作者:贺旭 (中央财经大学)
Stata连享会 计量专题 || 精品课程 || 简书推文 || 公众号合集

连享会计量方法专题……
本文介绍交叉验证方法,然后以 kfoldclass 命令和 crossfold 为范例使读者更深入的了解该方法。
该方法在 RDD 分析中确定最优带宽时非常有用。
1 交叉验证的介绍
1.1 交叉验证的含义是什么?
交叉验证,顾名思义,就是重复的使用数据。具体来说,就是把样本数据切成 K 份,组合为不同的训练集和测试集,用训练集来训练模型,用测试集来评估模型预测的好坏。在此基础上可以得到多组不同的训练集和测试集,某次训练集中的某样本在下次可能成为测试集中的样本,即所谓“交叉”。
1.2 交叉验证有什么作用?
第一,交叉验证可以多次的使用数据,有助于解决数据补充足的问题;
第二,交叉验证有助于防止过度拟合(模型样本内拟合的很好,样本外却很糟糕);
第三,用交叉验证来来进行模型的评价与选择。
1.3 常用的交叉验证有哪些方法?
K 折叠交叉验证 (K-fold Cross Validation)
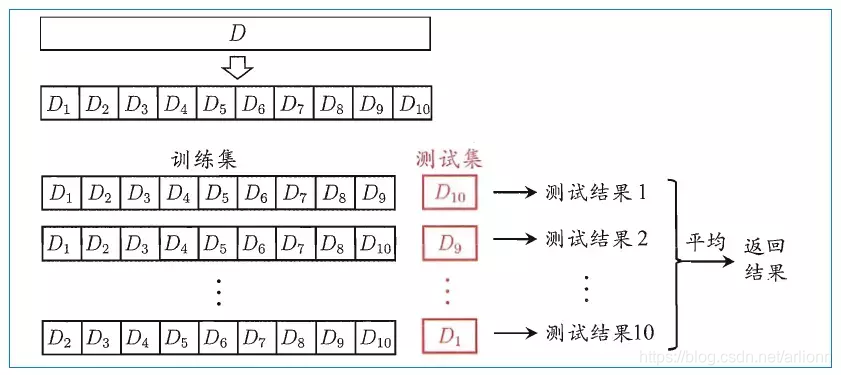
将所有样本分割为大小相等的 K 组,每次取其中的一份为测试集,其他的为训练集,最后根据测试结果来评价模型。
例如:将数据集粗略地分为比较均等不相交的 10 份,然后取其中的 1 份进行测试,另外的 9 份进行训练,然后求得预测误差的平均值作为最终的评价。如图:
留一法 (Leave One Out)
如果 K 的值为样本的个数,也就是每次取 1 个样本作为测试集,剩下的为训练集来训练模型,最后根据测试结果来评价模型。
留 P 法 (Leave P Out)
它从完整的样本集中每次取 P 个样本作为测试集,剩下的作为训练集来训练模型,最后根据测试结果来评价模型。
连享会计量方法专题……
2. 范例:运用 crossfold 命令对线性回归模型等模型进行K折叠交叉验证
命令 crossfold 可以对线性回归模型、分位数回归模型等多种模型进行交叉验证,,并且报告交叉验证的 MAE、RMSE 、psuedo-R-squared(因变量预测值与实测值的相关系数的平方)等指标,用以评价模型。
2.1 crossfold 命令的语法格式
其语法格式为:
crossfold model [model_if] [model_in] [model_weight],
[eif()] [ein()] [eweight(varname)]
[stub(string)] [k(value)] [loud]
[mae] [r2]
[model_options]
其中:
model为要估计的模型;eweight在计算模型的预测指标时,赋予各预测误差值得的权重;stub()将估计的结果保存并起一个名称,放入括号中;k()设置交叉验证的次数;loud将分为K组的每组估计结果显示在窗口中;mae显示交叉验证的 MAE,如果不选,默认显示RMSE;r2显示交叉验证的 psuedo-R-squared,如果不选,默认显示RMSE;
2.2 实例演示
导入数据后,做一个线性回归,并报告 MAE。
. sysuse nlsw88
. crossfold reg wage union, mae
报告的结果显示为
| MAE
-------------+-----------
est1 | 3.173351
est2 | 3.098101
est3 | 3.112503
est4 | 2.997055
est5 | 2.968615
该结果同时会以矩阵储存在 r(stub) 中,stub为命令stub中所起的名字,如果没有,默认储存在 r(est) 中。
3. 范例:运用 kfoldclass 命令对二元结果模型进行交叉验证
命令 kfoldclass 可以在 Stata 中对模型进行K折叠交叉验证 (K-fold Cross Validation),但是其使用有两个限制:其一,是该命令只适用于用于二结果模型(比如 Logit 模型等);其二,是在该命令中添加的模型选项前,需要确认该 Stata 已经安装有关模型模块。
3.1 kfoldclass 命令的语法格式
其语法格式为:
kfoldclass depvar indepvars [if] [in] [weight] , model(str) [k(#) cutoff(#) save figure model_options]
其中:
depvar为被解释变量;indepvars为解释变量;model为被用来进行交叉验证的的模型,包括logit,probit,randomforest,boost, -svmachines(使用前需要确保这些模块都已经安装);k为将样本分为多少组进行交叉验证,默认值为5;cutoff(#)为在 classification tables(分类表)判断预测结果为正的概率的阈值,阈值默认值为0.5。比如:模型拟合值为0.7,若阈值设置为0.6,因为0.7 > 0.6则将预测结果为正。save意思是将模型拟合的值保存在数据表格中,包括两个结果,第一个是结果变量名为 full,其将所有样本数据来计算模型参数,然后再用所有样本数据计算拟合值;第二个结果变量名为 test,将用训练集来计算模型参数,用计算出的模型参数来在测试集中计算拟合值。figure选择该选项可画出全部数据和测试数据的 ROC 曲线,如果 ROC 曲线越凸向 (0,1) 点,则说明模型的 ACU 值越大,预测效果越好,关于 ROC 曲线和 ACU 值的一个通俗的介绍参考 《 简单梳理对AUC的理解 》; 《 AUC,ROC我看到的最透彻的讲解 》。
3.2 实例演示
首先导入数据然后按照 kfoldclass 的语法格式 输入命令
. webuse lbw, clear
. kfoldclass low age lwt i.race smoke ptl ht ui, model(logit) k(5) save fig
其中,模型选择的是 logit 模型,将数据分为5组,保存拟合值,并画出 ROC 曲线。
首先,呈现 ROC 曲线,如图:

如果 ROC 越偏向左上角,这说明模型预测效果越好,同时图片下方还计算了 AUC 的值(也就是横坐标从 0 到 1 曲线下方的面积),全部样本的AUC值为 0.7462,测试样本的 AUC 值为 0.6716。
同时还会显示以下表格:
表格 1
Classification Table for Full Data:
-------- True --------
Classified | D ~D | Total
-----------+--------------------------+-----------
+ | 21 12 | 33
- | 38 118 | 156
-----------+--------------------------+-----------
Total | 59 130 | 189
这个表格是用全部样本作为训练集,然后用全部样本作为测试集,最后的统计结果。其中:纵坐标 + 表示拟合值等于 1 的数目,- 表示拟合值等于 0 的数目;横坐标 D 代表真实等于 1 的数目 ,~D 代表真实值等于 0 的数目。
表格 2
Classification Table for Test Data:
-------- True --------
Classified | D ~D | Total
-----------+--------------------------+-----------
+ | 19 19 | 38
- | 40 111 | 151
-----------+--------------------------+-----------
Total | 59 130 | 189
这个表格表示的是:将样本分为 5 组,分别用其中一组为测试集集,然后用剩下的所有组的样本作为训练集,然后根据设置的阈值判断拟合的结果,这样循环 5 次使每一组都做过一次测试集。其中:纵坐标 + 表示拟合值等于 1 的数目,- 表示拟合值等于 0 的数目;横坐标 D 代表真实等于 1 的数目 ,~D 代表真实值等于 0 的数目。
表格 3
Classified + if predicted Pr(D) >= .5
True D defined as != 0
Full Test
----------------------------------------------------------------
Sensitivity Pr( +| D) 35.59% 32.20%
Specificity Pr( -|~D) 90.77% 85.38%
Positive predictive value Pr( D| +) 63.64% 50.00%
Negative predictive value Pr(~D| -) 75.64% 73.51%
----------------------------------------------------------------
False + rate for true ~D Pr( +|~D) 9.23% 14.62%
False - rate for true D Pr( -| D) 64.41% 67.80%
False + rate for classified + Pr(~D| +) 36.36% 50.00%
False - rate for classified - Pr( D| -) 24.36% 26.49%
----------------------------------------------------------------
Correctly classified 73.54% 68.78%
----------------------------------------------------------------
ROC area 0.7462 0.6716
----------------------------------------------------------------
p-value for Full vs Test ROC areas 0.0000
----------------------------------------------------------------
具体说明如下:
- 第一列为变量名;
- 第二列为变量的含义:比如 Pr( +| D) 代表在真实值为 1 的集合中,预测也为 1 的样本数量占真实值为 1 集合的比率,Pr( -|~D) 代表真实值为 0 的集合中,预测为 0 的样本占真实值为 0 集合中样本数目的比率)
- 第三列为用全部数据训练模型得到的变量值;
- 第四列为用交叉验证法训练模型得到的变量值。
Correctly classified 表示预测的准确率,也就是预测对的样本数占所有样本的数量。
ROC area 表示 AUC 值,也就是 ROC 曲线下方的面积。
对各种评价指标的计算及定义具体参考 [《 机器学习:准确率 (Precision)、召回率 (Recall)、F值(F-Measure)、ROC 曲线、PR 曲线 》]。
4 文献推荐
- Efron B , Gong G . A Leisurely Look at the Bootstrap, the Jackknife, and Cross-Validation[J]. The American Statistician, 1983, 37(1):36-48. [PDF]
- Arlot S , Celisse A . A survey of cross-validation procedures for model selection[J]. Statistics Surveys, 2009, 4(2010):40-79. [PDF]
- Zhang Y , Yang Y . Cross-validation for selecting a model selection procedure[J]. Journal of Econometrics, 2015, 187(1):95-112. [PDF]
参考资料
关于我们
- 「Stata 连享会」 由中山大学连玉君老师团队创办,定期分享实证分析经验, 公众号:StataChina。
- 公众号推文同步发布于 CSDN 、简书 和 知乎Stata专栏。可在百度中搜索关键词 「Stata连享会」查看往期推文。
- 点击推文底部【阅读原文】可以查看推文中的链接并下载相关资料。
- 欢迎赐稿: 欢迎赐稿。录用稿件达 三篇 以上,即可 免费 获得一期 Stata 现场培训资格。
- E-mail: [email protected]
- 往期推文:计量专题 || 精品课程 || 简书推文 || 公众号合集

