在本课程中,你将学习如何使用梯度增强方法来构建和优化模型。这个方法在Kaggle竞赛中占据优势地位,并且在不同的数据集中取到得很好的结果。
1、介绍
在本课程的大部分时间里,你已经使用随机森林方法进行了预测,该方法比单个决策树有更好的性能。
我们把随机森林方法称为“集成方法”。根据定义,集成方法结合了几个模型(例如,在随机森林的案例中有好几个树)的预测。
接下来,我们将学习另一种集成方法,称为梯度增强。
2、梯度增强
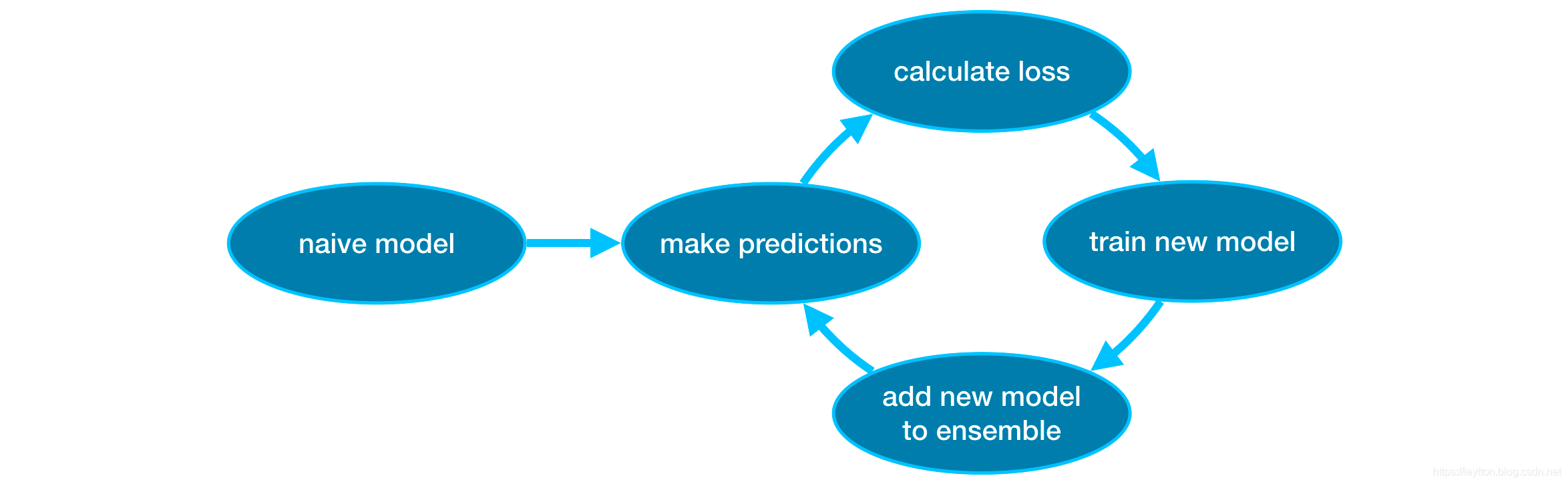
梯度增强是一种通过循环迭代将模型添加到集合中的方法。
它首先用一个模型初始化集合,这个模型的预测可能非常简单。(即使它的预测非常不准确,后续添加的集合将解决这些错误。)
然后,我们开始循环迭代:
- 首先,我们使用当前集成来为数据集中的每个观测结果生成预测。为了进行预测,我们将所有模型的预测添加到集成中。
- 这些预测被用来计算损失函数(例如,平均平方误差)。
- 然后,我们使用损失函数来适应一个新的模型,这个模型将被添加到集成中。具体地说,我们确定模型参数,以便将这个新模型添加到集成中来减少损失。(注:“梯度推进”中的“梯度”指的是我们将对损失函数使用梯度下降法来确定新模型中的参数。)
- 最后,我们将新的模型加入到集成中,并且重复…
3、案例
我们首先加载训练和验证数据X_train、X_valid、y_train和y_valid。
import pandas as pd
from sklearn.model_selection import train_test_split
# 读取数据
data = pd.read_csv('../input/melbourne-housing-snapshot/melb_data.csv')
# 选择预测子数据集
cols_to_use = ['Rooms', 'Distance', 'Landsize', 'BuildingArea', 'YearBuilt']
X = data[cols_to_use]
# Select target
y = data.Price
# 将数据拆分为训练和验证数据
X_train, X_valid, y_train, y_valid = train_test_split(X, y)
在本案例中,你将使用XGBoost库。XGBoost是极端梯度增强(eXtreme Gradient Boosting)的缩写,它是梯度增强的一种实现,更加关注性能和速度特性。(Scikit-learn有另一个版本的梯度增强,但XGBoost有一些技术优势。)
在下一个代码片段中,我们将导入用于scikit-learn API的XGBoost (xgboost.XGBRegressor)。这使我们能够像在scikit-learn中一样构建和拟合模型。正如你在输出中看到的,XGBRegressor类有很多可调参数——你将很快了解它们!
from xgboost import XGBRegressor
my_model = XGBRegressor()
my_model.fit(X_train, y_train)
对模型进行预测和评估:
from sklearn.metrics import mean_absolute_error
predictions = my_model.predict(X_valid)
print("Mean Absolute Error: " + str(mean_absolute_error(predictions, y_valid)))
输出结果:
Mean Absolute Error: 269553.99606958765
4、调参
XGBoost有几个参数可以显著影响准确性和训练速度。下面我们来了解第一个参数:
n_estimators:
n_estimators指定了模型循环的次数,它等于模型集合中的模型个数。
- 过低的值会导致
欠拟合,从而导致对训练和测试数据的预测都不准确。 - 过高的值会导致
过拟合,结果是对训练数据预测非常准确,但对测试数据的预测很不准确(这是问题所在)。
通常取值范围为100-1000,不过这在很大程度上取决于下文讨论的learning_rate参数。
下面是设置模型数量的代码:
my_model = XGBRegressor(n_estimators=500)
my_model.fit(X_train, y_train)
early_stopping_rounds:
early_stopping_rounds提供了一种自动查找n_estimators最佳值的方法。当验证分数停止改进时,过早地停止会导致模型还没达到n_estimators就停止迭代。明智的做法是为n_estimators设置一个较大的值,然后使用early_stopping_rounds来找到停止迭代的最佳时间。
由于随机几率有时候会导致单次验证分数没有提高,您需要指定一个数字,设置验证分数连续恶化多少轮时停止。设置early_stopping_rounds=5是一个合理的选择。此时,训练过程中验证分数连续5轮恶化就会停止。
在使用early_stopping_rounds时,通过设置eval_set参数,来指定用于计算验证分数的数据。
我们可以修改上面的例子,添加early_stopping_rounds和eval_set等参数:
my_model = XGBRegressor(n_estimators=500)
my_model.fit(X_train, y_train,
early_stopping_rounds=5,
eval_set=[(X_valid, y_valid)],
verbose=False)
如果您以后想让模型拟合更精确,那么将n_estimators设置为您认为在早期停止运行时最优的值。
learning_rate
不能直接将每个模型的预测值相加,我们需要设置一个小数字(称为学习率),将各个预测值乘以这个小数字再相加。
学习率越小,这意味着每棵树对于整体影响更小。因此,我们可以在没有过拟合的情况下给n_estimators设置一个更大的值。如果我们使用提前停止,将自动确定合适的树数量。
通常,较小的学习率和较多的决策模型将使XGBoost模型更精确,花费的模型训练时间也更长,因为进行了更多的迭代。默认情况下,XGBoost设置learning_rate=0.1。
如下代码添加了学习率设置:
my_model = XGBRegressor(n_estimators=1000, learning_rate=0.05)
my_model.fit(X_train, y_train,
early_stopping_rounds=5,
eval_set=[(X_valid, y_valid)],
verbose=False)
n_jobs
当需要考虑大型数据集计算时,可以使用并行计算加速模型构建。通常将参数n_jobs设置为机器上的内核数量。对于较小的数据集,没什么用。
结果模型不会更好时,对拟合时间的微优化通常毫无意义。但是,它在大型数据集中非常有用,否则在拟合时需要花费很长时间。
下面是修改过的代码:
my_model = XGBRegressor(n_estimators=1000, learning_rate=0.05, n_jobs=4)
my_model.fit(X_train, y_train,
early_stopping_rounds=5,
eval_set=[(X_valid, y_valid)],
verbose=False)
5、结论
XGBoost是处理标准表格数据(指能存储在Pandas DataFrames里的数据类型,而不是图像、视频等比较奇特的数据类型)的领先软件库。通过仔细调参优化,您可以训练高精确的模型。
6、去吧,皮卡丘
在练习中使用XGBoost训练你自己的模型!
原文 https://www.kaggle.com/alexisbcook/xgboost
