文章目录
1、如何改进模型?
当已经完成一个机器学习模型,而效果并不符合要求时,该如何进行改进?
改进的方向有如下:
1、获取更多训练集;
2、挑选特征,用更小的特征集进行学习;
3、获取训练集数据的更多特征信息,构建更大的特征集;
4、使用更复杂的特征(
)等;
5、减小
;
6、加大
。
2、模型评估方法
2.1 简单评估
1、将数据集按7:3划分为训练集和验证集
2、使用验证集验证训练模型的准确率:
使用
,或错误数量作为评估标准
2.2 特征评估
例如要对特征多项式进行选择,令d为多项式的最高幂
1、将数据集按6:2:2分为训练集(Train),交叉验证集(CV),验证集(Test)
2、使用交叉验证集的误差
来选出最佳d
3、使用训练集训练模型
4、使用验证集进行模型评估
2.3 偏差、方差评估
方差(variance),高方差→过拟合
偏差(bias),高偏差→欠拟合
还是之前确定多项式幂d的例子,随着d的增大,训练集和交叉验证集的误差如下图:
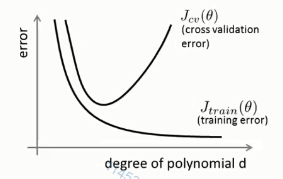
左侧对应的是高偏差(欠拟合),训练误差很大,检查验证误差也很大,两个接近
右侧对应的是高方差(过拟合),训练误差很小,检查验证远大于训练误差
2.3 正则化与偏差、方差
过大,高方差→过拟合
过小,高偏差→欠拟合
以
为横坐标,画出的误差图,与上图正好左右互换

3、学习曲线
以数据集的数量m作为横坐标,画出误差曲线
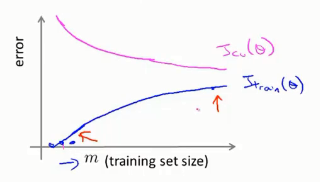
高偏差情况:
增加数据量对于模型改进意义不大

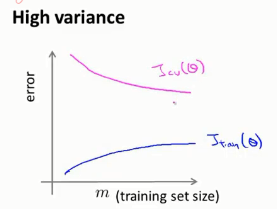
高方差情况:
增加训练数据对模型改进有用
4、改进模型的答案
1、获取更多训练集→高方差适用
2、挑选特征,用更小的特征集进行学习→高方差适用
3、获取训练集数据的更多特征信息,构建更大的特征集→高偏差适用
4、使用更复杂的特征(
)等→高偏差适用
5、减小
→高偏差适用
6、加大
→高方差适用
以上的内容也适合在神经网络,神经网络的隐藏层数量、神经元数量对应特征数量,选择方式也是一样的,多了会出现过拟合,这时候可以使用
处理。
大的神经网络+
会比小神经网络好。
5、学习系统设计
1、快速作出简单系统,先跑起来;
2、画出学习曲线,确定改进路线;
3、进行误差分析,对误差部分分析以改进系统
5.1 查准率、召回率
特别适用于不对称的分类问题,如信用卡欺诈、癌症筛选

TP: 预测为正,实际为正
TN: 预测为负,实际为负
FP:预测为正,实际为负
FN: 预测为负,实际为正
Precision = TP/(TP+FP); 查准率, 在所有被判断为正样本中, 真正正样本的数量.
Recall = TP/(TP+FN); 召回率, 在所有正样本中, 被识别为正样本的数量.
5.2 平衡查准率与召回率
F score:
5.3 数据量是算法的上限
1、数据越多算法预测越准确,多数据的差模型效果可能比少数据的好模型更好;
2、模型参数越多,模型越准确;
