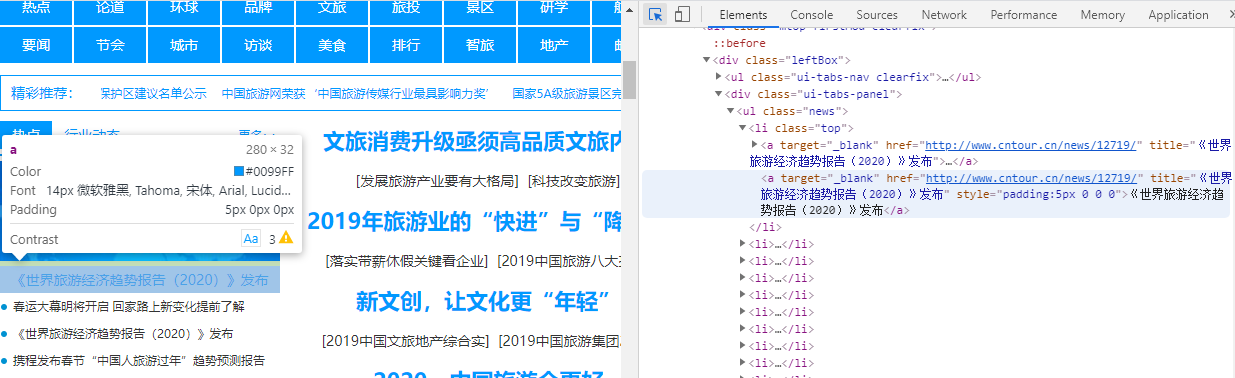
import requests from bs4 import BeautifulSoup url = "http://www.cntour.cn/" strhtml = requests.get(url) soup = BeautifulSoup(strhtml.text,"lxml") #下面的参数由网站开发者模式中Copy->copy selector复制而来 data = soup.select("#main > div > div.mtop.firstMod.clearfix > div.centerBox > ul.newsList > li:nth-child(1) > a") print(data)

import requests from bs4 import BeautifulSoup url = "http://www.cntour.cn/" strhtml = requests.get(url) soup = BeautifulSoup(strhtml.text,"lxml") #下面的参数由网站开发者模式中Copy->copy selector复制而来,获取该网站所有超链接内容,删掉::nth-child(1),如下: data = soup.select("#main > div > div.mtop.firstMod.clearfix > div.centerBox > ul.newsList > li > a") print(data)

#清洗和组织爬取到的数据 import requests from bs4 import BeautifulSoup url = "http://www.cntour.cn/" strhtml = requests.get(url) soup = BeautifulSoup(strhtml.text,"lxml") #下面的参数由网站开发者模式中Copy->copy selector复制而来,获取该网站所有超链接内容,删掉::nth-child(1),如下: data = soup.select("#main > div > div.mtop.firstMod.clearfix > div.centerBox > ul.newsList > li > a") for item in data: result={ "title":item.get_text(), "link":item.get("href") } print(result)

#清洗和组织爬取到的数据,获取每个链接后面的ID import re import requests from bs4 import BeautifulSoup url = "http://www.cntour.cn/" strhtml = requests.get(url) soup = BeautifulSoup(strhtml.text,"lxml") #下面的参数由网站开发者模式中Copy->copy selector复制而来,获取该网站所有超链接内容,删掉::nth-child(1),如下: data = soup.select("#main > div > div.mtop.firstMod.clearfix > div.centerBox > ul.newsList > li > a") for item in data: result={ "title":item.get_text(), "link":item.get("href"), "ID":re.findall("\d+",item.get("href")) } print(result)
