key
1) "item"
2) "item3"
哈希

哈希对象的编码可以是 ziplist 或者 hashtable。
ziplist 编码的哈希对象使用压缩列表作为底层实现,每当有新的健值对要加入到哈希对象时,程序会先将保存了键的压缩列表节点推入到压缩列表表尾,然后再将保存了值的压缩列表节点推入到压缩列表表尾。
hashtable 编码的哈希对象使用字典作为底层实现,哈希对象中的每个键值对都适用一个字典键值对来保存。
> hset hash-key sub-key1 value1
(integer) 1
> hset hash-key sub-key2 value2
(integer) 1
> hset hash-key sub-key1 value1
(integer) 0
> hgetall hash-key
1) "sub-key1"
2) "value1"
3) "sub-key2"
4) "value2"
> hdel hash-key sub-key2
(integer) 1
> hdel hash-key sub-key2
(integer) 0
> hget hash-key sub-key1
"value1"
> hgetall hash-key
1) "sub-key1"
2) "value1"
有序集合
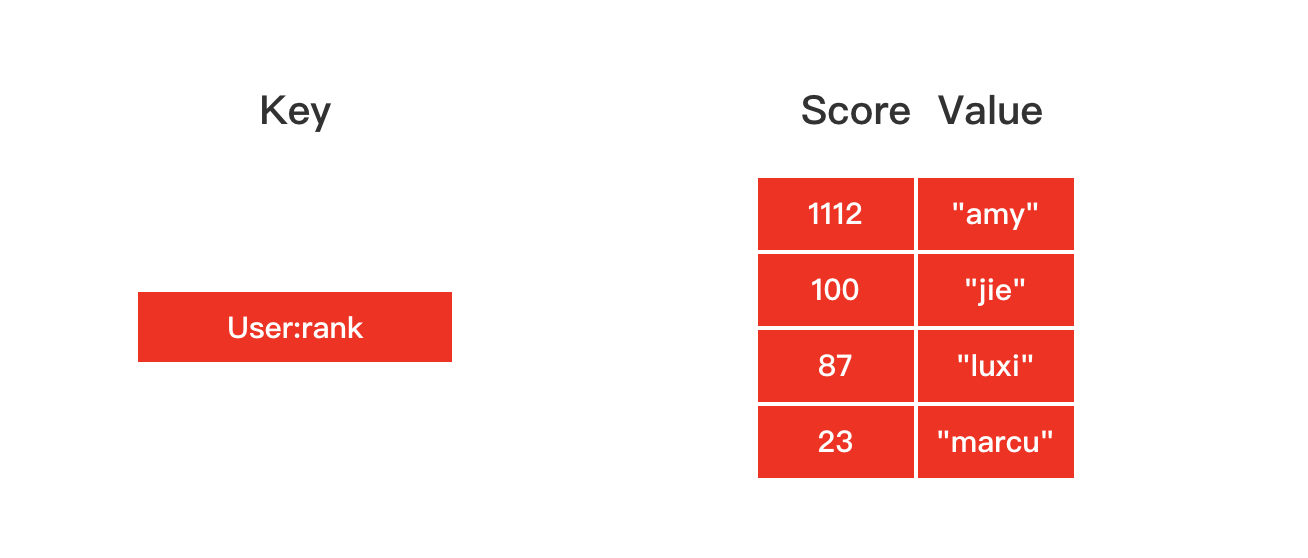
有序集合对象的编码可以是 ziplist 或者 skiplist。
ziplist 编码的有序集合对象使用压缩列表作为底层实现,每个集合元素使用两个挨在一起的压缩列表节点来保存,第一个节点保存元素的成员,第二个节点保存元素的分值。
skiplist 编码的有序集合对象使用 zset 结构作为底层实现,一个 zset 结构同事包含一个字典和一个跳跃表。
> zadd zset-key 728 member1
(integer) 1
> zadd zset-key 982 member0
(integer) 1
> zadd zset-key 982 member0
(integer) 0
> zrange zset-key 0 -1 withscores
1) "member1"
2) "728"
3) "member0"
4) "982"
> zrangebyscore zset-key 0 800 withscores
1) "member1"
2) "728"
> zrem zset-key member1
(integer) 1
> zrem zset-key member1
(integer) 0
> zrange zset-key 0 -1 withscores
1) "member0"
2) "982"
底层数据结构
简单动态字符串
struct sdshdr {
// 记录 buf 数组中已使用字节的数量
// 等于 SDS 所保存字符串的长度
int len;
// 记录 buf 数组中未使用字节的数量
int free;
// 字节数组,用于保存字符串
char buf[];
};
图 2-1 展示了一个 SDS 示例:
- free 属性的值为 0 , 表示这个 SDS 没有分配任何未使用空间。
- len 属性的值为 5 , 表示这个 SDS 保存了一个五字节长的字符串。
- buf 属性是一个 char 类型的数组, 数组的前五个字节分别保存了 ‘R’ 、 ‘e’ 、 ‘d’ 、 ‘i’ 、 ‘s’ 五个字符, 而最后一个字节则保存了空字符 ‘\0’ 。
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-ax80qTIF-1603168774641)(https://raw.githubusercontent.com/haxianhe/pic/master/image/20200506153334.png)]
链表
每个链表节点使用一个 adlist.h/listNode 结构来表示:
typedef struct listNode {
// 前置节点
struct listNode *prev;
// 后置节点
struct listNode *next;
// 节点的值
void *value;
} listNode;
多个 listNode 可以通过 prev 和 next 指针组成双端链表, 如图 3-1 所示。

Redis 的链表实现的特性可以总结如下:
- 双端: 链表节点带有 prev 和 next 指针, 获取某个节点的前置节点和后置节点的复杂度都是 O(1) 。
- 无环: 表头节点的 prev 指针和表尾节点的 next 指针都指向 NULL , 对链表的访问以 NULL 为终点。
- 带表头指针和表尾指针: 通过 list 结构的 head 指针和 tail 指针, 程序获取链表的表头节点和表尾节点的复杂度为 O(1) 。
- 带链表长度计数器: 程序使用 list 结构的 len 属性来对 list 持有的链表节点进行计数, 程序获取链表中节点数量的复杂度为 O(1) 。
- 多态: 链表节点使用 void* 指针来保存节点值, 并且可以通过 list 结构的 dup 、 free 、 match 三个属性为节点值设置类型特定函数, 所以链表可以用于保存各种不同类型的值。
字典
dictht 是一个散列表结构,使用拉链法解决哈希冲突。
/* This is our hash table structure. Every dictionary has two of this as we
* implement incremental rehashing, for the old to the new table. */
typedef struct dictht {
dictEntry **table;
unsigned long size;
unsigned long sizemask;
unsigned long used;
} dictht;
typedef struct dictEntry {
void *key;
union {
void *val;
uint64_t u64;
int64_t s64;
double d;
} v;
struct dictEntry *next;
} dictEntry;
Redis 的字典 dict 中包含两个哈希表 dictht,这是为了方便进行 rehash 操作。在扩容时,将其中一个 dictht 上的键值对 rehash 到另一个 dictht 上面,完成之后释放空间并交换两个 dictht 的角色。
typedef struct dict {
dictType *type;
void *privdata;
dictht ht[2];
long rehashidx; /* rehashing not in progress if rehashidx == -1 */
unsigned long iterators; /* number of iterators currently running */
} dict;
rehash 操作不是一次性完成,而是采用渐进方式,这是为了避免一次性执行过多的 rehash 操作给服务器带来过大的负担。
渐进式 rehash 通过记录 dict 的 rehashidx 完成,它从 0 开始,然后每执行一次 rehash 都会递增。例如在一次 rehash 中,要把 dict[0] rehash 到 dict[1],这一次会把 dict[0] 上 table[rehashidx] 的键值对 rehash 到 dict[1] 上,dict[0] 的 table[rehashidx] 指向 null,并令 rehashidx++。
在 rehash 期间,每次对字典执行添加、删除、查找或者更新操作时,都会执行一次渐进式 rehash。
采用渐进式 rehash 会导致字典中的数据分散在两个 dictht 上,因此对字典的查找操作也需要到对应的 dictht 去执行。
/* Performs N steps of incremental rehashing. Returns 1 if there are still
* keys to move from the old to the new hash table, otherwise 0 is returned.
*
* Note that a rehashing step consists in moving a bucket (that may have more
* than one key as we use chaining) from the old to the new hash table, however
* since part of the hash table may be composed of empty spaces, it is not
* guaranteed that this function will rehash even a single bucket, since it
* will visit at max N*10 empty buckets in total, otherwise the amount of
* work it does would be unbound and the function may block for a long time. */
int dictRehash(dict *d, int n) {
int empty_visits = n * 10; /* Max number of empty buckets to visit. */
if (!dictIsRehashing(d)) return 0;
while (n-- && d->ht[0].used != 0) {
dictEntry *de, *nextde;
/* Note that rehashidx can't overflow as we are sure there are more
* elements because ht[0].used != 0 */
assert(d->ht[0].size > (unsigned long) d->rehashidx);
while (d->ht[0].table[d->rehashidx] == NULL) {
d->rehashidx++;
if (--empty_visits == 0) return 1;
}
de = d->ht[0].table[d->rehashidx];
/* Move all the keys in this bucket from the old to the new hash HT */
while (de) {
uint64_t h;
nextde = de->next;
/* Get the index in the new hash table */
h = dictHashKey(d, de->key) & d->ht[1].sizemask;
de->next = d->ht[1].table[h];
d->ht[1].table[h] = de;
d->ht[0].used--;
d->ht[1].used++;
de = nextde;
}
d->ht[0].table[d->rehashidx] = NULL;
d->rehashidx++;
}
/* Check if we already rehashed the whole table... */
if (d->ht[0].used == 0) {
zfree(d->ht[0].table);
d->ht[0] = d->ht[1];
_dictReset(&d->ht[1]);
d->rehashidx = -1;
return 0;
}
/* More to rehash... */
return 1;
}
跳跃表
是有序集合的底层实现之一。
跳跃表是基于多指针有序链表实现的,可以看成多个有序链表。
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-kflaiIwR-1603168774642)(https://raw.githubusercontent.com/haxianhe/pic/master/image/20200506154158.png)]
在查找时,从上层指针开始查找,找到对应的区间之后再到下一层去查找。下图演示了查找 22 的过程。
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-ucObpoFV-1603168774643)(https://raw.githubusercontent.com/haxianhe/pic/master/image/20200506154222.png)]
与红黑树等平衡树相比,跳跃表具有以下优点:
- 插入速度非常快速,因为不需要进行旋转等操作来维护平衡性;
- 更容易实现;
- 支持无锁操作。
整数集合
整数集合(intset)是 Redis 用于保存整数值的集合抽象数据结构, 它可以保存类型为 int16_t 、 int32_t 或者 int64_t 的整数值, 并且保证集合中不会出现重复元素。
每个 intset.h/intset 结构表示一个整数集合:
typedef struct intset {
// 编码方式
uint32_t encoding;
// 集合包含的元素数量
uint32_t length;
// 保存元素的数组
int8_t contents[];
} intset;
图 6-1 展示了一个整数集合示例:
- encoding 属性的值为 INTSET_ENC_INT16 , 表示整数集合的底层实现为 int16_t 类型的数组, 而集合保存的都是 int16_t 类型的整数值。
- length 属性的值为 5 , 表示整数集合包含五个元素。
- contents 数组按从小到大的顺序保存着集合中的五个元素。
因为每个集合元素都是 int16_t 类型的整数值, 所以 contents 数组的大小等于 sizeof(int16_t) * 5 = 16 * 5 = 80 位。
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-I3RXVvul-1603168774644)(https://raw.githubusercontent.com/haxianhe/pic/master/image/20200506154613.png)]
压缩列表
压缩列表是 Redis 为了节约内存而开发的, 由一系列特殊编码的连续内存块组成的顺序型(sequential)数据结构。
一个压缩列表可以包含任意多个节点(entry), 每个节点可以保存一个字节数组或者一个整数值。
图 7-1 展示了压缩列表的各个组成部分, 表 7-1 则记录了各个组成部分的类型、长度、以及用途。
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-SiOPfejX-1603168774644)(https://raw.githubusercontent.com/haxianhe/pic/master/image/20200506154718.png)]
图 7-2 展示了一个压缩列表示例:
- 列表 zlbytes 属性的值为 0x50 (十进制 80), 表示压缩列表的总长为 80 字节。
- 列表 zltail 属性的值为 0x3c (十进制 60), 这表示如果我们有一个指向压缩列表起始地址的指针 p , 那么只要用指针 p 加上偏移量 60 , 就可以计算出表尾节点 entry3 的地址。
- 列表 zllen 属性的值为 0x3 (十进制 3), 表示压缩列表包含三个节点。
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-zalMscrT-1603168774645)(https://raw.githubusercontent.com/haxianhe/pic/master/image/20200506154848.png)]
使用场景
缓存
将热点数据放到内存中,设置内存的最大使用量以及淘汰策略来保证缓存的命中率。
秒杀 扣减库存
首页 流量高峰
会话缓存
可以使用 Redis 来统一存储多台应用服务器的会话信息。
当应用服务器不再存储用户的会话信息,也就不再具有状态,一个用户可以请求任意一个应用服务器,从而更容易实现高可用性以及可伸缩性。
登陆信息
可以使用 Redis 来缓存用户的登陆信息。
分布式锁
在分布式场景下,无法使用单机环境下的锁来对多个节点上的进程进行同步。
可以使用 Redis 自带的 SETNX 命令实现分布式锁,先拿 setnx 来争抢锁,抢到之后,再用 expire 给锁加一个过期时间防止锁忘记了释放。
如果在setnx之后执行expire之前进程意外crash或者要重启维护了,那会怎么样?
可以给 set 设置 nx 和 timeout 参数,将 setnx 和 expire 和成一条命令使用。
其它
Set 可以实现交集、并集等操作,从而实现共同好友等功能。
ZSet 可以实现有序性操作,从而实现排行榜等功能。
缓存雪崩、缓存穿透、缓存击穿
缓存雪崩
同一时间缓存大面积失效,请求打垮 DB
解决方案:
- 设置缓存时间视角的时候加上一个随机值,保证缓存不会同一时间大面积失效
- 设置多级缓存
缓存穿透
不断请求缓存和数据库中不存在的数据,导致数据库压力过大,打垮数据库
解决方案:
- 参数校验
- 布隆过滤器
缓存击穿
大量请求持续访问热点数据,在这个热点数据缓存失效的瞬间,大量请求打到了数据库上,打垮数据库
解决方案;
- 设置热点数据永不过期
- 增加互斥锁
高可用
持久化
Redis 是内存型数据库,为了保证数据在断电后不会丢失,需要将内存中的数据持久化到硬盘上。
The RDB persistence performs point-in-time snapshots of your dataset at specified intervals.
The AOF persistence logs every write operation received by the server, that will be played again at server startup, reconstructing the original dataset. Commands are logged using the same format as the Redis protocol itself, in an append-only fashion. Redis is able to rewrite the log in the background when it gets too big.
RDB 持久化
工作原理
Redis 调用 fork(),产生一个子进程,子进程把数据写入到一个临时文件,当子进程写完新的 RDB 文件后,把旧的 RDB 文件替换掉。
优点
- RDB is a very compact single-file point-in-time representation of your Redis data. RDB files are perfect for backups. For instance you may want to archive your RDB files every hour for the latest 24 hours, and to save an RDB snapshot every day for 30 days. This allows you to easily restore different versions of the data set in case of disasters.
- RDB is very good for disaster recovery, being a single compact file that can be transferred to far data centers, or onto Amazon S3 (possibly encrypted).
- RDB maximizes Redis performances since the only work the Redis parent process needs to do in order to persist is forking a child that will do all the rest. The parent instance will never perform disk I/O or alike.
- RDB allows faster restarts with big datasets compared to AOF.
RDB 持久化很适合做备份。
缺点
- RDB is NOT good if you need to minimize the chance of data loss in case Redis stops working (for example after a power outage). You can configure different save points where an RDB is produced (for instance after at least five minutes and 100 writes against the data set, but you can have multiple save points). However you’ll usually create an RDB snapshot every five minutes or more, so in case of Redis stopping working without a correct shutdown for any reason you should be prepared to lose the latest minutes of data.
- RDB needs to fork() often in order to persist on disk using a child process. Fork() can be time consuming if the dataset is big, and may result in Redis to stop serving clients for some millisecond or even for one second if the dataset is very big and the CPU performance not great. AOF also needs to fork() but you can tune how often you want to rewrite your logs without any trade-off on durability.
-
如果系统发生故障,将会丢失最后一次创建快照之后的数据。
-
RDB 使用 fork() 产生子进程进行数据的持久化,如果数据比较大的话可能就会花费点时间,造成Redis停止服务几毫秒。如果数据量很大且 CPU 性能不是很好的时候,停止服务的时间甚至会到1秒。
AOF 持久化
工作原理
将写命令添加到 AOF 文件(Append Only File)的末尾。
使用 AOF 持久化需要设置同步选项,从而确保写命令同步到磁盘文件上的时机。这是因为对文件进行写入并不会马上将内容同步到磁盘上,而是先存储到缓冲区,然后由操作系统决定什么时候同步到磁盘。有以下同步选项:
| 选项 | 同步频率 |
|---|---|
| always | 每个写命令都同步 |
| everysec | 每秒同步一次 |
| no | 让操作系统来决定何时同步 |
- always 选项会严重减低服务器的性能;
- everysec 选项比较合适,可以保证系统崩溃时只会丢失一秒左右的数据,并且 Redis 每秒执行一次同步对服务器性能几乎没有任何影响;
- no 选项并不能给服务器性能带来多大的提升,而且也会增加系统崩溃时数据丢失的数量。
随着服务器写请求的增多,AOF 文件会越来越大。Redis 提供了一种将 AOF 重写的特性,能够去除 AOF 文件中的冗余写命令。
优点
- Using AOF Redis is much more durable: you can have different fsync policies: no fsync at all, fsync every second, fsync at every query. With the default policy of fsync every second write performances are still great (fsync is performed using a background thread and the main thread will try hard to perform writes when no fsync is in progress.) but you can only lose one second worth of writes.
- The AOF log is an append only log, so there are no seeks, nor corruption problems if there is a power outage. Even if the log ends with an half-written command for some reason (disk full or other reasons) the redis-check-aof tool is able to fix it easily.
- Redis is able to automatically rewrite the AOF in background when it gets too big. The rewrite is completely safe as while Redis continues appending to the old file, a completely new one is produced with the minimal set of operations needed to create the current data set, and once this second file is ready Redis switches the two and starts appending to the new one.
- AOF contains a log of all the operations one after the other in an easy to understand and parse format. You can even easily export an AOF file. For instance even if you flushed everything for an error using a FLUSHALL command, if no rewrite of the log was performed in the meantime you can still save your data set just stopping the server, removing the latest command, and restarting Redis again.
- 如果需要恢复数据,丢失的数据更少(丢失多少取决于同步策略)
- 当AOF文件太大时,Redis会自动在后台进行重写
缺点
- AOF files are usually bigger than the equivalent RDB files for the same dataset.
- AOF can be slower than RDB depending on the exact fsync policy. In general with fsync set to every second performance is still very high, and with fsync disabled it should be exactly as fast as RDB even under high load. Still RDB is able to provide more guarantees about the maximum latency even in the case of an huge write load.
- AOF 文件比 RDB 文件更大
- AOF 持久化比 RDB 持久化更耗时。
使用建议
The general indication is that you should use both persistence methods if you want a degree of data safety comparable to what PostgreSQL can provide you.
If you care a lot about your data, but still can live with a few minutes of data loss in case of disasters, you can simply use RDB alone.
There are many users using AOF alone, but we discourage it since to have an RDB snapshot from time to time is a great idea for doing database backups, for faster restarts, and in the event of bugs in the AOF engine.
Note: for all these reasons we’ll likely end up unifying AOF and RDB into a single persistence model in the future (long term plan).
- 如果为了保证数据的安全性达到最高就两者都用
- 如果可以接受损失几分钟的数据就只需要使用 RDB 进行持久化就好了
- 不建议单独使用 AOF 进行持久化
参考资料
- Bloom Filters by Example
- Redis 布隆过滤器实战「缓存击穿、雪崩效应」
- Redis 布隆过滤器的使用及注意事项
- CS-Notes-redis
- JavaFamily-redis
- Redis Persistence
文章持续更新,可以微信搜一搜「 荒古传说 」第一时间阅读。