(一定请仔细看)前几天在群里面有朋友推给我一个HS链接,我就打开看了,这个链接有个特别的地方,他需要我收藏起来,才能看到他本身的页面,如果你不收藏的话,呵呵,直接给你传送到aiqiyi,而且电脑上我也看了也不行,模仿手机操作也不行,后来在网上认识了一个做网络安全的大哥他给试了一下,能行,后来我问了一下他的思路,他是这么说的,这个页面跳转的肯定是js控制的,那就跳过js就行了,然后他在linux上使用curl,直接跳过js,然后就拿到了html代码了,这思路,我第一次碰到啊。
废话说了这么多,话不多说,我给大家看一下他的页面啊。
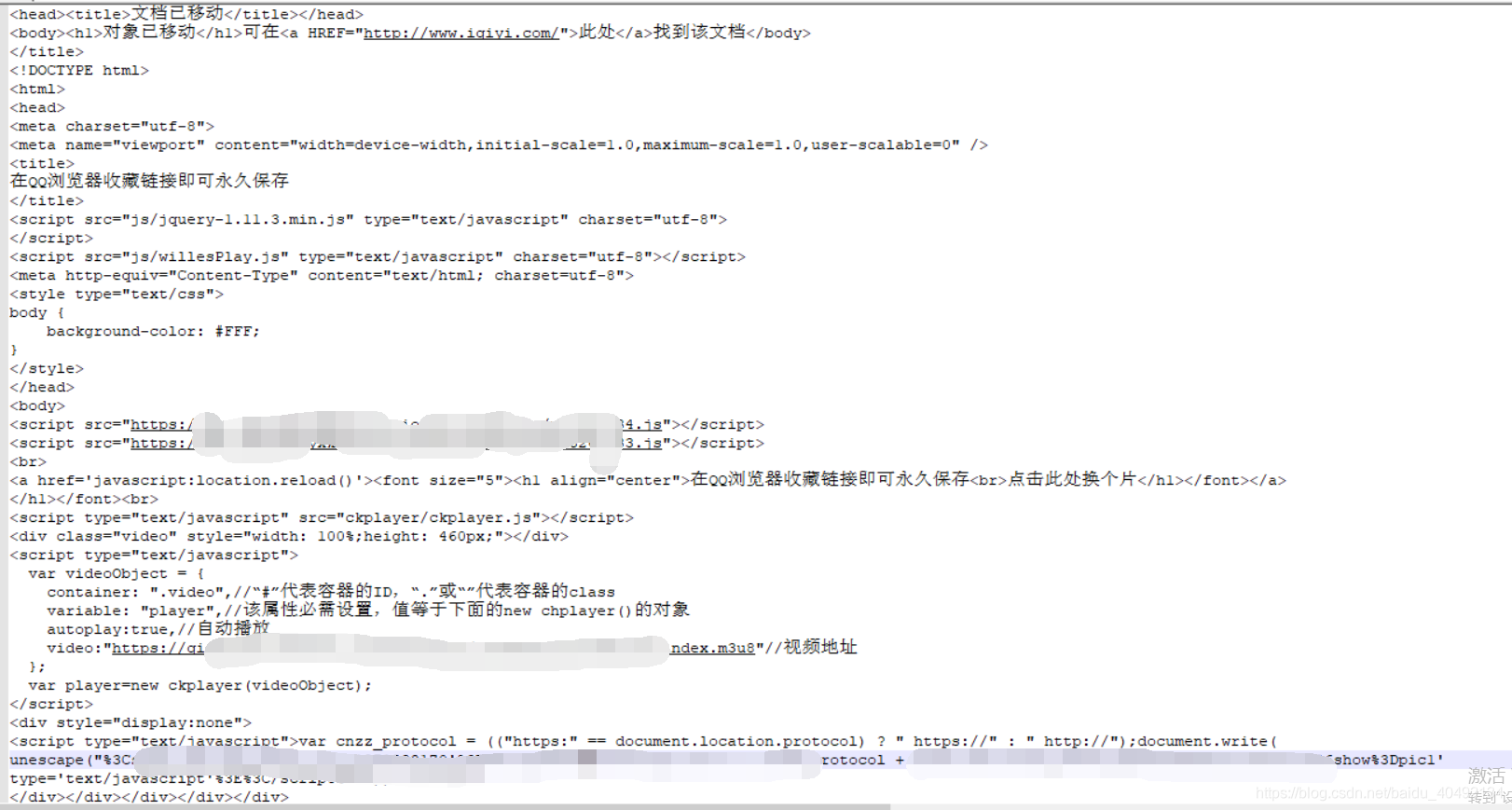
上面就是他的页面代码了啊,感觉其实也没点啥,就是那个收藏起来才能看,操作有点骚。页面的那中链接,我没放出来,希望大家见谅。我第一次碰到这种链接,就发文给大家看一下。
放出我们的demo直接上图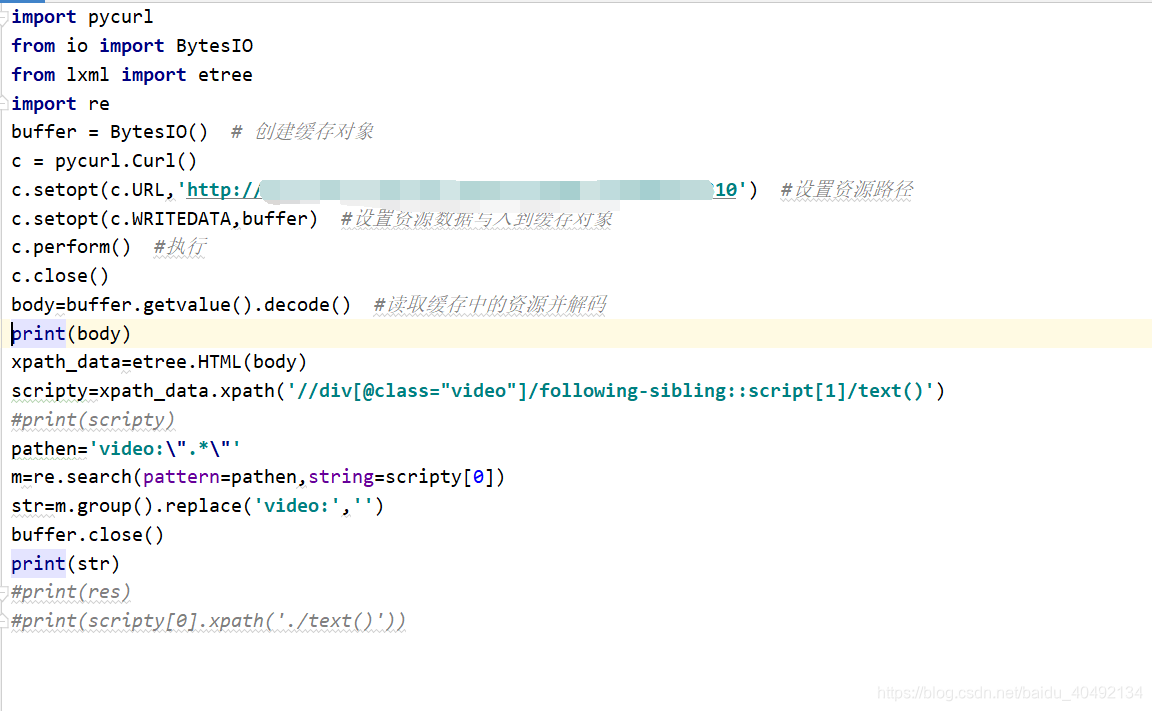
上面就是我搞了一下的东西,纪念一下我发现的这个神奇的链接,特此一写
大哥都看到这了,给点个赞,评论一下呗,谢谢
想要链接的评论给我,我给你发。
