在本课程中,你将学习如何什么是数据泄露以及如何避免数据泄露。如果你不知道如何防止,数据泄漏将频繁出现,它将以微妙和危险的方式破坏你的模型。这是数据科学家最重要的概念之一。
1、介绍
数据泄露是指,在训练数据中包含目标信息,但在预测时没有可用的类似数据。这会使得训练数据(或者验证数据)效果比较好,但实际生产(预测)时效果特别差。
也就是说,泄漏导致模型看起来很精确,但用模型做出来的决策却很不准确。
主要有两种泄露类型:target leakage(目标泄露) 和 train-test contamination(训练测试污染)
1.1 目标泄露
当预测时包含不可用数据时就会发生目标泄露。根据数据可用的时间顺序来考虑目标泄漏是很重要的,而不仅仅是某个特性是否有助于做出良好预测。
举例来说,如果你想预测谁会患上肝炎。原始数据的前几行是这样的:
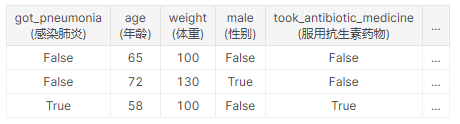
人们在患肺炎后通过服用抗生素来恢复健康。原始数据显示这些列之间有很强的关系,但是人们一般是确定患肺炎后(
got_pneumonia=True),才服用抗生素(took_tic_medicine=True),两者之间有先后顺序。这就是目标泄漏。
该模型将会看到,took_tic_medicine值为False的人都没有患肺炎。由于验证数据与训练数据来源相同,模式将在验证中重复,并且模型将具有良好的验证(或交叉验证)分数。
但是,当这个模型应用于现实世界时,它将非常不准确,因为即使是患肺炎的病人,在我们对其健康状况做出预测时,他们可能还没有服用抗生素。
为了防止这种类型的数据泄露,应排除目标值发生后才更新(或创建)的变量。

1.2 训练测试污染
当不认真区分训练数据和验证数据时,就会发生另一种类型的泄漏。
回想一下,验证意味着度量模型如何处理以前没有考虑过的数据。如果验证数据影响预处理行为,则会以微妙的方式破坏模型。这被称为训练测试污染。
举例来说,如果你在调用calling train_test_split()函数前对数据进行预处理(比如为缺失的值拟合一个估算值),结果怎么样?你的模型将会获得一个较好的验证分数,但用于部署决策时效果很差。
毕竟,你将验证或测试数据数据合并了来进行预测,即使不能泛化到新数据,也能很好地处理特定数据。但进行更复杂的特性工程时,这个问题会变得更微妙(也更危险)。
如果你的验证是基于简单的训练-测试分割,则需要在拟合时排除验证数据(包括预处理步骤的拟合)。使用scikit-learn的pipeline这会比较容易。使用交叉验证时,在pipeline中进行预处理比较好。
2、案例
在本案例中,你将会学习一种检测和消除目标泄露的方法。
我们将使用一个关于信用卡申请的数据集,并跳过初始化代码。最终结果是每条信用卡申请信息存在X(DataFrame类型)变量里,我们将会使用它来预测哪一条申请将会被接受,结果存储在y变量里。
import pandas as pd
# 读取数据
data = pd.read_csv('../input/aer-credit-card-data/AER_credit_card_data.csv',
true_values = ['yes'], false_values = ['no'])
# 选择目标
y = data.card
# 选择预测
X = data.drop(['card'], axis=1)
print("Number of rows in the dataset:", X.shape[0])
X.head()
Number of rows in the dataset: 1319
由于数据量比较小,我们使用交叉验证来确保模型质量的准确量。
from sklearn.pipeline import make_pipeline
from sklearn.ensemble import RandomForestClassifier
from sklearn.model_selection import cross_val_score
# 因为没有预处理,所以我们不需要pipeline
my_pipeline = make_pipeline(RandomForestClassifier(n_estimators=100))
cv_scores = cross_val_score(my_pipeline, X, y,
cv=5,
scoring='accuracy')
print("Cross-validation accuracy: %f" % cv_scores.mean())
Cross-validation accuracy: 0.979525
根据经验,其实很少有模型在98%的时间内都是准确的。这种情况会发生但并不常见,我们需要仔细地检查数据是否存在目标泄漏。
下面是数据的摘要,你也可以在data变量中找到:
card: 信用卡申请被接受:1,不被接受:0reports: 主要负面报道次数age: 年龄(小数代表现在一年中过去的时间)income: 年收入(万)share: 每月信用卡支出与年收入之比expenditure: 平均每月信用卡支出owner: 有房子:1,租房子:0selfempl: 自己雇佣自己:1,不自雇:0dependents: 家庭人数months: 在现址住了几个月majorcards: 持有的主要信用卡数量active: 活跃的信用帐户数量
有几个变量看起来有些疑惑。例如,支出是指此卡上的支出还是申请之前使用的卡片上的支出?
在这一点上,基本的数据比较是很有用的:
expenditures_cardholders = X.expenditure[y]
expenditures_noncardholders = X.expenditure[~y]
print('Fraction of those who did not receive a card and had no expenditures: %.2f' \
%((expenditures_noncardholders == 0).mean()))
print('Fraction of those who received a card and had no expenditures: %.2f' \
%(( expenditures_cardholders == 0).mean()))
Fraction of those who did not receive a card and had no expenditures: 1.00
Fraction of those who received a card and had no expenditures: 0.02
如上所示,没有收到信用卡的人没有支出,而收到信用卡的人中只有2%没有支出。我们的模型似乎有很高的准确性,这并不奇怪。但这似乎也是目标泄露的一个例子,其中支出可能意味着他们将要申请的卡上的支出(所以对于预测没有意义可以排除)。
由于份额部分由支出决定,它也应该被排除在外。active和majorcards变量不太清楚,但从描述来看,它们听起来关联很大。在大多数情况下,如果无法找到创建数据的人以了解更多信息,那么安全总比遗憾好。
我们将运行一个没有数据泄露的模型,如下:
# 从数据集中删除潜在泄漏数据
potential_leaks = ['expenditure', 'share', 'active', 'majorcards']
X2 = X.drop(potential_leaks, axis=1)
# Evaluate the model with leaky predictors removed
cv_scores = cross_val_score(my_pipeline, X2, y,
cv=5,
scoring='accuracy')
print("Cross-val accuracy: %f" % cv_scores.mean())
Cross-val accuracy: 0.828651
这个精度要低一些,这可能会令人失望。但是,在新申请案例中,我们可以期望它在80%的情况下是正确的,而数据泄露的模型可能比这更糟(尽管它在交叉验证中得分更高)。
3、总结
在许多数据科学应用中,数据泄漏可能导致数百万美元的损失。小心分割训练和验证数据可以防止训练测试污染,可以使用pipeline实现。同样,结合谨慎、常识和数据探索可以帮助识别目标泄漏。
4、去吧,皮卡丘
这似乎仍然很抽象。尝试通过本练习中的示例,来提高识别目标泄漏和训练测试污染的技能!
原文 https://www.kaggle.com/alexisbcook/data-leakage
