9.应用机器学习的建议(Advice for Applying Machine Learning)
文章目录
本章编程作业及代码实现部分见:Python实现正则化的线性回归和偏差/方差
9.1 决定下一步做什么
本部分内容的目的是确保你在设计机器学习的系统时,明白怎样选择一条最合适、最正确的道路。具体来讲,我将重点关注的问题是假如你在开发一个机器学习系统,或者想试着改进一个机器学习系统的性能,你应如何决定接下来应该选择哪条道路?仍然使用预测房价的学习例子,假如你已经完成了正则化线性回归,也就是最小化代价函数 的值,在你得到你的学习参数以后,如果你要将你的假设函数放到一组新的房屋样本上进行测试,假如说你发现在预测房价时产生了巨大的误差,现在你的问题是要想改进这个算法,接下来应该怎么办?
实际上你可以想出很多种方法来改进这个算法的性能,其中一种办法是使用更多的训练样本。遗憾的是,我看到好多人花费了好多时间想收集更多的训练样本。他们总认为,要是我有两倍甚至十倍数量的训练数据,那就一定会解决问题的是吧?但有时候获得更多的训练数据实际上并没有作用。
另一个方法,你也许能想到的是尝试选用更少的特征集。因此如果你有一系列特征比如 等等。也许有很多特征,你可以花一点时间从这些特征中仔细挑选一小部分来防止过拟合。或者也许你需要用更多的特征,目前的特征集对你来讲并不是很有帮助,你希望从获取更多特征的角度来收集更多的数据。同样的道理,我们非常希望在花费大量时间完成这些工作之前,我们就能知道其效果如何。我们也可以尝试增加多项式特征的方法,比如 的平方, 的平方, 的乘积,我们可以花很多时间来考虑这一方法,我们也可以考虑其他方法减小或增大正则化参数 的值。我们列出的这个单子,上面的很多方法都可以扩展开来扩展成一个六个月或更长时间的项目。遗憾的是,大多数人用来选择这些方法的标准是凭感觉的,也就是说,大多数人的选择方法是随便从这些方法中选择一种。幸运的是,有一系列简单的方法能让你事半功倍,排除掉单子上的至少一半的方法,留下那些确实有前途的方法,同时也有一种很简单的方法,只要你使用,就能很轻松地排除掉很多选择,从而为你节省大量不必要花费的时间。最终达到改进机器学习系统性能的目的假设我们需要用一个线性回归模型来预测房价,当我们运用训练好了的模型来预测未知数据的时候发现有较大的误差,我们下一步可以做什么?
1. 获得更多的训练样本——通常是有效的,但代价较大,下面的方法也可能有效,可考虑先采用下面的几种方法。
2. 尝试减少特征的数量
3. 尝试获得更多的特征
4. 尝试增加多项式特征
5. 尝试减少正则化程度
6. 尝试增加正则化程度
我们不应该随机选择上面的某种方法来改进我们的算法,而是运用一些机器学习诊断法来帮助我们知道上面哪些方法对我们的算法是有效的。
首先介绍怎样评估机器学习算法的性能,然后将开始讨论这些方法,它们也被称为"机器学习诊断法"。“诊断法”的意思是:这是一种测试法,你通过执行这种测试,能够深入了解某种算法到底是否有用。这通常也能够告诉你,要想改进一种算法的效果,什么样的尝试,才是有意义的。这些诊断法的执行和实现,是需要花些时间的,有时候确实需要花很多时间来理解和实现,但这样做的确是把时间用在了刀刃上,因为这些方法让你在开发学习算法时,节省了几个月的时间,因此我将先来介绍如何评价你的学习算法。在此之后,我将介绍一些诊断法,希望能让你更清楚。在接下来的尝试中,如何选择更有意义的方法。
9.2 评估一个假设
介绍一下怎样用你学过的算法来评估假设函数。之后,我们将以此为基础来讨论如何避免过拟合和欠拟合的问题。

当我们确定学习算法的参数的时候,我们考虑的是选择参量来使训练误差最小化, 但是我们知道一味追求其误差最小化会出现过拟合现象。那么,你该如何判断一个假设函数是过拟合的呢?对于这个简单的例子,我们可以对假设函数 进行画图,然后观察图形趋势,但对于特征变量不止一个的这种一般情况,还有像有很多特征变量的问题,想要通过画出假设函数来进行观察,就会变得很难甚至是不可能实现。
因此,我们需要另一种方法来评估我们的假设函数过拟合检验。
为了检验算法是否过拟合,我们将数据分成训练集和测试集,通常用70%的数据作为训练集,用剩下30%的数据作为测试集。很重要的一点是训练集和测试集均要含有各种类型的数据,通常我们要对数据进行“洗牌”,然后再分成训练集和测试集。

测试集评估在通过训练集让我们的模型学习得出其参数后,对测试集运用该模型,我们有两种方式计算误差:
1. 对于线性回归模型,我们利用测试集数据计算代价函数
2. 对于逻辑回归模型,我们除了可以利用测试数据集来计算代价函数外:
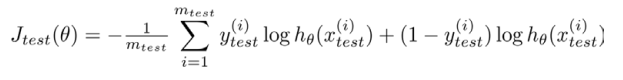
误分类的比率,对于每一个测试集样本,计算:
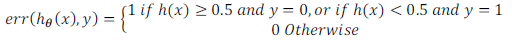
然后对计算结果求平均。
9.3 模型选择和交叉验证集
假设我们要在10个不同次数的二项式模型之间进行选择:

显然越高次数的多项式模型越能够适应我们的训练数据集,但是适应训练数据集并不代表着能推广至一般情况,我们应该选择一个更能适应一般情况的模型。我们需要使用交叉验证集来帮助选择模型。
即:使用60%的数据作为训练集,使用 20%的数据作为交叉验证集,使用20%的数据作为测试集。

模型选择的方法为:
1. 使用训练集训练出10个模型
2. 用10个模型分别对交叉验证集计算得出交叉验证误差(代价函数的值)
3. 选取代价函数值最小的模型
4. 用步骤3中选出的模型对测试集计算得出推广误差(代价函数的值)

9.4 诊断偏差和方差
当你运行一个学习算法时,如果这个算法的表现不理想,那么多半是出现两种情况:要么是偏差比较大,要么是方差比较大。换句话说,出现的情况要么是欠拟合,要么是过拟合问题。那么这两种情况,哪个和偏差有关,哪个和方差有关,或者是不是和两个都有关?搞清楚这一点非常重要,因为能判断出现的情况是这两种情况中的哪一种。其实是一个很有效的指示器,指引着可以改进算法的最有效的方法和途径。

我们通常会通过将训练集和交叉验证集的代价函数误差与多项式的次数绘制在同一张图表上来帮助分析:

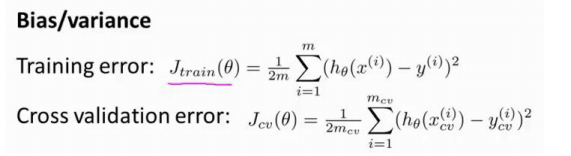

对于训练集,当
较小时,模型拟合程度更低,误差较大;随着
的增长,拟合程度提高,误差减小。
对于交叉验证集,当
较小时,模型拟合程度低,误差较大;但是随着
的增长,误差呈现先减小后增大的趋势,转折点是我们的模型开始过拟合训练数据集的时候。
如果我们的交叉验证集误差较大,我们如何判断是方差还是偏差呢?根据上面的图表,我们知道:

训练集误差和交叉验证集误差近似时:偏差/欠拟合
交叉验证集误差远大于训练集误差时:方差/过拟合
9.5 正则化和偏差/方差
在我们在训练模型的过程中,一般会使用一些正则化方法来防止过拟合。但是我们可能会正则化的程度太高或太小了,即我们在选择λ的值时也需要思考与刚才选择多项式模型次数类似的问题。

我们选择一系列的想要测试的
值,通常是 0-10之间的呈现2倍关系的值(如:
共12个)。 我们同样把数据分为训练集、交叉验证集和测试集。

选择 的方法为:
1. 使用训练集训练出12个不同程度正则化的模型
2. 用12个模型分别对交叉验证集计算的出交叉验证误差
3. 选择得出交叉验证误差最小的模型
4. 运用步骤3中选出模型对测试集计算得出推广误差,我们也可以同时将训练集和交叉验证集模型的代价函数误差与λ的值绘制在一张图表上:

• 当 较小时,训练集误差较小(过拟合)而交叉验证集误差较大。
• 随着 的增加,训练集误差不断增加(欠拟合),而交叉验证集误差则是先减小后增加。
9.6 学习曲线
学习曲线就是一种很好的工具,我经常使用学习曲线来判断某一个学习算法是否处于偏差、方差问题。学习曲线是学习算法的一个很好的合理检验(sanity check)。学习曲线是将训练集误差和交叉验证集误差作为训练集样本数量( )的函数绘制的图表。
即,如果我们有100行数据,我们从1行数据开始,逐渐学习更多行的数据。思想是:当训练较少行数据的时候,训练的模型将能够非常完美地适应较少的训练数据,但是训练出来的模型却不能很好地适应交叉验证集数据或测试集数据。


如何利用学习曲线识别高偏差/欠拟合:作为例子,我们尝试用一条直线来适应下面的数据,可以看出,无论训练集有多么大误差都不会有太大改观:

也就是说在高偏差/欠拟合的情况下,增加数据到训练集不一定能有帮助。
如何利用学习曲线识别高方差/过拟合:假设我们使用一个非常高次的多项式模型,并且正则化非常小,可以看出,当交叉验证集误差远大于训练集误差时,往训练集增加更多数据可以提高模型的效果。

也就是说在高方差/过拟合的情况下,增加更多数据到训练集可能可以提高算法效果。
9.7 决定下一步做什么
我们已经介绍了怎样评价一个学习算法,我们讨论了模型选择问题,偏差和方差的问题。那么这些诊断法则怎样帮助我们判断,哪些方法可能有助于改进学习算法的效果,而哪些可能是徒劳的呢?
让我们再次回到最开始的例子,在那里寻找答案,这就是我们之前的例子。回顾 1.1 中提出的六种可选的下一步,让我们来看一看我们在什么情况下应该怎样选择:
1. 获得更多的训练样本——解决高方差(过拟合)
2. 尝试减少特征的数量——解决高方差(过拟合)
3. 尝试获得更多的特征——解决高偏差(欠拟合)
4. 尝试增加多项式特征——解决高偏差(欠拟合)
5. 尝试减少正则化程度λ——解决高偏差(欠拟合)
6. 尝试增加正则化程度λ——解决高方差(过拟合)
神经网络的方差和偏差:

使用较小的神经网络,类似于参数较少的情况,容易导致高偏差和欠拟合,但计算代价较小使用较大的神经网络,类似于参数较多的情况,容易导致高方差和过拟合,虽然计算代价比较大,但是可以通过正则化手段来调整而更加适应数据。
通常选择较大的神经网络并采用正则化处理会比采用较小的神经网络效果要好。
对于神经网络中的隐藏层的层数的选择,通常从一层开始逐渐增加层数,为了更好地作选择,可以把数据分为训练集、交叉验证集和测试集,针对不同隐藏层层数的神经网络训练神经网络,
然后选择交叉验证集代价最小的神经网络。
参考资料: 吴恩达机器学习课程;黄海广机器学习课程笔记