用python爬取动态网页时,普通的requests,urllib2无法实现。例如有些网站点击下一页时,会加载新的内容,但是网页的URL却没有改变(没有传入页码相关的参数),requests、urllib2无法抓取这些动态加载的内容,此时就需要使用Selenium了。

使用Selenium需要选择一个调用的浏览器并下载好对应的驱动,我使用的是Chrome浏览器。
将下载好的chromedrive.exe文件复制到系统路径:E:\python\Scripts下,如果安装python的时候打path勾的话这个目录就会配置到系统path里了,如果没有的话,请手动把这个路径添加到path路径下。
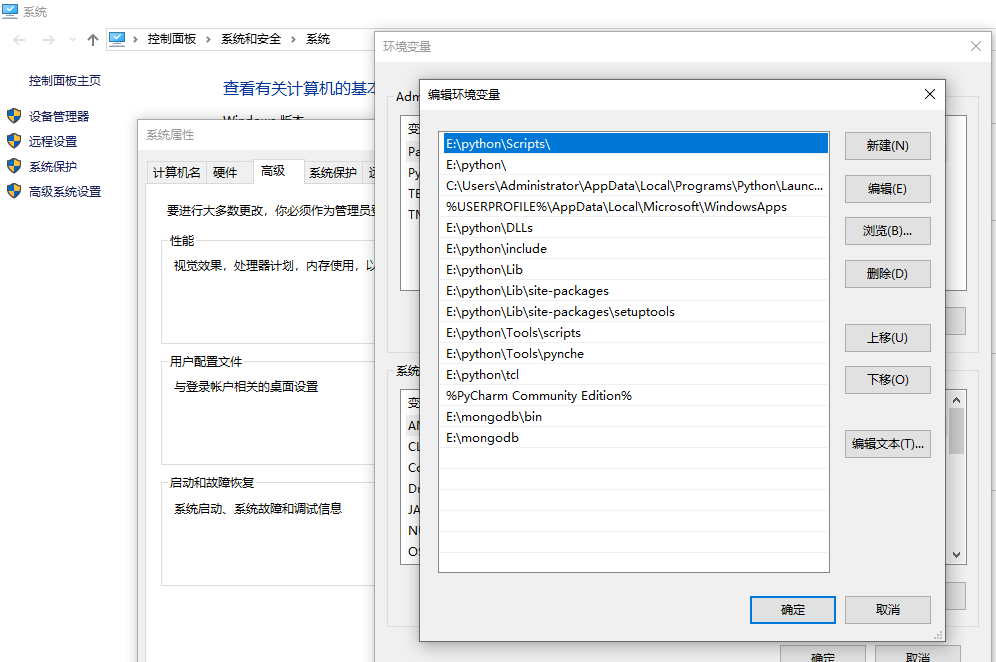
下载的浏览器驱动也要看清楚对应自己浏览器版本的,如果驱动与浏览器版本不对是会报错了。
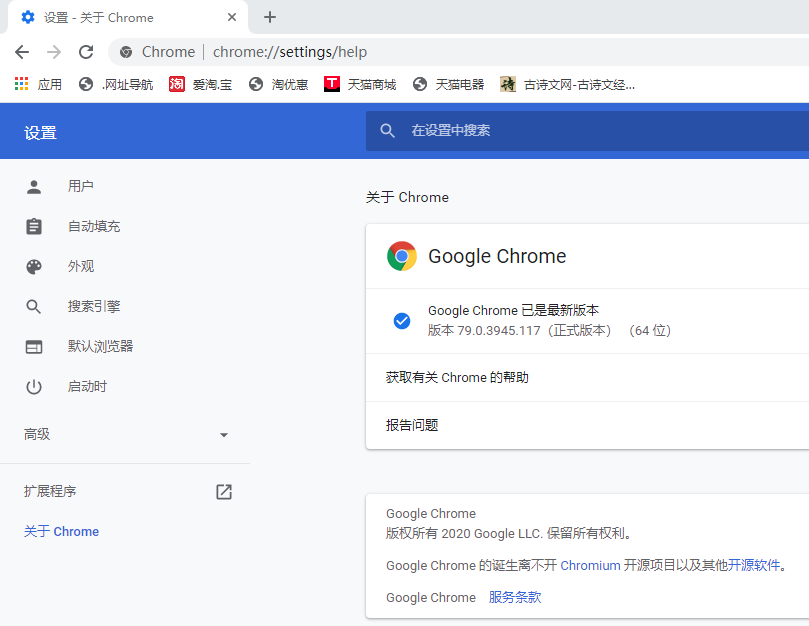
chromedriver与chrome浏览器对照表参考:
https://blog.csdn.net/huilan_same/article/details/51896672
国内不能直接访问Chrome官网,可以在ChromeDriver仓库中下载:http://chromedriver.storage.googleapis.com/index.html

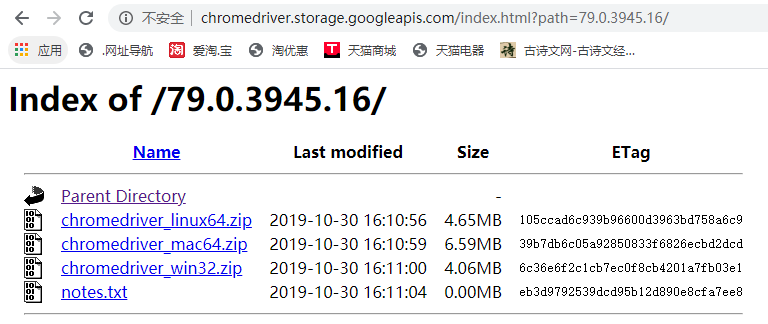
我的浏览器需要下载的是倒数第三个,请读者根据自己的电脑和浏览器的版本实际情况下载;
放到上面的python那个安装文件夹后,我记得也是需要放到chrome浏览器安装目录下的
查找chrome安装路径
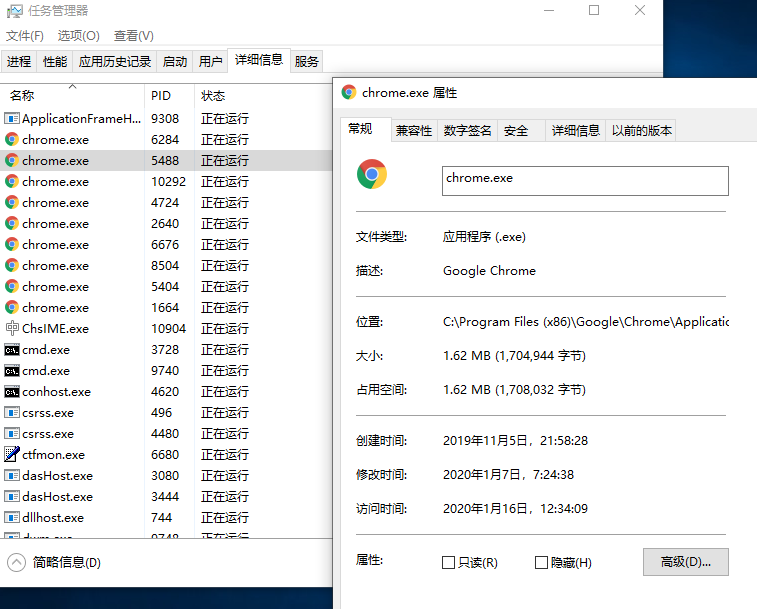
把下载的驱动放到这个路径下
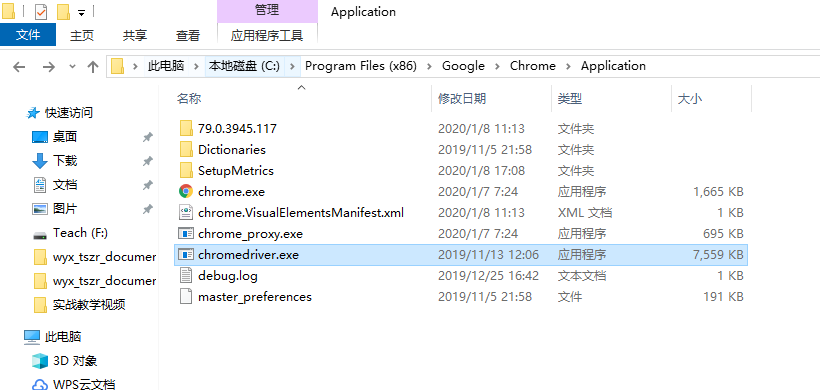
然后也把chrome浏览器的安装路径添加到path路径中。
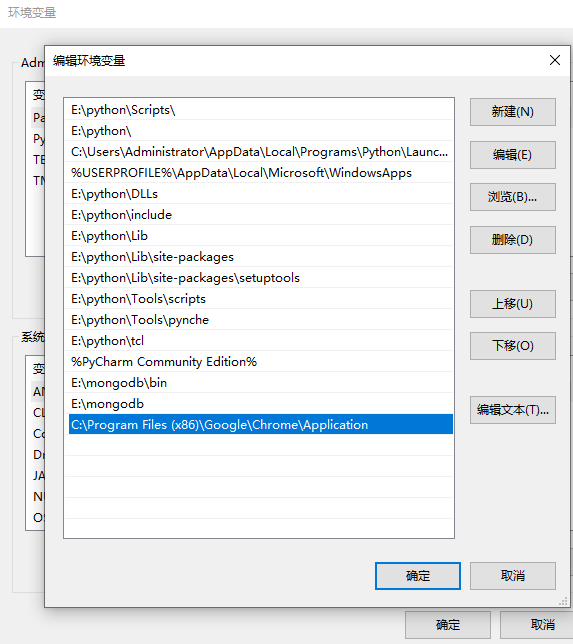
配置好之后,实现爬虫的代码如下:
(正在更新中...)