版权声明:本文为博主原创文章,基于CC4.0协议,首发于https://kikt.top ,同步发于csdn,转载必须注明出处! https://blog.csdn.net/qq_28478281/article/details/87283247
前言
最近打算使用 flutter 做一个省市的级联列表,但是目前没有数据来源,就想着搜搜有没有 json 的数据,结果搜了一下只有各种数据库的
然后搜了下有个网站说有很完整的数据的还是收费的
作为一个穷人程序员,如果是公司用,我付费买一个也无所谓,但是本身是想私人使用,甚至开源出去,付费就没必要了
这时候我想着,既然如此,我就爬一份数据,自己造一个吧
说到爬虫,我们就想起了明年…两开花 python
开发环境
使用的语言是 python3
request_html+基本库
爬取网页
国家统计局-2017 年统计用区划代码和城乡划分代码(截止 2017 年 10 月 31 日)
查看网页
一级页面
使用 chrome dev 工具查看元素
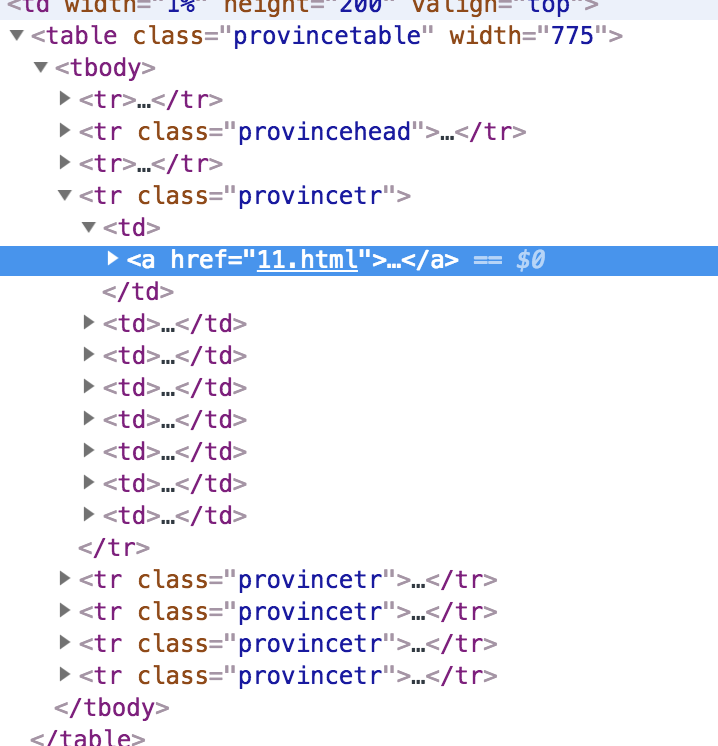
呃. table 体系,最近几年算是比较少见了
分析了一下,整个页面只有备案号和省份名称是 a 标签,这下过滤一下备案号,剩下的不就是我们要的数据了吗
二级页面
点开北京,数据比较少,只有市辖区

内蒙的就比较多一点了

纯数字的是编码,其他的是名称,也是过滤掉 IPC 备案的就好
三级页面
和二级页面基本一致

撸码
city_get.py
import json
from requests_html import HTMLSession
import requests_html
session = HTMLSession()
class Entity:
name: str
link: str
no: str
baseUrl = "http://www.stats.gov.cn/tjsj/tjbz/tjyqhdmhcxhfdm/2017/"
def __str__(self) -> str:
return "name:%s,link=%s" % (self.name, self.link)
def __eq__(self, o: object) -> bool:
return self.link == o.link
def to_json(self) -> str:
pass
class Province(Entity):
def __init__(self) -> None:
super().__init__()
self.cityList = []
def __str__(self) -> str:
return "name:%s,link=%s" % (self.name, self.link)
def fetch_city_list(self):
url = "%s%s" % (Entity.baseUrl, self.link)
r = session.get(url)
r.encoding = "gbk"
h: requests_html.HTML = r.html
li: list[requests_html.Element] = h.find("a")
for a in li:
text = a.text
if text.__contains__("京ICP"):
continue
href_ = a.attrs["href"]
city = City()
city.link = href_
city.province = self
# print(text, href_)
try:
index = self.cityList.index(city)
city = self.cityList[index]
except ValueError:
self.cityList.append(city)
if text.isnumeric():
city.no = text
else:
city.name = text
for city in self.cityList:
city.fetch_county_list()
def to_json(self) -> str:
pass
class City(Entity):
province: Province
def __init__(self) -> None:
super().__init__()
self.countyList = []
def fetch_county_list(self):
print("%s 开始" % self.name)
url = "%s%s" % (Entity.baseUrl, self.link)
r = session.get(url)
r.encoding = "gbk"
h: requests_html.HTML = r.html
li: list[requests_html.Element] = h.find("a")
for a in li:
text = a.text
if text.__contains__("京ICP"):
continue
href_ = a.attrs["href"]
county = County()
county.link = href_
county.province = self
# print(text, href_)
try:
index = self.countyList.index(county)
county = self.countyList[index]
except ValueError:
self.countyList.append(county)
if text.isnumeric():
county.no = text
else:
county.name = text
for county in self.countyList:
# print(county.__str__())
pass
print("%s 结束" % self.name)
pass
class County(Entity):
city: City
pass
provinceList = []
def fetch_province_list():
response = session.get("http://www.stats.gov.cn/tjsj/tjbz/tjyqhdmhcxhfdm/2017/index.html")
response.encoding = "gbk"
html: requests_html.HTML = response.html
# s = response.content.decode("gbk")
l: list = html.find("a")
for a in l:
ae: requests_html.Element = a
href: str = ae.attrs.get("href")
if href.endswith("html"):
province = Province()
province.name = ae.text.lstrip()
province.link = href.lstrip()
provinceList.append(province)
fetch_province_list()
if __name__ == '__main__':
for p in provinceList:
if p.name == "黑龙江省":
p.fetch_city_list()
# session.close()
dump_data.py
import json
from city.city_get import Province, County, City, provinceList
import datetime
# for p in provinceList:
# pr: Province = p
version = 2
di = dict()
di["version"] = version
now = datetime.datetime.now()
date = datetime.datetime.strftime(now, "%Y-%m-%d %H:%M:%S")
di["date"] = date
di["timeStamp"] = now.timestamp()
proList = []
def make_province(p: Province):
p.fetch_city_list()
p_dict = dict()
city_list = []
p_dict["name"] = p.name
for city in p.cityList:
city: City = city
c_dict = dict()
c_dict["name"] = city.name
c_dict["no"] = city.no
city_list.append(c_dict)
make_city(city, c_dict)
p_dict["cityList"] = city_list
proList.append(p_dict)
def make_city(city: City, city_obj: dict):
city.fetch_county_list()
li = []
county_list: list[County] = city.countyList
for county in county_list:
c_obj = dict()
c_obj["name"] = county.name
c_obj["no"] = county.no
li.append(c_obj)
city_obj["countyList"] = li
pass
for province in provinceList:
print("province = %s" % province.name)
make_province(province)
di["provinceList"] = proList
s = json.dumps(di)
f = open("data/city-version-%s.json" % version, 'w')
f.write(s)
分了两个文件,其中一个是获取数据,一个是将数据转为 json 形式保存
如果后续有必要,也可以弄一个数据库,具体是 sqlite 还是 mysql 都可以自己解析 json 插入,对于一个合格的程序员都是小意思
代码
代码可以从github仓库查看
生成数据
生成的数据比较大,大概有 22w 字符 200 多 K
可以从github release下载
或直接从city-version-4.json copy
格式化完的数据有 14000 行左右, 可以查看pretty-json