1.为什么需要残差神经网络?
现在,目前有个通识就是,只要神经网络的层次足够,那么实际是可以表示任何事物的,但是在通常的情况下,深层次的网络会遇到一个很令人厌烦的问题:梯度消失,即当神经网络足够深的情况下,那么它的梯度值最终会趋向于0。那么怎么解决这个问题呢?比如之前我们可以使用BN或者更换激活函数为Relu,但是这样会导致深层次的网络的误差变大,如原文中作者给出的图:

通过在一个浅层网络基础上叠加y=x的层(称identity mappings,恒等映射),可以让网络随深度增加而不退化。这反映了多层非线性网络无法逼近恒等映射网络。
但是,不退化不是我们的目的,我们希望有更好性能的网络。 resnet学习的是残差函数
F(x) = H(x) - x
这里如果F(x) = 0, 那么就是上面提到的恒等映射。事实上,resnet是“shortcut connections”的在connections是在恒等映射下的特殊情况,它没有引入额外的参数和计算复杂度。 假如优化目标函数是逼近一个恒等映射, 而不是0映射, 那么学习找到对恒等映射的扰动会比重新学习一个映射函数要容易。从下图可以看出,残差函数一般会有较小的响应波动,表明恒等映射是一个合理的预处理。

2.残差块(Residual block)
在介绍残差网络之前,还需要介绍一下残差块(残差块是残差神经网络的基础),下面给出残差块的结构:

仔细一看,这不就是多了一条线么,就是将x连接到+这个位置的一条线,这条线我们可以称为skip connection,那么具体是怎么工作的呢?

通过下面的残差块的展开结构,我们更加容易发现与常规的网络连接的不同的部分,那么就以下面的内容讲解残差块:首先是 作为输入,先是经过下面的线性变换
然后使用Relu激活函数进行非线性变换(这里的g代表是激活函数):
同样的,将 进行线性变换到下一层:
最后的不同点来了,这就是残差网络和普通网络的不同,不是简单的将 进行非线性激活,现在是最初提到的那根线的作用了,其采用的激活方式如下:
好了,通过公式,我们能有效的分析残差块与普通的前馈神经网络不同的部分啦,下面也给出一张在论文中残差网络的图,其实就是残差块的叠加:

对残差网络有了直观的印象,那么你应该会思考一下:为什么残差网络会有效呢?下面的内容就是解决这个问题的,please go to next part
3.残差网络为什么有效?
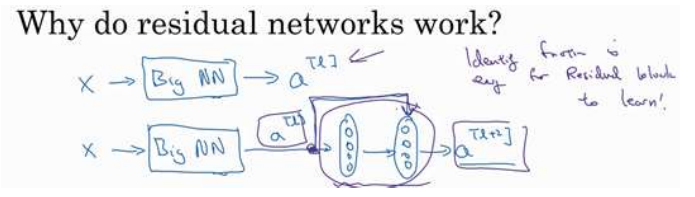
这个部分主要是介绍残差网络为什么有效。查看上面第一行的图片,我们想要再加两层,那么可以加一个残差块如下面第二行所示,我想你好记得上面的公式推导,这里,我们将这个推导内容展开,
当我们使用L2正则化或者权重衰减,它会压缩
的值,如果对b应用权重衰减也可以达到同样的效果,假设对W和b都进行权重衰减,为了方便起见,令其值均为0,那么公式即可简化如下:
注意:这里的激活函数假设为Relu,于是采用
那么我们最后观察,得到的等式不就是
很神奇吧,加了两层神经网络,确是学到了一个恒等式,只是需要一跟线(skip connection),这样不论是将残差块添加到神经网络的中间还是末端位置,都不会影响神经网络的表现。那么我们为啥要使用残差神经网络呢?主要是想提升网络的效率,如果这些隐藏单元学习到一些有用的信息,那么它可能比学习恒等函数表现的更好。这就是为什么要使用残差神经网络的原因。
4.Reference
https://arxiv.org/pdf/1512.03385.pdf
https://blog.csdn.net/mao_feng/article/details/52734438
https://www.jiqizhixin.com/articles/042201?from=synced&keyword=resnet