Faster R-CNN原理详解
(一)前言:
2014年R-CNN结构的提出,首次将卷积神经网络带入目标检测领域。2015年发表的Fast R-CNN,流程更为紧凑,大幅提高目标检测速度。

但是Fast R-CNN在区域建议(即候选框的提取)上耗费了大量时间。
为了解决这个问题,作者提出了Faster R-CNN网络,其中最主要的贡献就是使用了RPN(Region Proposal Networks,区域生成网络)和ROI Pooling(Region of Interest)层,使检测的综合性能有了大幅提升。
(二)网络结构:
2.1 整体结构解析

整体结构如图所示,具体过程为:
- 通过conv layers(通常采用VGG)在原图上提取特征图feature maps;
- 通过Region Proposal Network(RPN层)生成不同大小的anchors,并提取anchors中的目标候选框(即prior box);
- 将这些目标候选框映射回feature maps的区域,这些区域称之为ROI(Region of Interest, 感兴趣区域);
- 通过classifier(分类器)对ROI进行分类和坐标框预测;
数据流为:
- conv layers传入图像,生成Feature maps;
- 通过RPN层,输出每个点对应不同大小候选框(anchors)的背景判别得分和初步的坐标框预测值;
- 将正样本映射回feature maps上的区域并截取出来;
- 对截取出来的不同区域(大小可能不同)进行ROI Pooling,使其获得固定尺寸输出;
- 最后通过classifier对ROI Poolling的结果进行类别判断和坐标框预测;
看到这里可能还是有些懵圈,但是不要担心,这里只是大体讲一下网络的结果,结构单元和细节处理过程会在下面详细讲。
2.2 Conv Layers:获取feature map

我们以VGG-16作为Conv Layers为例,简单地写一下:
# vgg-16
def vgg16(inputs):
net = conv2d(inputs, filters=64)
net = conv2d(net, filters=64)
net = max_pool2d(net, k=2, strides=2)
net = conv2d(net, filters=128)
net = conv2d(net, filters=128)
net = max_pool2d(net, k=2, strides=2)
net = conv2d(net, filters=256)
net = conv2d(net, filters=256)
net = conv2d(net, filters=256)
net = max_pool2d(net, k=2, strides=2)
net = conv2d(net, filters=512)
net = conv2d(net, filters=512)
net = conv2d(net, filters=512)
net = max_pool2d(net, k=2, strides=2)
net = conv2d(net, filters=512)
net = conv2d(net, filters=512)
net = conv2d(net, filters=512)
return net
假设输入图片为300×300大小,经过卷积层和总共4个步长为2的max pooling,我们就得到了一个19×19×512大小的feature map(就是图中黑乎乎的那个)。
2.3 RPN层:获取正样本区域(Proposals)

2.3.1 anchors的生成:
anchors 指的是在原图上生成的所有候选框。由于一张图中需要检测到的目标可能大小不同、位置不同,所以我们需要位置、大小和长宽比各不相同的anchors 在原图上选出候选区域,再判断这些候选区域是否为物体,以及与真值框(真实坐标)的偏移量。

在论文中,图(a)、图(b)描述的是之前的目标检测框架使用的对不同大小目标的检测方法:
要么使用图像金字塔(如图a),即将图像缩放成不同大小比例生成不同大小的feature maps来检测;
要么使用不同大小的多个卷积核(如图b),对同一个feature maps做多次检测;
但这些方法都大大增加了在提取候选框上的时间消耗。
而作者提出了,可以使用相同大小的卷积核而且不需要使用图像金字塔,在同一个feature map上,对不同大小的候选框(文章中称之为anchors)来同时进行预测。

这样如果我们输入的图像大小为M×N×3,经过conv layers获得的feature map大小为 (M/16)×(N/16)×512,其中feature map上的每个点都能在原图上映射为一个相应区域。

对每个特征点对应的映射区域,我们生成3种不同边长和对应3种不同长宽比,3×3共9个anchors(候选框);边长分别为【128, 256, 512】,长宽比分别为【1:1,1:2,2:1】,如图所示):



这样我们就通过每个特征点对相应区域生成大小不同、长宽比也各不相同的候选框(anchors),对每个M×N大小的图片生成共(M/16)×(N/16)×9个anchors,实现了对候选区域的初步选取。
2.3.2 正负样本的判别:
先讲一下IOU的概念,IOU是描述两个区域重叠程度的一个量,计算方式如图:

在训练过程中,我们需要分别计算这些anchors与传入的真值框的IOU值,将其中IOU值大于某一阙值(论文中取0.8)的anchors标记为正样本,称之为prior boxes(先验框),如图(绿色为真值框,红色为正样本):


这一步就是将与真值框重叠程度较高的anchors筛选出来,用于进一步判别其表示对物体类别并预测与真值框的偏移。
我们这时可以看到,由于我们选取的anchors都是固定大小和固定位置,即使初步筛选出来的正样本,也依然与真值框有一定的偏差,因此我们就将这个偏差量化表示,作为预测的回归值,这步操作称为bounding box regression:

式中,t代表target,即回归值;
训练模型时,我们由于输入了真值框(ground-truth box),就能够计算预测回归的目标值:
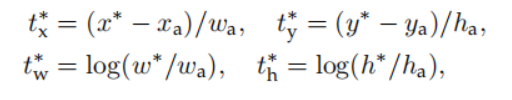
X*,Y*,W*,H*分别是真值框的中心坐标及其宽高;
Xa,Ya,Wa,Ha则分别是anchors的中心坐标及其宽高;
这样的话得出来的 t* 的4个值,就分别是anchor对应应该回归的中心坐标偏移量和宽高的偏移大小。
进行预测时,没有真值框的输入,我们则通过卷积层预测 t 的4个值(在训练过程中 t 不断地向 t* 回归),再通过公式:
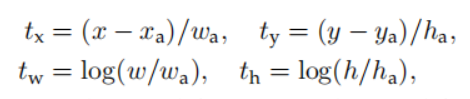
将X,Y,W,H反解出来,就得到了最终的目标框的预测坐标。
2.3.4 简单的代码实现:

def RPN_net(feature_map):
rpn_feature = conv2d(feature_map, k_size=3, filters=256) # 256-d
num_anchors = 3*3
scores = conv2d(rpn_feature, 2*num_anchor,
k_size=1, activation=None)
coordinates = conv2d(rpn_feature, 4*num_anchor,
k_size=1, activation=None)
return scores, coordinates
其中:
- 使用了1×1大小的卷积层代替全连接层,以适应不同大小的图片输入(注意原图上的sliding window(即卷积核)大小为3×3,应该是为了让读者看得更清除一些,但实际上卷积核采用的还是1×1大小);
- scores是每个特征点的每个anchors的背景or物体的判别得分;其中每个特征点的输出大小为2*9,2代表这是一个二分类(背景or物体),9代表每个特征点对应9个anchors;
- coordinates 即每个特征点的每个anchors的坐标偏移量预测(即公式中的tx,ty,tw,th);
2.3.3 训练过程中正负样本的筛选:
我们可以计算出,每张图片我们会生成(M/16)×(N/16)×9个anchors,即对一张600×600大小的图片,总共会生成38×38×9接近一万三千个anchors,其中大部分的anchors都是负样本,而如图只有少数anchors能够标记为正样本:

这样的话如果对所有anchors都进行梯度下降,那么我们最后反向传播得到的梯度中正样本的影响就会微乎其微,导致模型难以收敛;不仅如此,对如此大量的数据进行处理,也大大拖延了训练模型的时间。
作者为了解决以上问题,提出了解决办法:

即训练时,每张图片只随机取256个anchors参与Loss的计算,其中正负样本的比例控制为1:1,即128个正样本和128个负样本;如果一张图片的正样本不足128个,那就用负样本进行填充;这样筛选出来的样本区域,就称之为Proposals。
其余样本不参与Loss计算,其Loss置零。
2.4 ROI Pooling层:约束映射区域大小
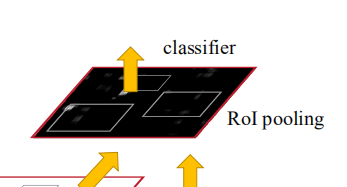
2.4.1 传统检测中的问题:
对于传统的CNN,当网络训练好后输入的图像尺寸必须是固定值,同时网络输出也是固定大小的向量或者矩阵。如果输入图像大小不定,这个问题就变得比较麻烦。有2种解决办法:

一是通过crop的方法,即只裁剪图片的一部分;
二是通过warp的方法,将图片缩放到指定大小;
但这两种方式都会破坏图片的结构信息。
作者则提出了可以使用ROI Pooling,既能够获得固定大小区域也能保留这一图片区域的结构信息。
2.4.2 ROI Pooling原理:
这里参考了Elag大佬的ROI Pooling讲解https://blog.csdn.net/u011436429/article/details/80279536
(1)我们以一个8×8大小的feature map为例,调整ROI Pooling的输出大小参数为2×2(原文中为7×7):

(2)假设一个Proposals在feature map上的映射区域为:
(左上角,右下角坐标):(0,3),(7,8),如图

(3)我们将其划分为(2×2)个sections(因为输出大小为2×2):

(4)然后对每个区域分别进行max pooling,就得到了固定大小的输出:

如果放到原文中,过程为:
- 通过RPN网络,提取出了256个Proposals(包含正、负样本);
- 在feature map(大小为(M/16)×(N/16)×512)上映射为256个区域;
- 最后通过ROI Pooling,得到大小为256×7×7×512的输出;
2.5 Classifier:预测物体类别和预测框偏移量
Classifier 的作用是对ROI Pooling 输出的256×7×7×512矩阵对应的Proposals,进行物体类别的预测;并且由于第一次对正样本anchors进行坐标框偏移量预测生成Proposals时并不精准,这里需要对Proposals再次进行bounding box regress。
2.5.1 Classifier的结构:

2.5.2 Classifier的代码实现:
def classifier(roi_pooling, is_training=True):
pool5_flat = tf.layers.flatten(roi_pooling) # (256, 7*7*512)
fc6 = tf.layers.dense(pool5_flat, 4096)
if is_training:
fc6 = tf.layers.dropout(fc6, rate=0.5)
fc7 = tf.layers.dense(fc6, 4096)
if is_training:
fc7 = tf.layers.dropout(fc6, rate=0.5)
cls_scores = tf.layers.dense(fc7, num_classes,
activation=None) # (256, num_classes)
reg_pred = tf.layers.dense(fc7, 4,
activation=None) # (256, 4)
return cls_scores, reg_pred
这样就得到了对应256个Proposals的物体类别向量(cls_scores)和偏移值预测(reg_pred,公式中的t*的四个值)。
(三)实验结果:


如果觉得对您有帮助的话,记得点赞关注哦
我们下期再见~

