- 大学期间就接触过python,当时是信心满满的要学习这门语言,但最后沦为了从入门到放弃。现在反思一下,当时只顾学习相关语法而没有去做相适应练习所以最后就不了了之。所以这次重新学习python我想从一个新的角度,从实战到相关知识的学习,再到系统的知识的完善。边学习边记录,希望最后能坚持下来,哈哈。所以,此贴仅做记录,如果有什么不对的地方希望大家指正,也希望我们能一起进步,加油。
- 因为之前有过网站下载图片的经历,每个网站上的图片要一个一个点击下载很是辛苦,所以我决定以爬取网站图片作为切入点开始学习python,在第一个程序以后我会试着不断的完善之前的程序,让他更好的为我们服务。
好了,闲话不多说,开始我的主题,安装python以及相应模块的介绍网上很多,在此就略过啦~
python版本:python3.6
IDE:pycharm2017【必须安利一下,墙裂建议刚入门的小伙伴安装,谁用谁知道,哈哈。附上pycharm破解版百度云链接
链接:https://pan.baidu.com/s/1u1jsQw1oMLT1pdr32D325g 密码:vhiq】
用到的模块:re(正则,用于匹配需要的内容),urllib.request(用于抓取html源代码
爬虫思路:a.从目标网站获取html源代码
b.通过正则表达式筛选获取需要的内容
c.将获取到的内容写入本地
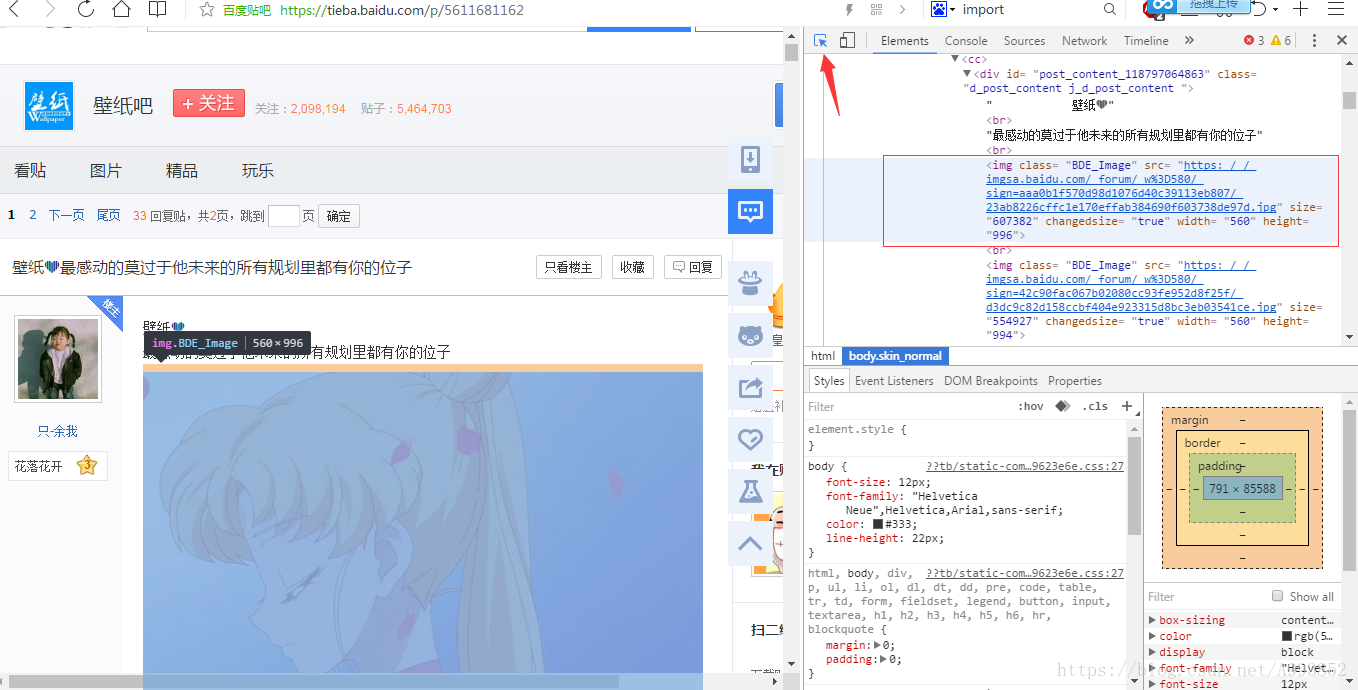
网站就随便选个网站啦,就是这个了:http://tieba.baidu.com/p/5367066525,然后按下F12进入源文件,如下图。接着找到图片源代码分析得到正则表达式(此处省去一万字...有时间补上~)
好了,前期分析工作做得差不多了,我们开始编写一个非常简单的程序来下载我们所需图片(先达到目的,之后再一步步优化)于是我们得到以下代码:
import urllib.request
import re #载入所需模块
html_content = urllib.request.urlopen("https://tieba.baidu.com/p/5611681162").read() #获取html源代码
r = re.compile('<br><img class="BDE_Image" src="(.*?)"') #编译正则表达式
picture_url_list = r.findall(html_content.decode('utf-8')) #匹配所需抓取信息
for i in range(len(picture_url_list)):
picture_name = str(i) + '.jpg'
urllib.request.urlretrieve(picture_url_list[i], picture_name) #下载文件到本地关于各个模块的使用就自己度娘啦,得到结果如下:
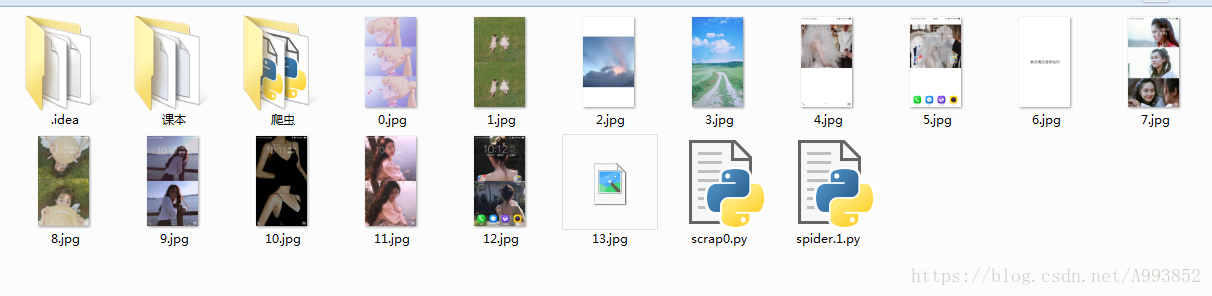
是不是很简单啦,当然啦,这是简单入门,接下来我会根据自己遇到的问题不断的完善,也希望大家能提出宝贵的意见。在这次实现爬虫过程中,我发现有如下问题有待改善,这就是我接下来的目标,希望下个星期能更新上~
没时间写了,明天继续...