先修知识:

1. XGBoost简介
XGBoost的全称是eXtreme Gradient Boosting,它是经过优化的分布式梯度提升库,旨在高效、灵活且可移植。XGBoost是大规模并行boosting tree的工具,它是目前最快最好的开源 boosting tree工具包,比常见的工具包快10倍以上。在工业界大规模数据方面,XGBoost的分布式版本有广泛的可移植性,支持在Kubernetes、Hadoop、SGE、MPI、 Dask等各个分布式环境上运行,使得它可以很好地解决工业界大规模数据的问题。本文将从XGBoost的数学原理和工程实现上进行介绍,然后介绍XGBoost的优缺点。
2. XGBoost的原理推导
2.1 从目标函数开始,生成一棵树
2.1.1 XGBoost的目标函数
XGBoost和GBDT两者都是boosting方法,除了工程实现、解决问题上的一些差异外,最大的不同就是目标函数的定义。因此,本文我们从目标函数开始探究XGBoost的基本原理。
损失函数可由预测值 y ^ i \hat y_i y^i 与真实值 y i y_i yi 进行表示:
L = ∑ i = 1 n l ( y ^ i , y i ) L = \sum _{i=1}^n l(\hat y_i, y_i) L=i=1∑nl(y^i,yi)
其中, n n n 为样本数量。
我们知道模型的预测精度由模型的偏差和方差共同决定,损失函数代表了模型的偏差,想要方差小则需要在目标函数中添加正则项,用于防止过拟合。所以目标函数由模型的损失函数 L 与抑制模型复杂度的正则项 Ω \Omega Ω 组成,目标函数的定义如下:
O b j = ∑ i = 1 n l ( y ^ i ( t ) , y i ) + ∑ i = 1 t Ω ( f i ) ( 1 ) Obj =\sum _{i=1}^n l(\hat y_i^{(t)}, y_i) + \sum _{i=1}^t \Omega(f_i) ~~~~~~~~~~(1) Obj=i=1∑nl(y^i(t),yi)+i=1∑tΩ(fi) (1)
其中,n为样本数量, ∑ i = 1 t Ω ( f i ) \sum _{i=1}^t \Omega(f_i) ∑i=1tΩ(fi)是将全部 t 棵树的复杂度进行求和,添加到目标函数中作为正则化项,用于防止模型过度拟合。
由于XGBoost是boosting族中的算法,所以遵从前向分步加法,以第 t 步的模型为例,模型对第 i 个样本 x i x_i xi的预测值为:
y ^ i ( t ) = y ^ i ( t − 1 ) + f t ( x i ) \hat y_i^{(t)} = \hat y_i^{(t-1)} +f_t(x_i) y^i(t)=y^i(t−1)+ft(xi)
其中, y ^ i ( t − 1 ) \hat y_i^{(t-1)} y^i(t−1)是第 t − 1 t-1 t−1步模型给出的预测值, f t ( x i ) f_t(x_i) ft(xi)是这次需要加入模型的新的预测值。
将此式带入(1)式,得到:
O b j = ∑ i = 1 n l ( y ^ i ( t ) , y i ) + ∑ i = 1 t Ω ( f i ) = ∑ i = 1 n l ( y ^ i ( t − 1 ) + f t ( x i ) , y i ) + ∑ i = 1 t Ω ( f i ) = ∑ i = 1 n l ( y ^ i ( t − 1 ) + f t ( x i ) , y i ) + Ω ( f t ) + c o n s t Obj =\sum _{i=1}^n l(\hat y_i^{(t)}, y_i) + \sum _{i=1}^t \Omega(f_i) \\ =\sum _{i=1}^n l(\hat y_i^{(t-1)}+f_t(x_i), y_i) + \sum _{i=1}^t \Omega(f_i) \\ = \sum _{i=1}^n l(\hat y_i^{(t-1)}+f_t(x_i), y_i) + \Omega(f_t) +const Obj=i=1∑nl(y^i(t),yi)+i=1∑tΩ(fi)=i=1∑nl(y^i(t−1)+ft(xi),yi)+i=1∑tΩ(fi)=i=1∑nl(y^i(t−1)+ft(xi),yi)+Ω(ft)+const
注意上式中,只有一个变量,那就是第 t 棵树 f t f_t ft ,其余都是已知量或可通过已知量可以计算出来的。细心的同学可能会问,上式中的第二行到第三行是如何得到的呢?这里我们将正则化项进行拆分,由于前 t-1 棵树的结构已经确定,因此前t-1 棵树的复杂度之和可以用一个常量表示.
2.1.2 泰勒展开
根据泰勒公式,将函数 f ( x + Δ x ) f(x+\Delta x) f(x+Δx)在 Δ x \Delta x Δx处做二阶泰勒展开,得到:
f ( x + Δ x ) = f ( x ) + f ′ ( x ) Δ x + 1 2 f ′ ′ ( x ) Δ ( x ) 2 + o ( x 2 ) f(x+\Delta x) = f(x) +f'(x) \Delta x+\frac{1}{2}f''(x)\Delta (x)^2 +o(x^2) f(x+Δx)=f(x)+f′(x)Δx+21f′′(x)Δ(x)2+o(x2)
回到XGBoost的目标函数上来,迭代到第t棵树时,第i个样本的损失函数为 l ( y i , y ^ i ( t − 1 ) + f t ( x i ) ) l(y_i, \hat y_i^{(t-1)}+f_t(x_i)) l(yi,y^i(t−1)+ft(xi)), 将其做二阶泰勒展开,得到:
l ( y i , y ^ i ( t − 1 ) + f t ( x i ) ) = l ( y i , y ^ i ( t − 1 ) ) + g i f t ( x i ) + 1 2 h i f t ( x i ) 2 l(y_i, \hat y_i^{(t-1)}+f_t(x_i)) = l(y_i, \hat y_i^{(t-1)})+g_if_t(x_i)+\frac{1}{2} h_if_t(x_i)^2 l(yi,y^i(t−1)+ft(xi))=l(yi,y^i(t−1))+gift(xi)+21hift(xi)2
其中, g i g_i gi是损失函数 l ( y i , y ^ i ( t − 1 ) ) l(y_i, \hat y_i^{(t-1)}) l(yi,y^i(t−1))对 y ^ i ( t − 1 ) \hat y_i^{(t-1)} y^i(t−1)求一阶导, h i h_i hi是损失函数 l ( y i , y ^ i ( t − 1 ) ) l(y_i, \hat y_i^{(t-1)}) l(yi,y^i(t−1))对 y ^ i ( t − 1 ) \hat y_i^{(t-1)} y^i(t−1)求二阶导。
以平方损失函数为例:
l ( y i , y ^ i ( t − 1 ) ) = ( y i − y ^ i ( t − 1 ) ) 2 l(y_i, \hat y_i^{(t-1)}) = (y_i-\hat y_i^{(t-1)})^2 l(yi,y^i(t−1))=(yi−y^i(t−1))2
则:
g i = − 2 ( y i − y ^ i ( t − 1 ) ) g_i = -2(y_i-\hat y_i^{(t-1)}) gi=−2(yi−y^i(t−1))
h i = 2 h_i = 2 hi=2
将上述的二阶展开式,带入到XGBoost的目标函数中,可以得到第t步需要优化的目标函数的近似值:
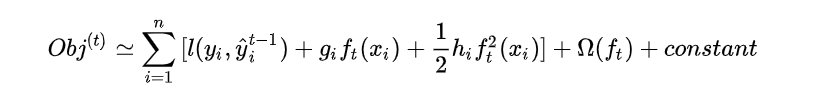 由于在第 t 步时 y ^ i t − 1 \hat y_i^{t-1} y^it−1 其实是一个已知的值,所以 l ( y i , y ^ i ( t − 1 ) ) l(y_i, \hat y_i^{(t-1)}) l(yi,y^i(t−1)) 是一个常数,其对函数的优化不会产生影响。因此,去掉全部的常数项,得到目标函数为:
由于在第 t 步时 y ^ i t − 1 \hat y_i^{t-1} y^it−1 其实是一个已知的值,所以 l ( y i , y ^ i ( t − 1 ) ) l(y_i, \hat y_i^{(t-1)}) l(yi,y^i(t−1)) 是一个常数,其对函数的优化不会产生影响。因此,去掉全部的常数项,得到目标函数为:

在第 t 步,为了找到最好的那个树 f t f_t ft, 我们只需要求出每一步损失函数的一阶导( g i g_i gi)和二阶导( h i h_i hi)的值(由于前一步的 y ^ i ( t − 1 ) ) \hat y_i^{(t-1)}) y^i(t−1)) 是已知的,所以这两个值就是常数)。为了找到那个最好的 f t f_t ft,我们只需要最小化目标函数 O b j ( t ) Obj^{(t)} Obj(t),就可以得到每一步的 f t f_t ft ,最后根据加法模型得到一个整体模型。
2.1.3 树的复杂度定义
【定义1】
一棵决策树有J个叶子节点,那么:
- 叶子节点的权重向量为 w ∈ R J w \in R^J w∈RJ
- 样本到叶子节点的映射关系为 q : R d → { 1 , 2 , . . . , J } q: R^d \rightarrow \{1,2,...,J\} q:Rd→{ 1,2,...,J}, 就是将一个样本输入 x i ∈ R d x_i \in R^d xi∈Rd映射到一个叶子节点。
【定义2】
一颗决策树的复杂度为:
Ω ( f t ) = γ J + 1 2 λ ∑ j = 1 J w j 2 \Omega (f_t) = \gamma J + \frac{1}{2} \lambda \sum_{j=1}^J w_j^2 Ω(ft)=γJ+21λj=1∑Jwj2
其中,J为树的叶子节点个数, w j w_j wj为第j个节点的权重。叶子节点越少模型越简单,此外叶子节点也不应该含有过高的权重 w w w.扫描二维码关注公众号,回复: 12753636 查看本文章
2.1.4 树结构打分
经过一系列推导(推导过程见这里https://zhuanlan.zhihu.com/p/83901304),目标函数可化简为:
O b j = − 1 2 ∑ j = 1 J G j 2 H j + λ + γ J Obj = -\frac{1}{2} \sum _{j=1}^J \frac{G_j^2}{H_j+\lambda}+\gamma J Obj=−21j=1∑JHj+λGj2+γJ
其中,J为这棵树的叶节点个数, G j G_j Gj为节点j所含所有样本的一阶导数 g i g_i gi之和; H j H_j Hj为节点j所含所有样本的二阶导数 h i h_i hi之和。
2.2 如何生成第k棵树
2.2.1 最优切分点划分算法
(1)贪心算法
一棵树的生成是由一个节点一分为二,然后不断分裂最终形成为整棵树。对于一个叶子节点如何进行分裂,XGBoost作者在其原始论文中给出了一种分裂节点的方法:枚举所有不同树结构的贪心法。
XGBoost使用了和CART回归树一样的想法,利用贪婪算法,遍历所有特征的所有特征划分点,不同的是使用的目标函数不一样。具体做法就是求分裂后的目标函数值比分裂前的目标函数的增益,同时为了限制树生长过深,还加了个阈值,只有当增益大于该阈值才进行分裂。
【算法1】
从树的深度为0开始:
(1)对每个叶节点枚举所有的可用特征;
(2) 针对每个特征,把属于该节点的样本根据该特征的值进行升序排列,通过线性扫描的方式来决定该特征的最佳分裂点,并记录该特征的分裂收益;
(3) 选择收益最大的特征作为分裂特征,用该特征的最佳分裂点作为分裂位置,在该节点上分裂出左右两个新的叶节点,并为每个新节点关联对应的样本集;
回到第1步,递归执行直到满足特定条件为止;
【计算每个特征的分裂增益】
某一节点分裂前(只有一个节点)的目标函数可以写为:
分裂后(有两个节点)的目标函数为:
"增益"就是两者之差。
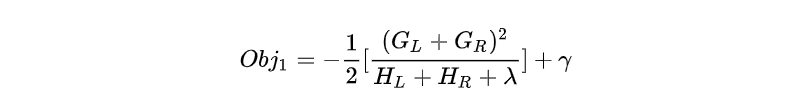
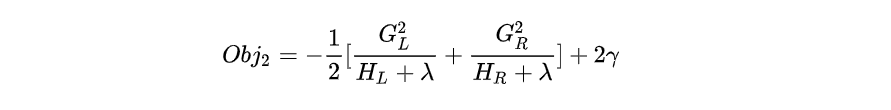
CART回归树中寻找最佳分割点的衡量标准是最小化均方差,xgboost寻找分割点的标准是最大化目标函数增益
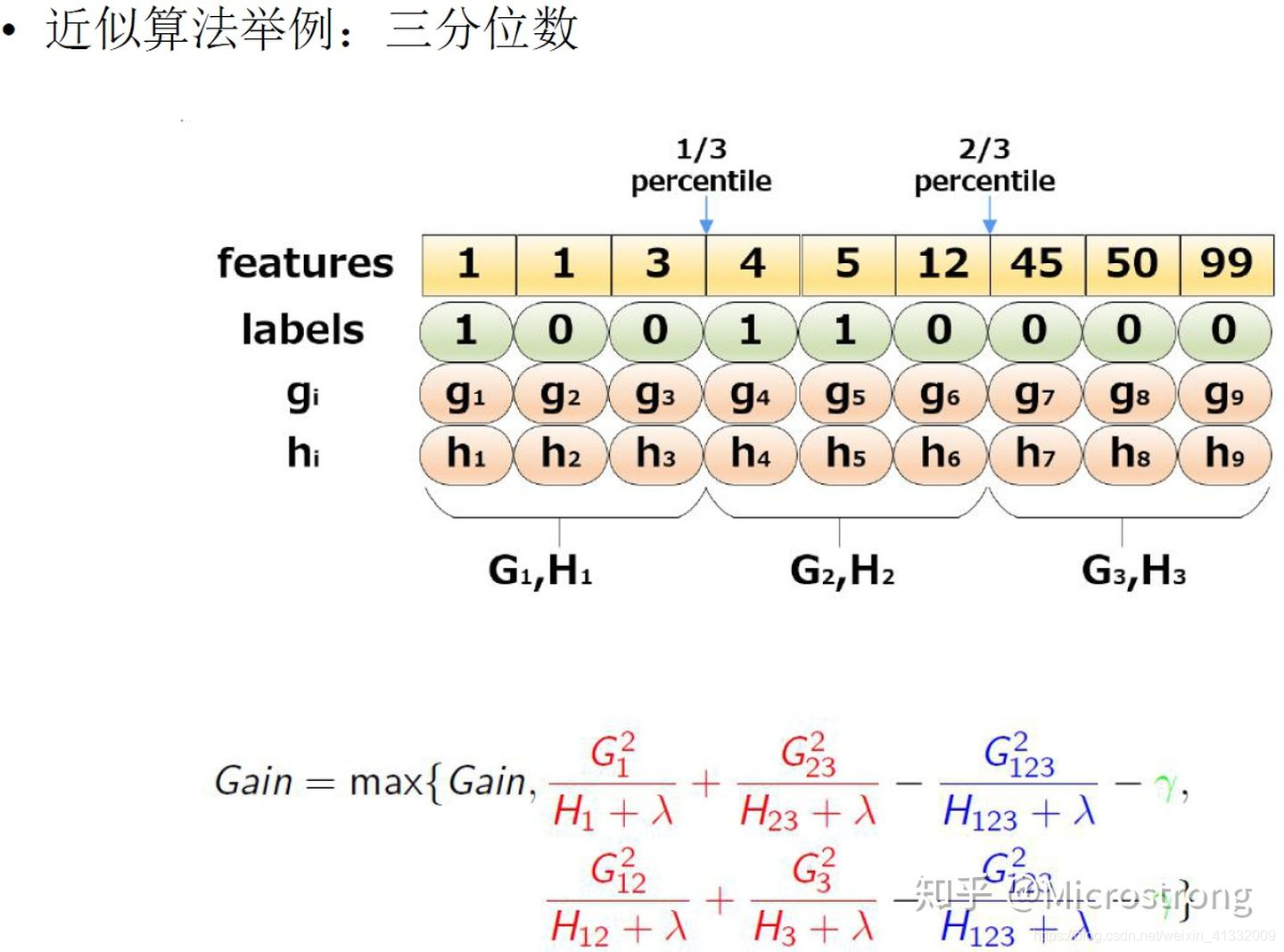
(2)近似算法
贪心算法可以得到最优解,但当数据量太大时则无法读入内存进行计算,近似算法则大大降低了计算量,给出了近似最优解。
对于每个特征,只考察分位点可以减少计算复杂度。
近似算法简单来说,就是对每个特征 k k k 都确定 l l l 个候选切分点 S k = { S k 1 , S k 2 , . . . S k l } S_k = \{S_{k1}, S_{k2},...S_{kl}\} Sk={
Sk1,Sk2,...Skl} ,然后根据这些候选切分点把相应的样本放入对应的桶中,对每个桶的 G , H G,H G,H 进行累加。最后在候选切分点集合上贪心查找。例如:
3. XGBoost的优缺点
3.1 优点
- 精度更高:GBDT中使用损失函数对f(x)的一阶导数计算出伪残差用于学习生成 f m ( x ) f_m(x) fm(x),xgboost不仅使用到了一阶导数,还使用二阶导数。XGBoost 引入二阶导一方面是为了增加精度,另一方面也是为了能够自定义损失函数,二阶泰勒展开可以近似大量损失函数。顺便提一下,xgboost工具支持自定义代价函数,只要函数可一阶和二阶求导。
- 灵活性更强:GBDT 以 CART 作为基分类器,XGBoost 不仅支持 CART 还支持线性分类器,使用线性分类器的 XGBoost 相当于带 L1 和 L2 正则化项的 logistic 回归(分类问题)或者线性回归(回归问题)。此外,XGBoost 工具支持自定义损失函数,只需函数支持一阶和二阶求导;
- 正则化:XGBoost 在目标函数中加入了正则项,用于控制模型的复杂度。正则项里包含了树的叶子节点个数、叶子节点权重的 L2 范式。正则项降低了模型的方差,使学习出来的模型更加简单,有助于防止过拟合,这也是XGBoost优于传统GBDT的一个特性。
- Shrinkage(缩减):相当于学习速率。XGBoost 在进行完一次迭代后,会将新加进来的树的叶子节点权重乘上该系数,主要是为了削弱每棵树的影响,让后面有更大的学习空间。传统GBDT的实现也有学习速率;
- 列抽样:XGBoost 借鉴了随机森林的做法,支持列抽样,不仅能降低过拟合,还能减少计算。这也是XGBoost异于传统GBDT的一个特性;
- XGBoost工具支持并行:boosting不是一种串行的结构吗?怎么并行的?注意XGBoost的并行不是树粒度的并行,XGBoost也是一次迭代完才能进行下一次迭代的(第t次迭代的代价函数里包含了前面t-1次迭代的预测值)。XGBoost的并行是在特征粒度上的。我们知道,决策树的学习最耗时的一个步骤就是对特征的值进行排序(因为要确定最佳分割点)。而XGBoost在进行节点的分裂时,需要计算每个特征的增益,最终选增益最大的那个特征去做分裂,那么各个特征的增益计算就可以开多线程进行。
3.2 缺点
- 空间复杂度过高,不仅需要存储特征值,还需要存储特征对应样本的梯度统计值的索引,相当于消耗了两倍的内存。
4. Sklearn中参数
from xgboost.sklearn import XGBClassifier
model=XGBClassifier(base_score=0.5, booster='gbtree', colsample_bylevel=1,
colsample_bytree=1, gamma=0, learning_rate=0.1, max_delta_step=0,
max_depth=3, min_child_weight=1, missing=None, n_estimators=100,
n_jobs=1, nthread=None, objective='binary:logistic', random_state=0,
reg_alpha=0, reg_lambda=1, scale_pos_weight=1, seed=None,
silent=True, subsample=1)

-
n_estimators: 弱分类器(CART)的数量
-
learning_rate:
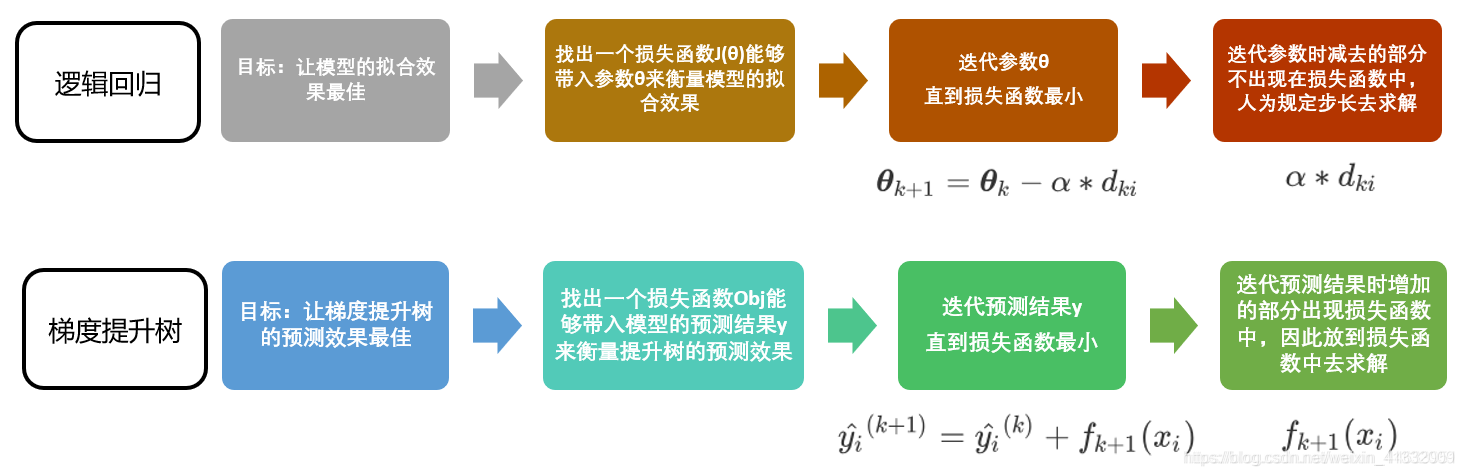
在逻辑回归中,我们自定义步长 α \alpha α 来干涉我们的迭代速率,在 xgboost 中看起来却没有这样的设置,但其实不然。在XGB中,我们完整的迭代决策树的公式应该写作:
y ^ i k + 1 = y ^ i k + η f k + 1 ( x i ) \hat y_i^{k+1} = \hat y_i^k + \eta f_{k+1}(x_i) y^ik+1=y^ik+ηfk+1(xi)
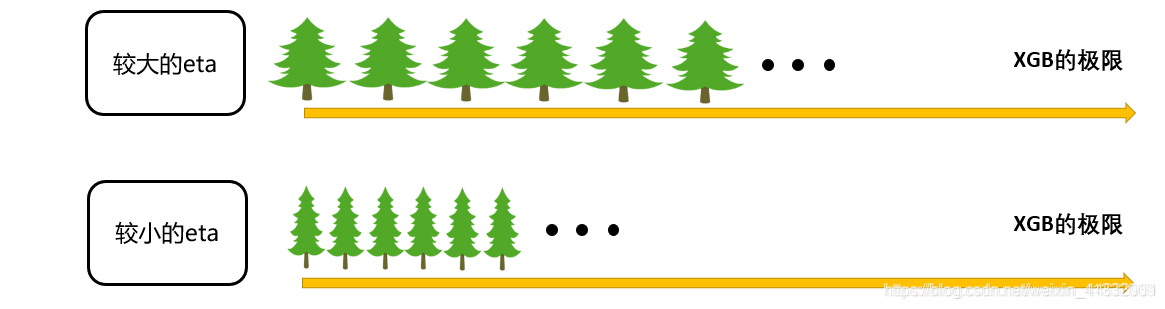
其中 η \eta η 是迭代决策树时的步长(shrinkage),又叫做学习率(learning rate)。和逻辑回归中的 α \alpha α 类似, η \eta η 越大,迭代的速度越快,算法的极限很快被达到,有可能无法收敛到真正的最佳。 η \eta η 越小,越有可能找到更精确的最佳值,更多的空间被留给了后面建立的树,但迭代速度会比较缓慢。
-
subsample:
-
随机选取一定比例的样本来训练树。设置为0.5,则意味着xgboost将从整个样本集合中随机的抽取出50%子样本建立树模型,这能够防止过拟合。
-
取值范围为:(0,1]。减小这个参数的值,算法会更加保守,避免过拟合。但是,如果这个值设置得过小,它可能会导致欠拟合。 典型值:0.5-1。
-
max_depth:[default=3]
每个基本学习器树的最大深度,用于防止过拟合问题。典型值:3~10 -
objective:指的是需要被最小化的损失函数 l ( y i , y ^ i ( t ) ) l(y_i, \hat y_i^{(t)}) l(yi,y^i(t))。
常用的选择有: -
reg:linear 线性回归的损失函数,均方误差,回归时使用
-
binary:logistic 逻辑回归的损失函数,对数损失log_loss,二分类时使用
-
binary:hinge 使用支持向量机的损失函数,Hinge Loss,二分类时使用
-
multi:softmax 使用softmax损失函数,多分类时使用
-
booster: [default=gbtree]
-
gbtree: tree-based models,树模型做为基分类器
-
gblinear: linear models,线性模型做为基分类器
但是tree booster的效果比 linear booster效果好太多,因此linear booster很少用到。 -
gamma:[default=0]
损失阈值,在树的一个叶节点上进一步分裂所需的最小损失减少量,gamma值越大,算法越保守。 -
min_child_weight:[default=1]
拆分节点权重和阈值 -
如果节点的样本权重和小于该阈值,就不再进行拆分。在线性回归模型中,这个是指建立每个模型所需要的最小样本数。
-
值越大,算法越保守。取值范围为:[0,∞]
-
用于防止过拟合问题:较大的值能防止过拟合,过大的值会导致欠拟合问题
-
colsample_bytree:[default=1]
指的是每棵树随机选取的特征的比例,取值范围(0,1]。 -
reg_alpha:[default=0]
权重的L1正则化项。 -
reg_lambda:[default=1]
权重的L2正则化项。这个参数是用来控制xgboost的正则化部分的。虽然大部分数据科学家很少用到这个参数,但是这个参数在减少过拟合上还是可以挖掘出更多用处的。
这样,树的复杂度表示为:
Ω ( f ) = r J + α ∑ j = 1 J ∣ w j ∣ + 1 2 λ ∑ j = 1 J w j 2 \Omega(f) = rJ +\alpha \sum_{j=1}^J |w_j| +\frac{1}{2}\lambda \sum_{j=1}^J w_j^2 Ω(f)=rJ+αj=1∑J∣wj∣+21λj=1∑Jwj2 -
base_score: [default=0.5]
所有实例的初始预测得分,整体偏倚。
3.知乎上关于xgboost/gbdt讨论的经典问答
【问】xgboost/gbdt在调参时为什么树的深度很少就能达到很高的精度?
用xgboost/gbdt在在调参的时候把树的最大深度调成6就有很高的精度了。但是用DecisionTree/RandomForest的时候需要把树的深度调到15或更高。用RandomForest所需要的树的深度和DecisionTree一样我能理解,因为它是用bagging的方法把DecisionTree组合在一起,相当于做了多次DecisionTree一样。但是xgboost/gbdt仅仅用梯度上升法就能用6个节点的深度达到很高的预测精度,使我惊讶到怀疑它是黑科技了。请问下xgboost/gbdt是怎么做到的?它的节点和一般的DecisionTree不同吗?
【答】
这是一个非常好的问题,题主对各算法的学习非常细致透彻,问的问题也关系到这两个算法的本质。这个问题其实并不是一个很简单的问题,我尝试用我浅薄的机器学习知识对这个问题进行回答。
一句话的解释,来自周志华老师的机器学习教科书( 机器学习-周志华):Boosting主要关注降低偏差,因此Boosting能基于泛化性能相当弱的学习器构建出很强的集成;Bagging主要关注降低方差,因此它在不剪枝的决策树、神经网络等学习器上效用更为明显。
随机森林(random forest)和GBDT都是属于集成学习(ensemble learning)的范畴。集成学习下有两个重要的策略Bagging和Boosting。
Bagging算法是这样做的:每个分类器都随机从原样本中做有放回的采样,然后分别在这些采样后的样本上训练分类器,然后再把这些分类器组合起来。简单的多数投票一般就可以。其代表算法是随机森林。Boosting的意思是这样,他通过迭代地训练一系列的分类器,每个分类器采用的样本分布都和上一轮的学习结果有关。其代表算法是AdaBoost, GBDT。
其实就机器学习算法来说,其泛化误差可以分解为两部分,偏差(bias)和方差(variance)。这个可由下图的式子导出(这里用到了概率论公式 D ( X ) = E ( X 2 ) − [ E ( X ) ] 2 D(X)=E(X^2)-[E(X)]^2 D(X)=E(X2)−[E(X)]2)。偏差指的是算法的期望预测与真实预测之间的偏差程度,反应了模型本身的拟合能力;方差度量了同等大小的训练集的变动导致学习性能的变化,刻画了数据扰动所导致的影响。这个有点儿绕,不过你一定知道过拟合。
如下图所示,当模型越复杂时,拟合的程度就越高,模型的训练偏差就越小。但此时如果换一组数据可能模型的变化就会很大,即模型的方差很大。所以模型过于复杂的时候会导致过拟合。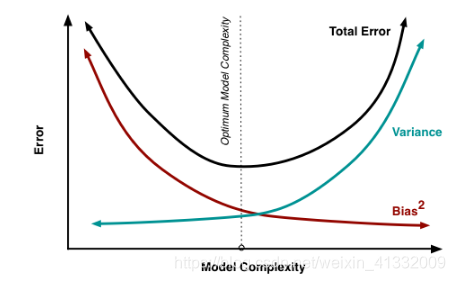
当模型越简单时,即使我们再换一组数据,最后得出的学习器和之前的学习器的差别就不那么大,模型的方差很小。还是因为模型简单,所以偏差会很大。
也就是说,当我们训练一个模型时,偏差和方差都得照顾到,漏掉一个都不行。
对于Bagging算法来说,由于我们会并行地训练很多不同的分类器的目的就是降低这个方差(variance) ,因为采用了相互独立的基分类器多了以后,h的值自然就会靠近.所以对于每个基分类器来说,目标就是如何降低这个偏差(bias),所以我们会采用深度很深甚至不剪枝的决策树。
对于Boosting来说,每一步我们都会在上一轮的基础上更加拟合原数据,所以可以保证偏差(bias),所以对于每个基分类器来说,问题就在于如何选择variance更小的分类器,即更简单的分类器,所以我们选择了深度很浅的决策树。
【问】怎么理解决策树、xgboost能处理缺失值?而有的模型(svm)对缺失值比较敏感呢?
【答】https://www.zhihu.com/question/58230411
文中大意:
1.sklearn中的有些工具包可以自动处理缺失值,这不代表算法本身可以处理缺失值。这种由工具包自己处理缺失值的方法是有问题的,因为自动补充缺失值的方法太过粗暴,应该让用户自己填充缺失值之后再喂给模型,因为用户对数据的理解是最深刻的。在软件工程领域,有个经典的哲学思想“let is fail”,指的是如果程序在运行中出现了错误,应该抛出异常(raise exception)而不是默默地装作没看到继续运行。
补充缺失值的方法:
- 方法1(快速简单但效果差):把数值型变量(numerical variables)中的缺失值用其所对应的类别中(class)的中位数(median)替换。把描述型变量(categorical variables)缺失的部分用所对应类别中出现最多的数值替代。
- 方法2(耗时费力但效果好):虽然依然是使用中位数和出现次数最多的数来进行替换,方法2引入了权重。即对需要替换的数据先和其他数据做相似度测量,在补全缺失点是相似的点的数据会有更高的权重W。
2.xgboost模型却能够处理缺失值,也就是说模型允许缺失值存在。
原论文中关于缺失值的处理就是与稀疏矩阵的处理看作一样。在寻找split point的时候,不会对该特征为missing的样本进行遍历统计,只对该列特征值为non-missing的样本上对应的特征值进行遍历,通过这个技巧来减少了为稀疏离散特征寻找split point的时间开销。在逻辑实现上,为了保证完备性,会分别处理将missing该特征值的样本分配到左叶子结点和右叶子结点的两种情形,计算增益后选择增益大的方向进行分裂即可。可以为缺失值或者指定的值指定分支的默认方向,这能大大提升算法的效率。如果在训练中没有缺失值而在预测中出现缺失,那么会自动将缺失值的划分方向放到右子树。
- 一些经验法则:
- 树模型对于缺失值的敏感度较低,大部分时候可以在数据有缺失时使用。
- 涉及到距离度量(distance measurement)时,缺失值变得重要。如K近邻算法(KNN)和支持向量机(SVM)。
参考资料
[1] https://zhuanlan.zhihu.com/p/83901304
[2] https://www.cnblogs.com/mantch/p/11164221.html
[3] https://www.cnblogs.com/Christina-Notebook/p/10038800.html
[4] https://blog.csdn.net/weixin_44633951/article/details/111708728