西刺代理,http://www.xicidaili.com/,提供免费代理的IP,是爬虫程序的目标网站.
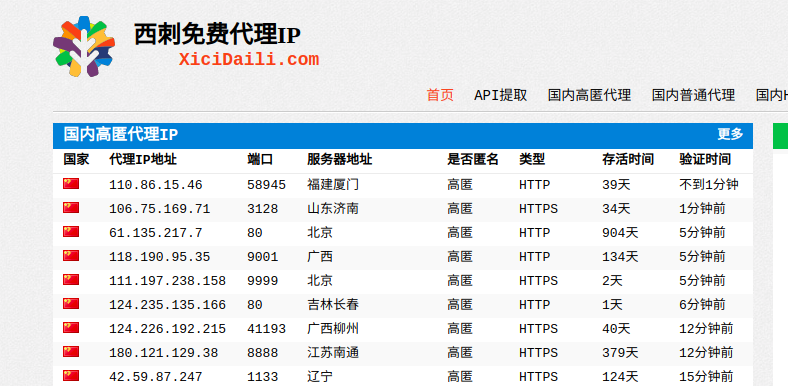
开始写程序
import urllib.request
import re
def open_url(url):
req = urllib.request.Request(url)
req.add_header('User-Agent', 'Mozilla/5.0 (X11; Linux x86_64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/70.0.3538.77 Safari/537.36')
page = urllib.request.urlopen(req)
html = page.read().decode('utf-8')
return html
def get_img(html):
p = r'(?:(?:[0-1]?\d?\d|2[0-4]\d|25[0-5])\.){3}(?:[0,1]?\d?\d|2[0-4]\d|25[0-5])'
iplist = re.findall(p, html)
for each in iplist:
print(each)
if __name__ == '__main__':
url = "http://www.xicidaili.com/"
get_img(open_url(url))
执行程序结果如下
