最近在都应中刷到一本B站的漫画《我家娘子竟然是女帝》,它是根据小说《迎娶女帝之后》改编的,它目前只更新到68集,这本小说虽然不是我喜欢的类型,但是没啥事就看了一下,但是后面章节怎么找都找不到下载,于是用python把整本说下载下来了。
安装python
官方下载地址:https://www.python.org/downloads/
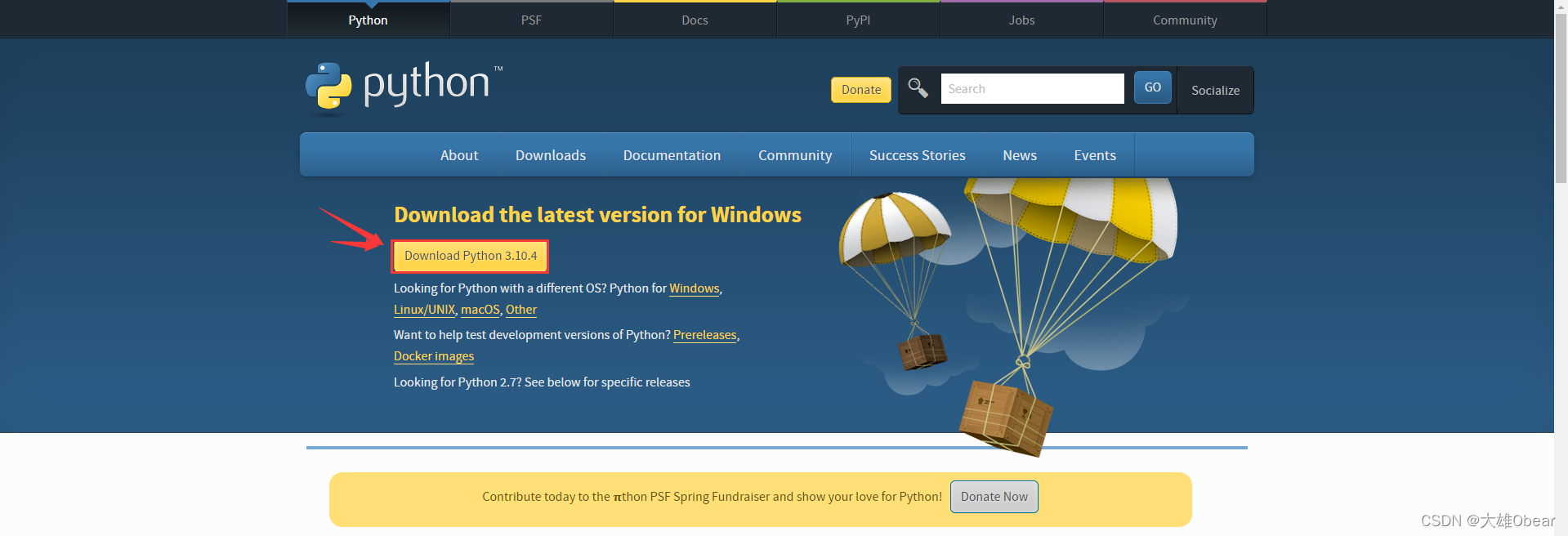
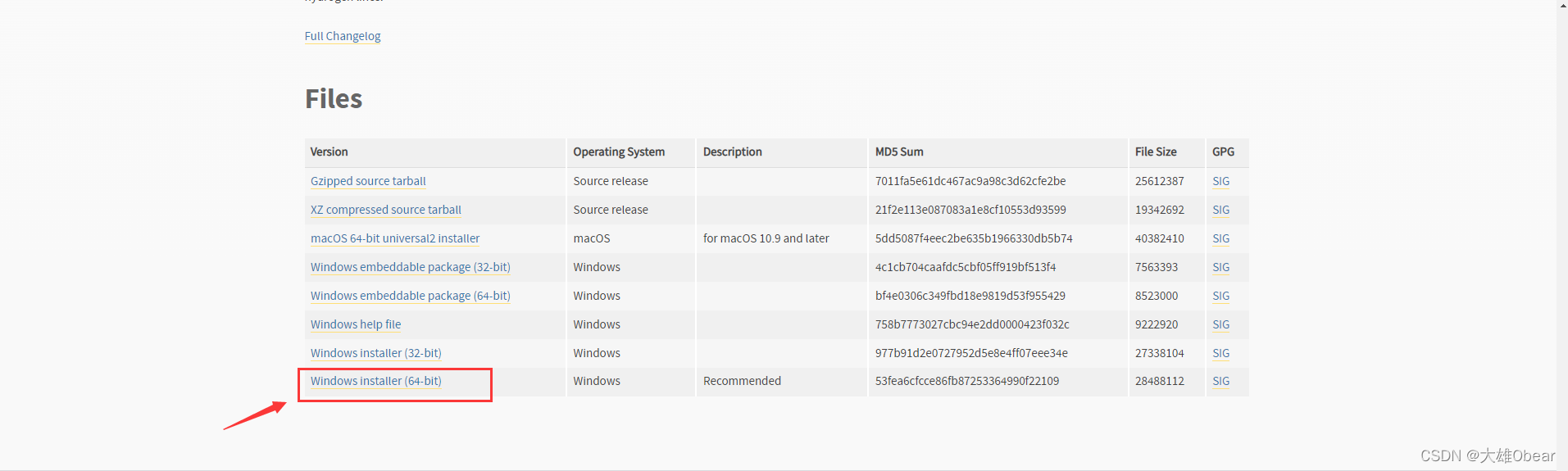
windows版本的安装比较简单,直接下载后,安装即可。
网站分析
获取小说目录
小说地址:https://www.81zw.com/book/60503/

就以第一张为例,点开链接,检查网页,找到这本小说所有章节的链接和名称。
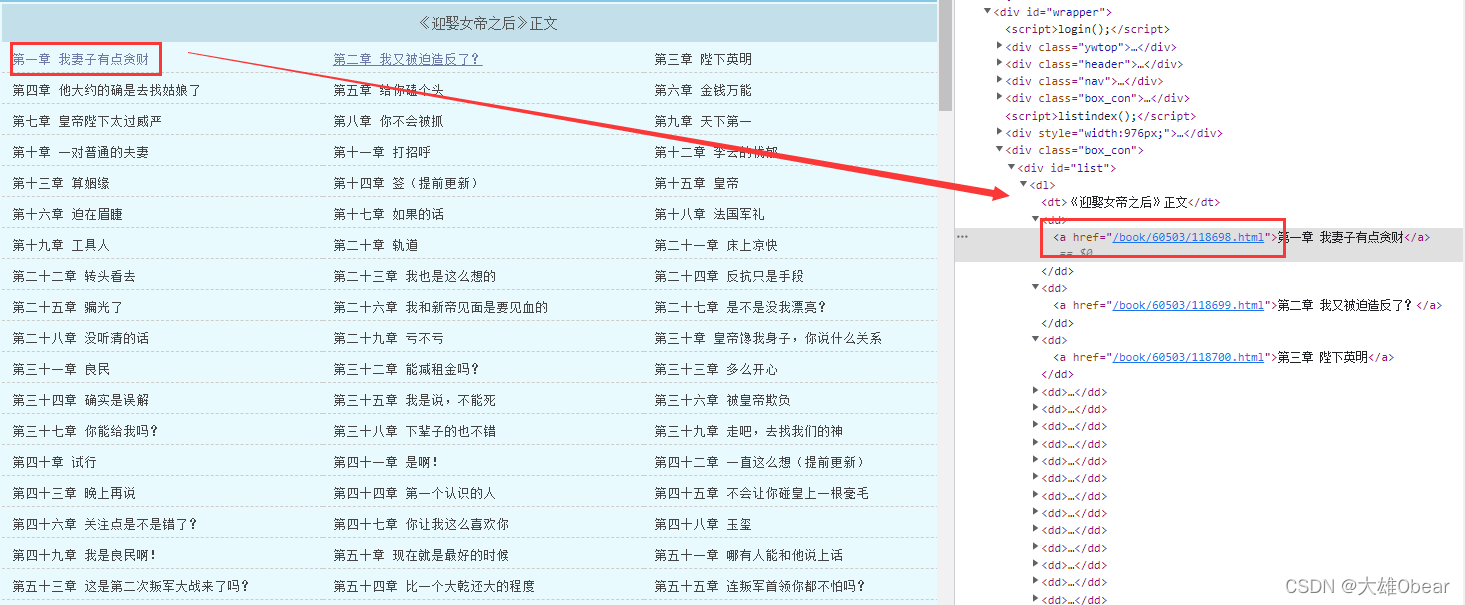
章节目录,通过一个 id 为 list 的 div 包裹,使用 dl > dd 制作列表
def get_urls():
url = bookurl
response = requests.get(url, headers=headers)
response.encoding = 'utf-8'
html = etree.HTML(response.text)
# 所有章节的url列表
url_list = [weburl + x for x in html.xpath('//div[@id="list"]/dl/dd/a/@href')]
return url_list
以上代码,通过 etree 获取 HTML 内容,然后通过 xpath 查询 id 为 list 中每个章节的链接
获取小说内容

标题内容在 class 为 bookname 的div 下面的 H1 标签中。
小说内容在 id 为 content 的 div 中。
def get_text(url):
rep = requests.get(url, headers=headers)
rep.encoding = 'utf-8'
dom = etree.HTML(rep.text)
name = dom.xpath('//div[@class="bookname"]/h1/text()')[0]
text = dom.xpath('//div[@id="content"]/text()')
with open(path + bookname + '.txt', 'a', encoding='utf-8') as f:
f.write(name)
for con in text:
f.write(con)
print(f'{
name} ===> 下载完成')
使用 etree 和 xpath 获取小说内容,然后通过 for 循环写入文件。
完整代码
import requests
from lxml import etree
import time
import random
path = r"D:/Download/books/"
bookname = "迎娶女帝之后"
weburl = "https://www.81zw.com/"
bookurl = "https://www.81zw.com/book/60503/"
headers = {
"Referer": bookurl,
"User-Agent": "Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.1 (KHTML, like Gecko) Chrome/21.0.1180.89 Safari/537.1"
}
def get_urls():
url = bookurl
response = requests.get(url, headers=headers)
response.encoding = 'utf-8'
html = etree.HTML(response.text)
# 所有章节的url列表
url_list = [weburl + x for x in html.xpath('//div[@id="list"]/dl/dd/a/@href')]
return url_list
def get_text(url):
rep = requests.get(url, headers=headers)
rep.encoding = 'utf-8'
dom = etree.HTML(rep.text)
name = dom.xpath('//div[@class="bookname"]/h1/text()')[0]
text = dom.xpath('//div[@id="content"]/text()')
with open(path + bookname + '.txt', 'a', encoding='utf-8') as f:
f.write(name)
for con in text:
f.write(con)
print(f'{
name} ===> 下载完成')
def main():
urls = get_urls()
for url in urls:
get_text(url)
time.sleep(random.randint(1, 3))
if __name__ == '__main__':
main()
path :存放小说文件的路径
bookname:小说文件名称
weburl:小说网站域名
bookurl:小说URL
脚本保存为 .py 后缀的文件,可双击直接运行,也可以在命令窗口或者 idea 中运行。
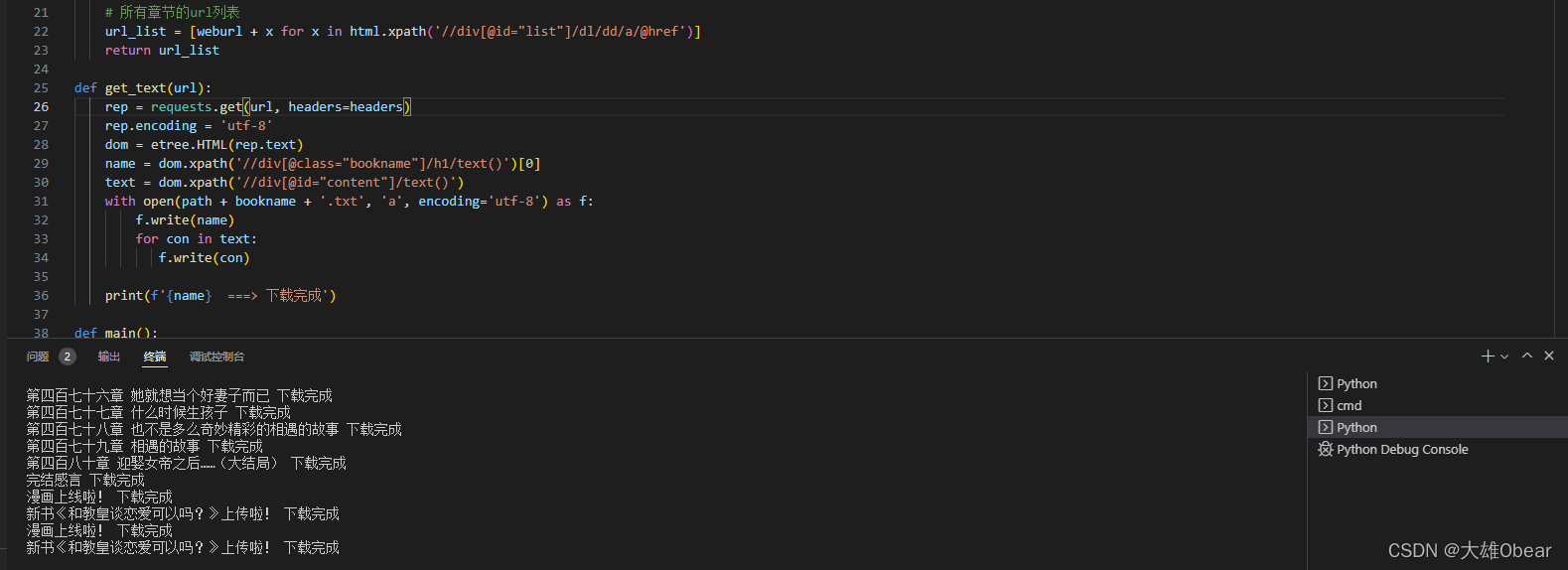
出现上图输出内容,说明脚本是有效果的。