Evaluation of Topic Modeling:Topic coherence
we will go through the evaluation of Topic Modelling by introducing the concept of Topic coherence, as topic models give no guaranty on the interpretability of their output. Topic modeling provides us with methods to organize, understand and summarize large collections of textual information. There are many techniques that are used to obtain topic models. Latent Dirichlet Allocation (LDA) is a widely used topic modeling technique to extract topic from the textual data.
我们将通过引入主题一致性的概念来进行主题建模的评估,因为主题模型不能保证其输出的可解释性。 主题建模为我们提供了组织,理解和总结大量文本信息的方法。 有许多技术用于获取主题模型。 Latent Dirichlet Allocation(LDA)是一种广泛使用的主题建模技术,用于从文本数据中提取主题。
Topic models learn topics—typically represented as sets of important words—automatically from unlabelled documents in an unsupervised way. This is an attractive method to bring structure to otherwise unstructured text data, but Topics are not guaranteed to be well interpretable, therefore, coherence measures have been proposed to distinguish between good and bad topics.
主题模型以无监督的方式自动从未标记的文档中学习主题 - 通常表示为重要单词集。 这是一种将结构引入其他非结构化文本数据的有吸引力的方法,但主题并不能保证很好地解释,因此,已经提出了一致性度量来区分好主题和坏主题。
Let’s start learning with a simple example and then we move to a technical part of topic coherence.
让我们从一个简单的例子开始学习,然后我们转向主题一致性的技术部分。
Imagine you are a lead quality analyst sitting at location X at a logistics company and you want to check the quality of your dispatch product at 4 different locations: A, B, C, D. One way is to collect the reviews from various people – for example- “whether they receive product in good condition”, Did they receive on time”. You may need to improve your process if most people give you bad reviews. So, basically, you are evaluating on the qualitative approach, as there is no quantitative measure involved, which can tell you how much worse your dispatch product quality at A is compared to dispatch quality at B.
想象一下,您是位于物流公司X地点的首席质量分析师,您想在4个不同的位置检查您的调度产品的质量:A,B,C,D。一种方法是收集来自不同人的评论 - 例如 - “他们是否收到状况良好的产品”,他们是否按时收到“。如果大多数人给你不好的评论,你可能需要改进你的过程。因此,基本上,您正在评估定性方法,因为没有涉及定量测量,这可以告诉您A的调度产品质量与B的调度质量相比有多差。
To arrive at the quantitative measure, your central lab at X set up 4 different quality lab Kiosk at A, B, C and D to check the dispatch product quality (let’s say quality defined by % of conformance as per some predefined standards). Now, while sitting at the central lab, you can get the quality values from 4 Kiosks and can compute your overall quality. You don’t need to rely on people reviews, as you have a good quantitative measure of quality.
为了达到定量测量,您在X的中心实验室在A,B,C和D处设置了4个不同质量的实验室信息亭,以检查调度产品质量(假设质量由符合某些预定义标准的百分比定义)。现在,坐在中心实验室,您可以从4个信息亭获得质量值,并可以计算您的整体质量。您不需要依赖人员评论,因为您有良好的质量定量指标。
Here the analogy comes in:
The dispatch product here is the topics from some topic modeling algorithm such as LDA. The qualitative approach is to test the topics on their human interpretability by presenting them to humans and taking their input on them. The quality lab setup is the topic coherence framework, which is grouped into 4 following dimensions:
这里的比喻来自:
这里的调度产品是来自某些主题建模算法(如LDA)的主题。 定性方法是通过将这些主题呈现给人类并对其进行输入来测试关于其人类可解释性的主题。 质量实验室设置是主题一致性框架,分为以下4个维度:
- Segmentation: A lot of dispatch product divided into different sub-lot sizes, such that each sub-lot product are different.
- Probability Estimation: Quantitative Measurement of sub lot quality.
- Confirmation Measure: Determine quality as per some predefined standard (say % conformance) and assign some number to qualify. For example, 75% of products are good quality as per XXX standard.
Aggregation: It’s the central lab where you combine all the quality numbers and derive a single number for overall quality.
细分:许多调度产品分为不同的子批量,每个子批次产品都不同。
- 概率估计:子批次质量的定量测量。
- 确认度量:根据某些预定义的标准(比如%一致性)确定质量并指定一些数字以符合条件。 例如,根据XXX标准,75%的产品质量良好。
- 聚合:这是中心实验室,您可以将所有质量数字组合在一起,并为整体质量得出一个数字。
From a technical point of view, Coherence framework is represented as a composition of parts that can be combined. The parts are grouped into dimensions that span the configuration space of coherence measures. Each dimension is characterized by a set of exchangeable components.
从技术角度来看,一致性框架表示为可以组合的部件组合。 这些部件被分组为跨越一致性度量的配置空间的维度。 每个维度都由一组可交换组件表征。
First, the word set t is segmented into a set of pairs of word subsets S. Second, word probabilities P are computed based on a given reference corpus. Both, the set of word subsets S as well as the computed probabilities P are consumed by the confirmation measure to calculate the agreements ϕ of pairs of S. Last, those values are aggregated to a single coherence value c.
首先,将单词集t分割成一组单词子集S对。其次,基于给定的参考语料库计算单词概率P. 确定度量消耗字集子集S以及计算概率P两者以计算S对的协议φ。最后,将这些值聚合为单个一致性值c。
There are 2 measures in Topic coherence :
主题一致性有两个衡量标准:
Intrinsic Measure
内在度量
It is represented as UMass. It measures to compare a word only to the preceding and succeeding words respectively, so need ordered word set.It uses as pairwise score function which is the empirical conditional log-probability with smoothing count to avoid calculating the logarithm of zero.
它表示为UMass。 它只测量一个单词与前后单词的比较,因此需要有序单词集。它用作成对分数函数,它是具有平滑计数的经验条件对数概率,以避免计算零的对数。
Extrinsic Measure
外在度量
It is represented as UCI. In UCI measure, every single word is paired with every other single word. The UCI coherence uses pointwise mutual information (PMI).
它表示为UCI。 在UCI度量中,每个单词都与其他单个单词配对。 UCI一致性使用逐点互信息(PMI)。
Both Intrinsic and Extrinsic measure compute the coherence score c (sum of pairwise scores on the words w1, …, wn used to describe the topic).
If you are interested to learn in more detail, refer this paper :- Exploring the Space of Topic Coherence Measures
内在和外在度量都计算一致性得分c(用于描述主题的词w1,…,wn的成对得分之和)。
如果您有兴趣更详细地学习,请参阅本文: - Exploring the Space of Topic Coherence Measures
Implementation in Python
在Python中实现
Amazon fine food review dataset, publicly available on Kaggle is used for this paper. Since dataset is very huge, only 10,000 reviews are considered. Since we are focusing on topic coherence, I am not going in details for data pre-processing here.
亚马逊精美食品评论数据集,在Kaggle上公开可用于本文。 由于数据集非常庞大,因此只考虑了10,000条评论。 由于我们专注于主题一致性,因此我不会详细介绍数据预处理。
It consists of following steps:
它包括以下步骤:
Step 1
First step is loading packages, Data and Data pre-processing.
We created dictionary and corpus required for Topic Modeling: The two main inputs to the LDA topic model are the dictionary and the corpus. Gensim creates a unique id for each word in the document. The produced corpus shown above is a mapping of (word_id, word_frequency). For example, (0, 1) below in the output implies, word id 0 occurs once in the first document.
第一步是加载包,数据和数据预处理。
我们创建了主题建模所需的字典和语料库:LDA主题模型的两个主要输入是字典和语料库。 Gensim为文档中的每个单词创建一个唯一的ID。 上面显示的产生的语料库是(word_id,word_frequency)的映射。 例如,输出中的下面的(0,1)表示,单词id 0在第一个文档中出现一次。
# Import required packages
import numpy as np
import logging
import pyLDAvis.gensim
import json
import warnings
warnings.filterwarnings('ignore') # To ignore all warnings that arise here to enhance clarity
from gensim.models.coherencemodel import CoherenceModel
from gensim.models.ldamodel import LdaModel
from gensim.corpora.dictionary import Dictionary
from numpy import array
# Import dataset
p_df = pd.read_csv('C:/Users/kamal/Desktop/R project/Reviews.csv')
# Create sample of 10,000 reviews
p_df = p_df.sample(n = 10000)
# Convert to array
docs =array(p_df['Text'])
# Define function for tokenize and lemmatizing
from nltk.stem.wordnet import WordNetLemmatizer
from nltk.tokenize import RegexpTokenizer
def docs_preprocessor(docs):
tokenizer = RegexpTokenizer(r'\w+')
for idx in range(len(docs)):
docs[idx] = docs[idx].lower() # Convert to lowercase.
docs[idx] = tokenizer.tokenize(docs[idx]) # Split into words.
# Remove numbers, but not words that contain numbers.
docs = [[token for token in doc if not token.isdigit()] for doc in docs]
# Remove words that are only one character.
docs = [[token for token in doc if len(token) > 3] for doc in docs]
# Lemmatize all words in documents.
lemmatizer = WordNetLemmatizer()
docs = [[lemmatizer.lemmatize(token) for token in doc] for doc in docs]
return docs
# Perform function on our document
docs = docs_preprocessor(docs)
#Create Biagram & Trigram Models
from gensim.models import Phrases
# Add bigrams and trigrams to docs,minimum count 10 means only that appear 10 times or more.
bigram = Phrases(docs, min_count=10)
trigram = Phrases(bigram[docs])
for idx in range(len(docs)):
for token in bigram[docs[idx]]:
if '_' in token:
# Token is a bigram, add to document.
docs[idx].append(token)
for token in trigram[docs[idx]]:
if '_' in token:
# Token is a bigram, add to document.
docs[idx].append(token)
#Remove rare & common tokens
# Create a dictionary representation of the documents.
dictionary = Dictionary(docs)
dictionary.filter_extremes(no_below=10, no_above=0.2)
#Create dictionary and corpus required for Topic Modeling
corpus = [dictionary.doc2bow(doc) for doc in docs]
print('Number of unique tokens: %d' % len(dictionary))
print('Number of documents: %d' % len(corpus))
print(corpus[:1])Number of unique tokens: 4214
Number of documents: 10000
[[(0, 1), (1, 1), (2, 2), (3, 1), (4, 1), (5, 1), (6, 4), (7, 2), (8, 1), (9, 2), (10, 5), (11, 8), (12, 3), (13, 1), (14, 2), (15, 1), (16, 2), (17, 2), (18, 3), (19, 3), (20, 1), (21, 1), (22, 1), (23, 2), (24, 1), (25, 1), (26, 1), (27, 1), (28, 1), (29, 2), (30, 1), (31, 2), (32, 2), (33, 1), (34, 1), (35, 1), (36, 1), (37, 2), (38, 3)]]Step 2
We have everything required to train the LDA model. In addition to the corpus and dictionary, we need to provide the number of topics as well.Set number of topics=5.
我们拥有训练LDA模型所需的一切。 除语料库和字典外,我们还需要提供主题数量。设置主题数量= 5。
# Set parameters.
num_topics = 5
chunksize = 500
passes = 20
iterations = 400
eval_every = 1
# Make a index to word dictionary.
temp = dictionary[0] # only to "load" the dictionary.
id2word = dictionary.id2token
lda_model = LdaModel(corpus=corpus, id2word=id2word, chunksize=chunksize, \
alpha='auto', eta='auto', \
iterations=iterations, num_topics=num_topics, \
passes=passes, eval_every=eval_every)
# Print the Keyword in the 5 topics
print(lda_model.print_topics())[(0, '0.067*"coffee" + 0.012*"strong" + 0.011*"green" + 0.010*"vanilla" + 0.009*"just_right" + 0.009*"cup" + 0.009*"blend" + 0.008*"drink" + 0.008*"http_amazon" + 0.007*"bean"'), (1, '0.046*"have_been" + 0.030*"chocolate" + 0.021*"been" + 0.021*"gluten_free" + 0.018*"recommend" + 0.017*"highly_recommend" + 0.014*"free" + 0.012*"cooky" + 0.012*"would_recommend" + 0.011*"have_ever"'), (2, '0.028*"food" + 0.018*"amazon" + 0.016*"from" + 0.015*"price" + 0.012*"store" + 0.011*"find" + 0.010*"brand" + 0.010*"time" + 0.010*"will" + 0.010*"when"'), (3, '0.019*"than" + 0.013*"more" + 0.012*"water" + 0.011*"this_stuff" + 0.011*"better" + 0.011*"sugar" + 0.009*"much" + 0.009*"your" + 0.009*"more_than" + 0.008*"which"'), (4, '0.010*"would" + 0.010*"little" + 0.010*"were" + 0.009*"they_were" + 0.009*"treat" + 0.009*"really" + 0.009*"make" + 0.008*"when" + 0.008*"some" + 0.007*"will"')]Step 3
LDA is an unsupervised technique, meaning that we don’t know prior to running the model how many topics exits in our corpus.You can use LDA visualization tool pyLDAvis, tried a few numbers of topics and compared the results. Topic coherence is one of the main techniques used to estimate the number of topics.We will use both UMass and c_v measure to see the coherence score of our LDA model.
LDA是一种无监督的技术,这意味着我们在运行模型之前不知道在我们的语料库中有多少主题存在。您可以使用LDA可视化工具pyLDAvis,尝试了一些主题并比较了结果。 主题一致性是用于估计主题数量的主要技术之一。我们将使用UMass和c_v度量来查看LDA模型的一致性得分。
Using c_v Measure
# Compute Coherence Score using c_v
coherence_model_lda = CoherenceModel(model=lda_model, texts=docs, dictionary=dictionary, coherence='c_v')
coherence_lda = coherence_model_lda.get_coherence()
print('\nCoherence Score: ', coherence_lda)Coherence Score: 0.359704263036Using UMass Measure
# Compute Coherence Score using UMass
coherence_model_lda = CoherenceModel(model=lda_model, texts=docs, dictionary=dictionary, coherence="u_mass")
coherence_lda = coherence_model_lda.get_coherence()
print('\nCoherence Score: ', coherence_lda)Coherence Score: -2.60591638507Step 4
The last step is to find the optimal number of topics.We need to build many LDA models with different values of the number of topics (k) and pick the one that gives the highest coherence value. Choosing a ‘k’ that marks the end of a rapid growth of topic coherence usually offers meaningful and interpretable topics. Picking an even higher value can sometimes provide more granular sub-topics. If you see the same keywords being repeated in multiple topics, it’s probably a sign that the ‘k’ is too large.
最后一步是找到最佳主题数。我们需要构建许多具有不同主题数(k)值的LDA模型,并选择一个具有最高一致性值的模型。 选择一个标志着主题一致性快速增长的“k”通常会提供有意义和可解释的主题。 选择更高的值有时可以提供更精细的子主题。 如果您在多个主题中看到相同的关键字重复,则可能表示“k”太大。
Using c_v Measure
def compute_coherence_values(dictionary, corpus, texts, limit, start=2, step=3):
"""
Compute c_v coherence for various number of topics
Parameters:
----------
dictionary : Gensim dictionary
corpus : Gensim corpus
texts : List of input texts
limit : Max num of topics
Returns:
-------
model_list : List of LDA topic models
coherence_values : Coherence values corresponding to the LDA model with respective number of topics
"""
coherence_values = []
model_list = []
for num_topics in range(start, limit, step):
model=LdaModel(corpus=corpus, id2word=dictionary, num_topics=num_topics)
model_list.append(model)
coherencemodel = CoherenceModel(model=model, texts=texts, dictionary=dictionary, coherence='c_v')
coherence_values.append(coherencemodel.get_coherence())
return model_list, coherence_valuesCreate a model list and plot Coherence score against a number of topics
创建模型列表并根据一些主题绘制一致性得分
model_list, coherence_values = compute_coherence_values(dictionary=dictionary, corpus=corpus, texts=docs, start=2, limit=40, step=6)
# Show graph
import matplotlib.pyplot as plt
limit=40; start=2; step=6;
x = range(start, limit, step)
plt.plot(x, coherence_values)
plt.xlabel("Num Topics")
plt.ylabel("Coherence score")
plt.legend(("coherence_values"), loc='best')
plt.show()Gives this plot:
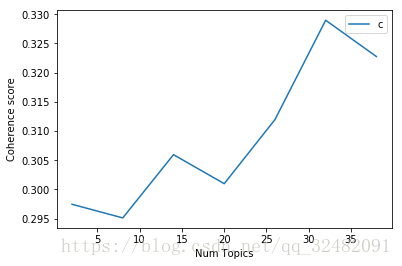
The above plot shows that coherence score increases with the number of topics, with a decline between 15 to 20.Now, choosing the number of topics still depends on your requirement because topic around 33 have good coherence scores but may have repeated keywords in the topic. Topic coherence gives you a good picture so that you can take better decision.
You can try the same with U mass measure.
上图显示,一致性得分随着主题数量的增加而增加,下降幅度在15到20之间。现在,选择主题数仍然取决于您的要求,因为33左右的主题具有良好的一致性分数,但可能在主题中重复关键词。 主题一致性为您提供了良好的图像,以便您可以做出更好的决策。
您可以尝试使用U MASS度量。
Conclusion
To conclude, there are many other approaches to evaluate Topic models such as Perplexity, but its poor indicator of the quality of the topics.Topic Visualization is also a good way to assess topic models. Topic Coherence measure is a good way to compare difference topic models based on their human-interpretability.The u_mass and c_v topic coherences capture the optimal number of topics by giving the interpretability of these topics a number called coherence score.
总而言之,还有许多其他方法来评估主题模型,如困惑,但它的主题质量指标很差.Topic Visualization也是评估主题模型的好方法。 主题一致性度量是一种基于人类可解释性比较差异主题模型的好方法.u_mass和c_v主题一致性通过将这些主题的可解释性称为一致性得分来捕获最佳主题数量。
针对一些评论,作者Kamal Kumar的回答如下:
Q:I need to classify the result topics(lda) using binary classier.
advice me!!
A:You can use document topic distribution as feature vector to classifier.
In sklearn , you can get this by lda.fit_transform(tf).
Q:我需要使用二进制分类器对结果主题(lda)进行分类。
建议我!!
A:您可以将文档主题分布用作分类器的特征向量。
在sklearn中,您可以通过lda.fit_transform(tf)获得此信息。Q:How can you define c_v?
A:CV is based on a sliding window, a one-set segmentation of the top words and an indirect confirmation measure that uses normalized pointwise mutual information (NPMI) and the cosinus similarity.
CUCI is a coherence that is based on a sliding window and the pointwise mutual information (PMI) of all word pairs of the given top words.
CUMass is based on document cooccurrence counts, a one-preceding segmentation and a logarithmic conditional probability as confirmation measure.
Q:你怎么定义c_v?
A:CV基于滑动窗口,顶部单词的一组分段和使用标准化逐点互信息(NPMI)和余弦相似性间接确认度量。
CUCI是基于滑动窗口和给定顶部单词的所有单词对的逐点互信息(PMI)的一致性。
CUMass基于文档共生计数,一个单前述分段和一个对数条件概率作为确认度量。Q:Thank you so much. Another doubt i have is apart from a quantitative value we obtain through coherence, does it have an actual relation with the goodness of model?
A:Yes, you can say that. If we see in above code , compute_coherence_ values trains multiple LDA models and gives us their corresponding coherence scores.Its good to consider model with highest coherence scores.In short ,It measures how often the topic words appear together in the corpus.
Q:Oh k but as per above graph there are multiple high values for coherence so what is a good coherence value in that case? I beleive the coherence Of model is the mean of all the topic coherence combined or some similar measure is that rite any idea on that kamal? Because there is option I found which gets us coherence if topics of a model. Sorry for bombarding with lot of questions. Jus confused
A:As I mentioned in the article , 33 Topics have good coherence score ( peak shown ). But again this depends upon your requirement and case to case. LDA is one method of Topic Modelling. You can compare Coherence scores of Topics generated by different Topic model and then use the topic model accordingly.
Q:非常感谢你。我所拥有的另一个疑问是,除了通过连贯性获得的定量值之外,它是否与模型的优点有实际关系?
A:是的,你可以这么说。如果我们在上面的代码中看到,compute_coherence_values训练多个LDA模型并给出它们相应的一致性得分。很好地考虑具有最高一致性得分的模型。简而言之,它测量主题词在语料库中一起出现的频率。
Q:哦,但是如上图所示,对于一致性有多个高值,那么在这种情况下什么是良好的一致性值?我相信模型的一致性是所有主题一致性的组合的平均值,或者某种类似的衡量标准是关于那个kamal的任何想法吗?因为我找到的选项可以让我们在模型的主题上保持一致性。很抱歉有很多问题轰炸。很困惑
A:正如我在文章中提到的,33个主题具有良好的一致性得分(显示峰值)。但这又取决于您的要求和具体情况。 LDA是主题建模的一种方法。您可以比较由不同主题模型生成的主题的Coherence分数,然后相应地使用主题模型。