文章目录
为什么要用CNN来处理图片
卷积神经网络近年来在计算机视觉中大放异彩,是什么特点让卷积神经网络在图像处理方面大火呢?
首先我们来看一张图片:
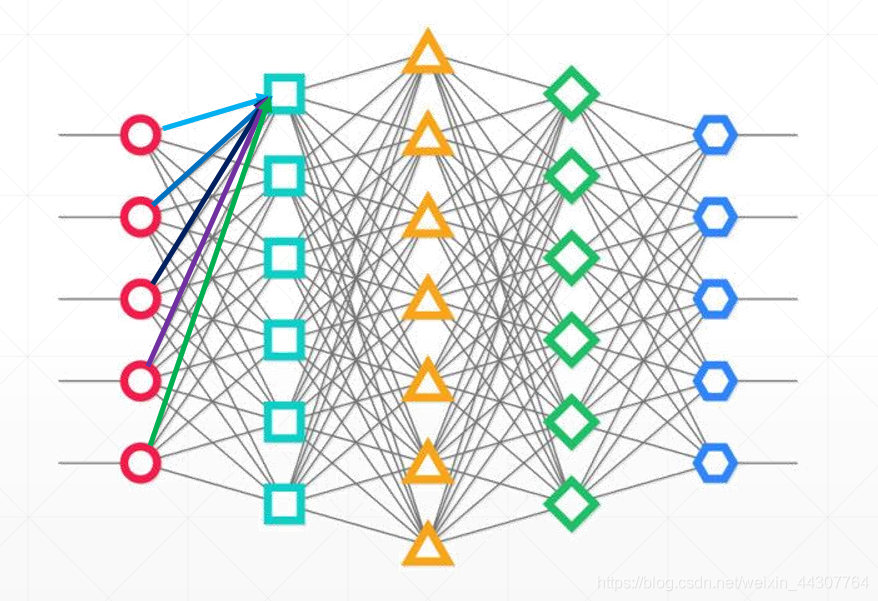
这是一张普通的表示全连接神经网络的结构图。大家可以看到全连接神经网络中,每一个节点都与前一层所有的节点想连接。鉴于图像数据和其他数据的区别,我们做个简单的计算即可发现全连接神经网络处理图像的弊端。
比如一个像素很低3232的图片数据,那么它的输入既有1024个节点,那么神经网络的第二层的第一个节点则需要1024个权重w来和前一层进行连接,同理第二层的第二个节点也需要1024个权重w和第一层所有节点连接…… 并且此处第一层的权重和第二层的权重之间是不同的,是没有联系的。所以可想而知,这个神经网络的数据量和计算量将是十分庞大的。并且大家都知道,现在随着对图片清晰度要求的逐步提高,图片早已不可能是3232像素的图片了,那对全连接层处理图片来说将是灾难。
卷积神经网络的不同之处在下图可以直观感受到:
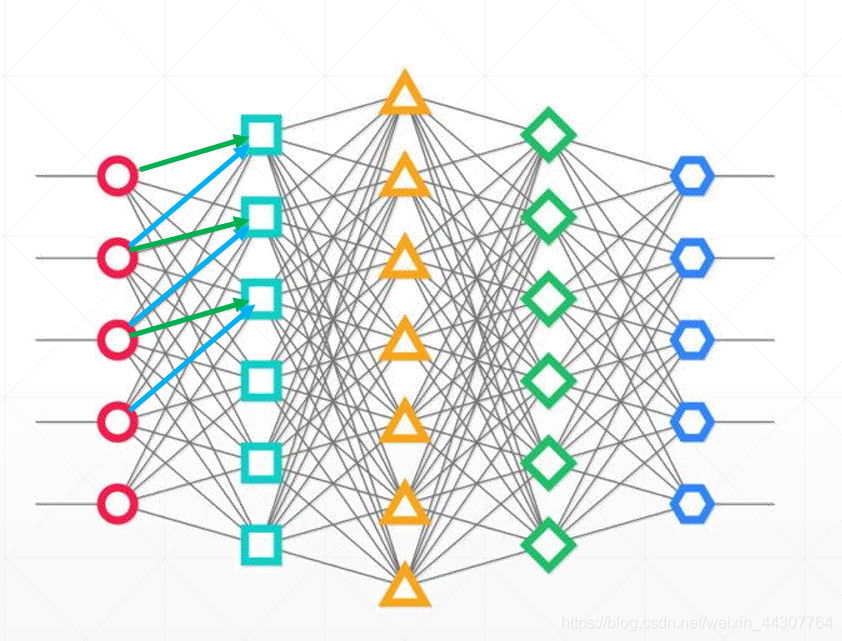
卷积神经网络的优点既体现在此处,如果将全连接神经每个节点的处理比作一次扫描的话。那么全连接层是一次扫描全部节点,且每个节点的观察方式还不一样,卷积层则是一次扫描邻近的部分节点,节点之间的观察方式是一样的。
这里我强调了“邻近的”这三个字,是因为对于图像数据其实还有一个特点,就是相邻的像素点之间的关系比较大,距离较远的像素点之间的关系可能就比较小,所有研究这相邻的像素点之间的关系的意义其实更大。
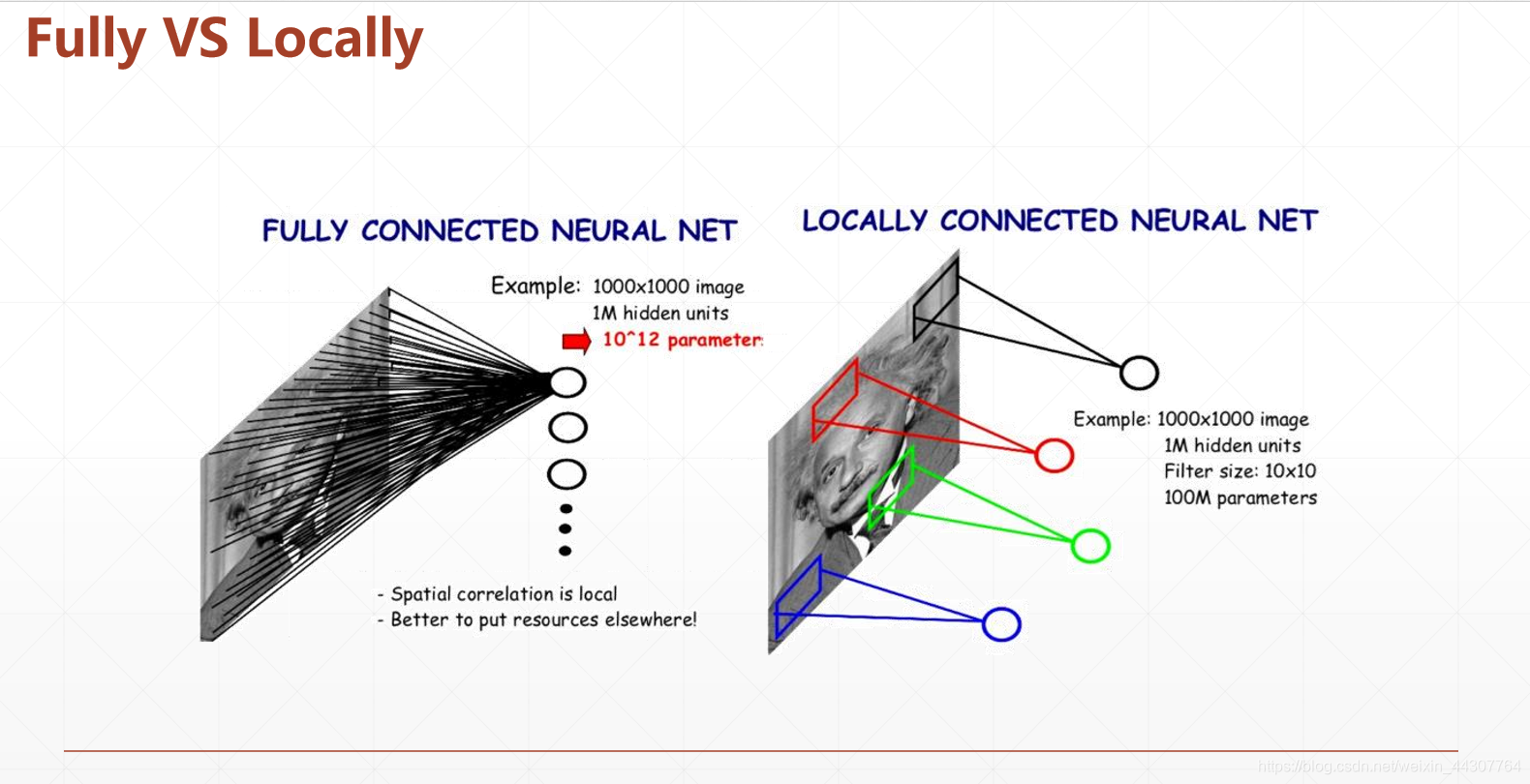
下面这张图片很形象的表达的卷积神经网络的优势:
卷积操作简述
其实最早卷积操作出现在在计算机视觉(CV)当中。那是为了得到不同效果的图片设计了不同的卷积操作,
比如为了得到锐化后的图片

为了得到模糊化的图片

为了得到边缘化的图片:
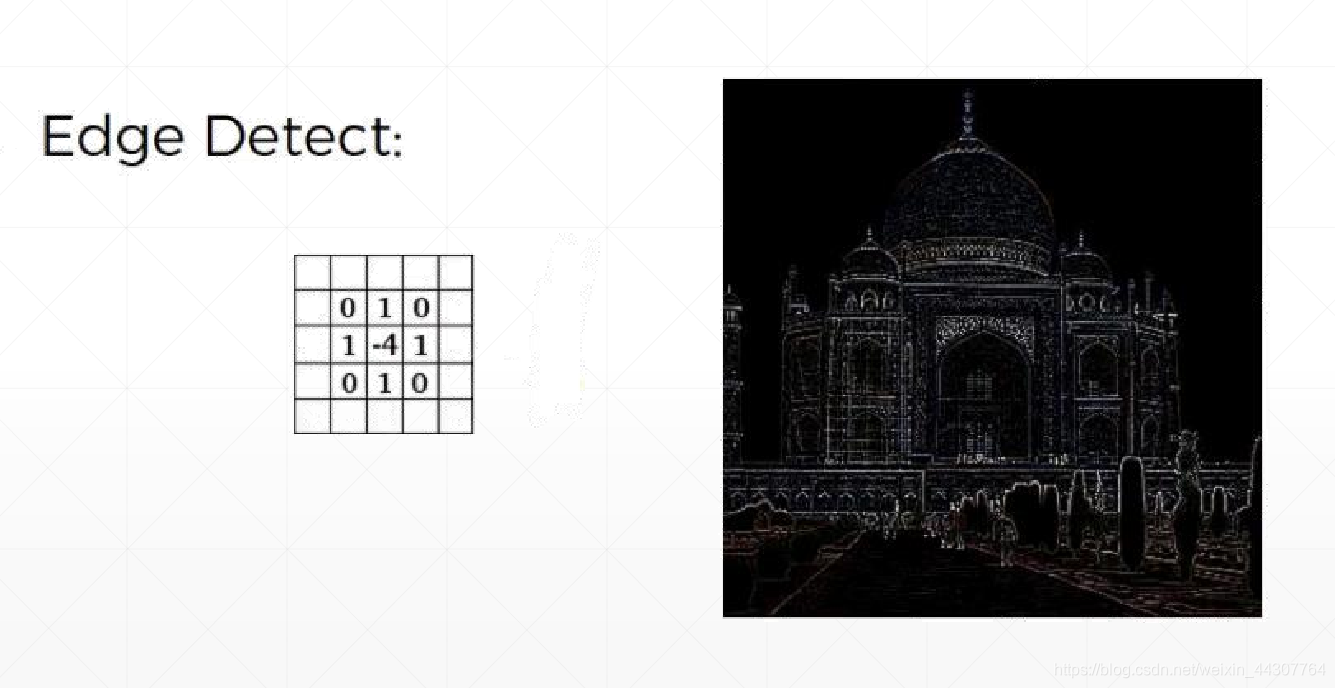
在此处的应用中,卷积核中的权重是一开始就已经固定好了,并且有着属于自己的特殊含义,因为不同卷积核得到了不同的结果。而在卷积神经网络中,我们的目的就是为了经过不断训练得到卷积核中的权重w,训练的过程是基于SGD(Stochastic Gradient Descent,随机梯度下降)得到的,并且权重w也没有特定的目的。
而是为了不断提取特征,卷积核就相当于与一种观察方式。比如从底层像素级的概念,逐步到模块级别的概念等
low level Feature–> Mid level Feature–>High Level Feature
相乘再累加?
我们都知道卷积操作并不神秘,就是卷积核中的对应元素与图片上的对应元素进行相乘再累加,那为什么要相乘再累加呢,这里就要说到信号学上面的一个概念,信号学上将两个函数之间的操作定义为卷积。下面的公式就定义一个卷积操作,
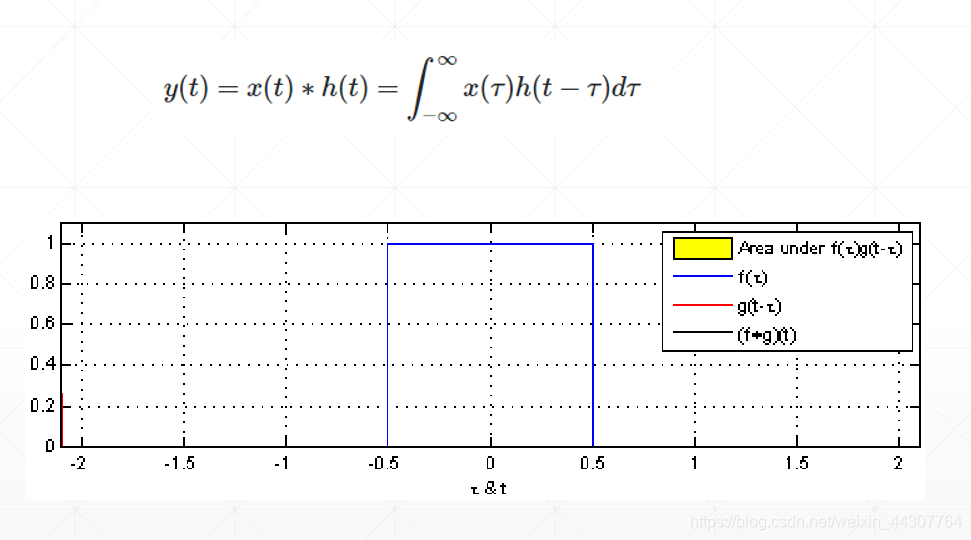
在连续的函数里面,卷积体现在函数的积分上,例如这个公式中对τ积分。这一点在离散上就体现为相乘再累加,同时对于这个公式来说,t不一样,积分得到结果不一样,改变t就相当于在卷积中移动卷积核重新相乘再累加。
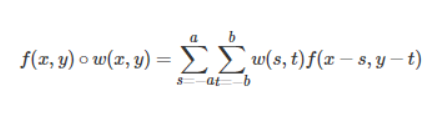
信号学中关于卷积的介绍和推导远不止这么简单,这只是我目前粗浅的理解。
卷积层中重要的操作与概念
在实现卷积中,有一些我们不得不了解操作和概念,当我们了解了这些之后,才能更好的去实战。
两个重要操作 Padding & Stride
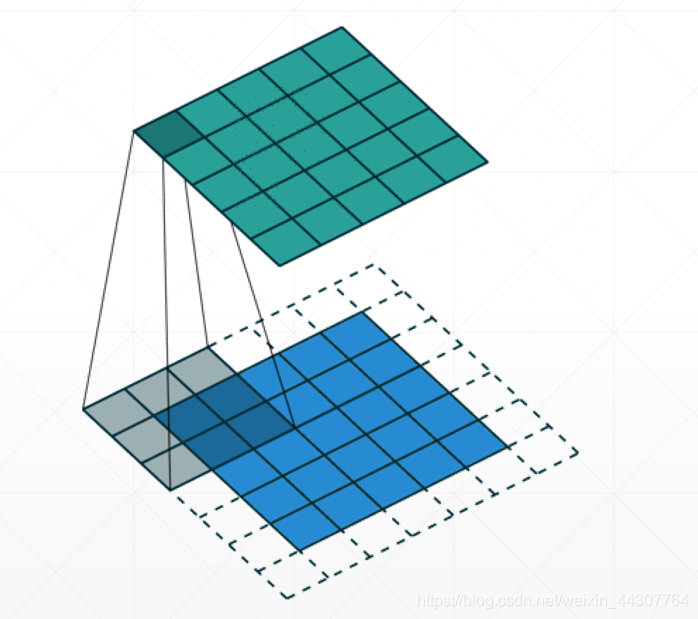
经过卷积层的处理之后得到的输出的shape要比输入的shape要小一点,为了使输入和输出保持一致,,就需要Padding操作。从图中也可以看出,所谓的padding就是将输入的shape变大一点。
而Stride操作代表了卷积核移动的步长,比如stride = 1就代表一次移动一格。
通过合理的调节Padding 和 stride 就可以使得输出的shape满足自己的需求。
两个重要概念 池化 & 采样
图片在经过卷积层的处理得到特征图(feature map)之后,为了进一步得到图像的高阶特征,这时候就会用到池化层。
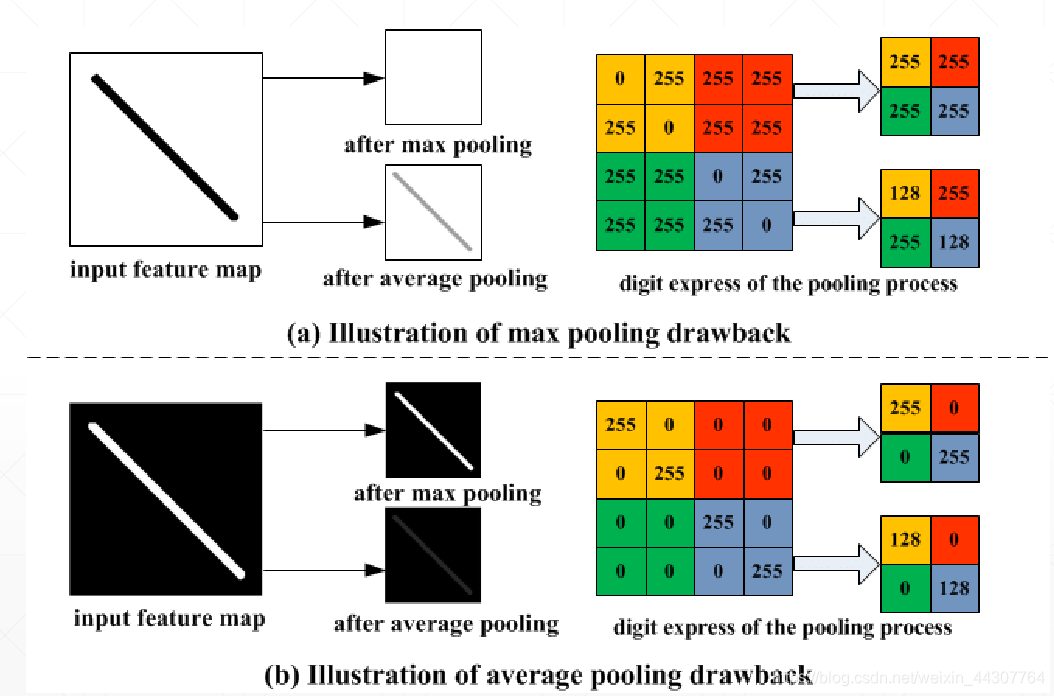
平均池化:倾向于保留突出背景特征
最大池化:倾向于保留突出纹理特征
池化层所用到的技术就是采样。采样我的简单理解就是对一个feature map放大或者缩小,放大就叫做上采样,缩小就叫做下采样。在这个过程中采取的方式不同,所着重保留的图像的特征也不同。
下图可以很直观的感受两种下采样的区别:
理解这个过程的Gradient
作为Deep Learning中最核心的部分梯度下降Gradient理解是十分重要的。
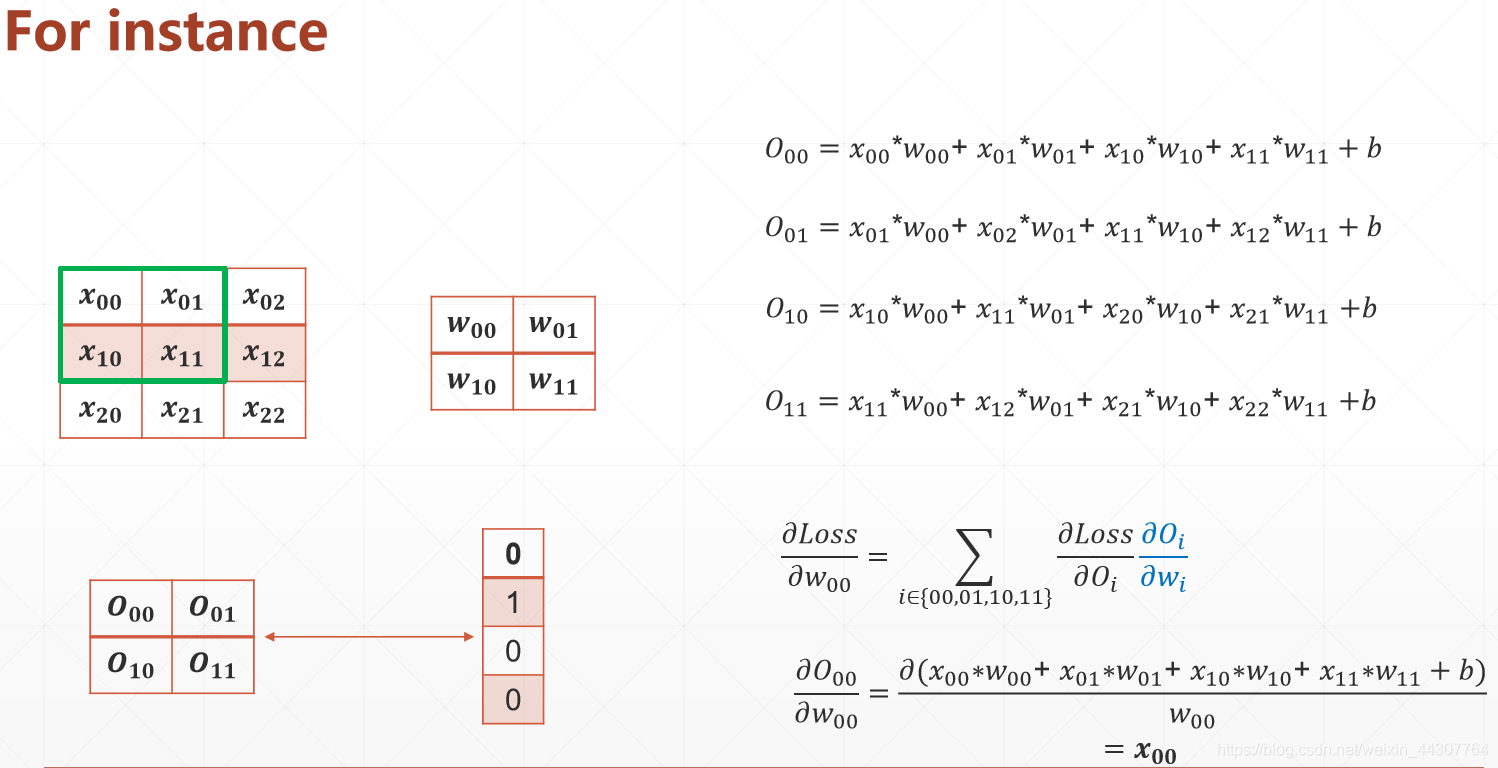
上面的公式就反映了卷积过程的梯度问题是可以解决的,我们理解这个过程就行,tensorflow提供了封装好的梯度下降的工具,我们直接用就行。
CNN实战
上面介绍了这么多,终于要开始实战了。
在写代码之前,有必要有一个意识,就是对如何搭建网络要有一个大致的了解,换句话说也就是网络的结构应该是怎样的,大致可以分为四步:
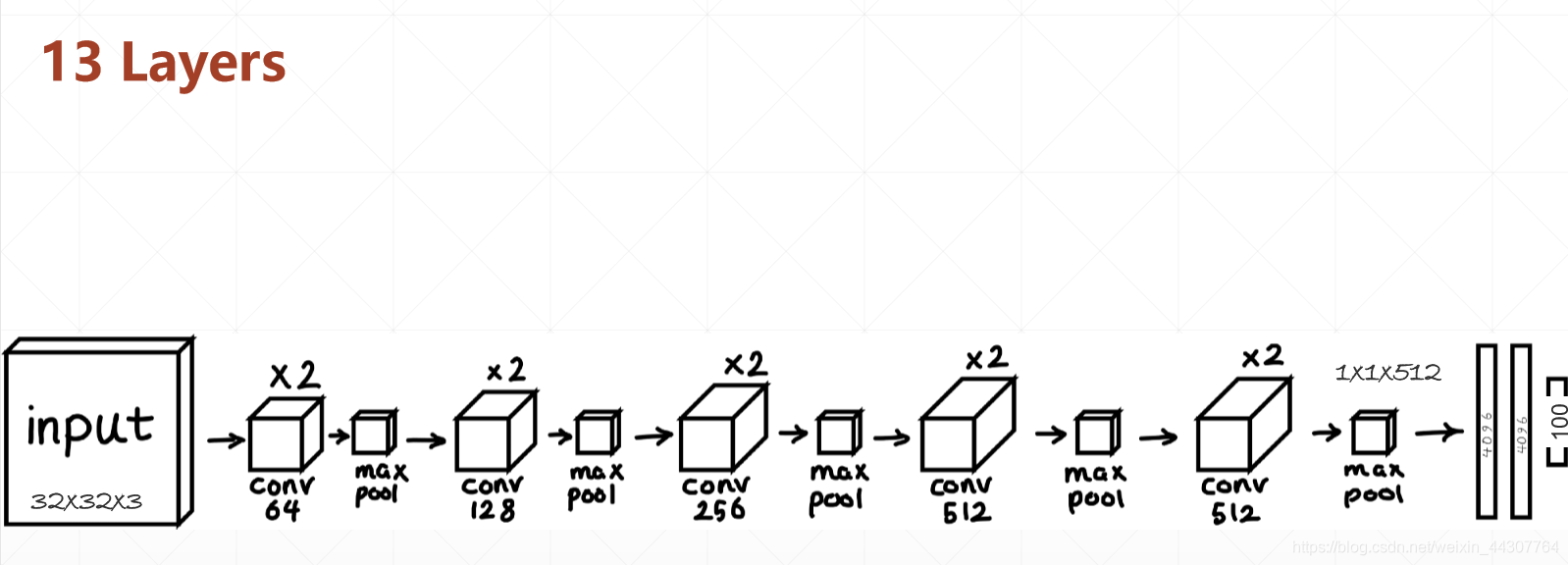
接下来用CIFAR100数据集来实战CNN,首先我们则必须了解一下这个数据集。
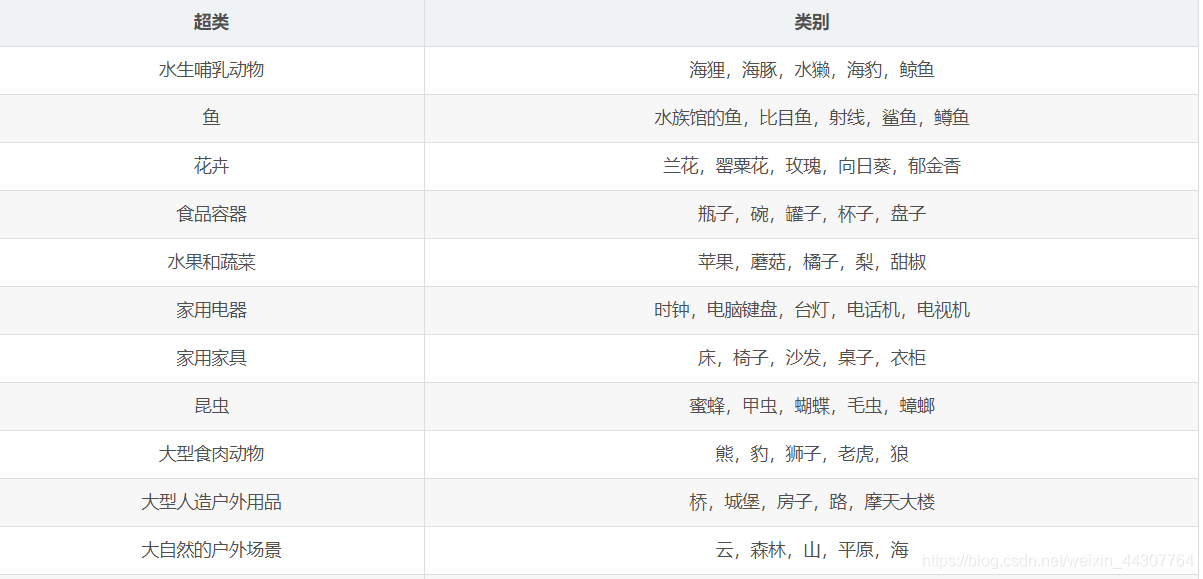
CIFAR数据集由60000个32x32彩色图像组成,共有100个类,每个类包含600个图像。每类各有500个训练图像和100个测试图像。CIFAR-100中的100个类被分成20个超类。每个图像都带有一个“精细”标签(它所属的类)和一个“粗糙”标签(它所属的超类)
下面是截取的一部分类别列表
我们继续照着之前 准备数据–>搭建网络–>训练网络–>测试网络 四步来编写代码
import tensorflow as tf
from tensorflow.keras import layers, optimizers, datasets, Sequential
import os
# 不输出通知信息和警告信息
os.environ['TF_CPP_MIN_LOG_LEVEL'] = '2'
tf.random.set_seed(2345)
# 改变数据的格式
def preprocess(x, y):
# [0~1]
x = tf.cast(x, dtype=tf.float32) / 255.
y = tf.cast(y, dtype=tf.int32)
return x, y
# 第一步:准备数据
(x,y), (x_test, y_test) = datasets.cifar100.load_data()
# 得到的y 和 y_test 的维度为( ,1) ( ,1) tf.squeeze 变换维度
y = tf.squeeze(y, axis=1)
y_test = tf.squeeze(y_test, axis=1)
print(x.shape, y.shape, x_test.shape, y_test.shape)
train_db = tf.data.Dataset.from_tensor_slices((x, y))
train_db = train_db.shuffle(1000).map(preprocess).batch(128)
test_db = tf.data.Dataset.from_tensor_slices((x_test, y_test))
test_db = test_db.map(preprocess).batch(64)
sample = next(iter(train_db))
print('sample:', sample[0].shape, sample[1].shape,
tf.reduce_min(sample[0]), tf.reduce_max(sample[0]))
#第二步:搭建网络的结构
conv_layers = [# 5 units of conv + max pooling
# unit 1
layers.Conv2D(64, kernel_size=[3, 3], padding="same", activation=tf.nn.relu),
# 卷积核的个数 卷积核的大小 激活函数
layers.Conv2D(64, kernel_size=[3, 3], padding="same", activation=tf.nn.relu),
# 前面两层
layers.MaxPool2D(pool_size=[2, 2], strides=2, padding='same'),
#
# unit 2
layers.Conv2D(128, kernel_size=[3, 3], padding="same", activation=tf.nn.relu),
layers.Conv2D(128, kernel_size=[3, 3], padding="same", activation=tf.nn.relu),
layers.MaxPool2D(pool_size=[2, 2], strides=2, padding='same'),
# unit 3
layers.Conv2D(256, kernel_size=[3, 3], padding="same", activation=tf.nn.relu),
layers.Conv2D(256, kernel_size=[3, 3], padding="same", activation=tf.nn.relu),
layers.MaxPool2D(pool_size=[2, 2], strides=2, padding='same'),
# unit 4
layers.Conv2D(512, kernel_size=[3, 3], padding="same", activation=tf.nn.relu),
layers.Conv2D(512, kernel_size=[3, 3], padding="same", activation=tf.nn.relu),
layers.MaxPool2D(pool_size=[2, 2], strides=2, padding='same'),
# unit 5
layers.Conv2D(512, kernel_size=[3, 3], padding="same", activation=tf.nn.relu),
layers.Conv2D(512, kernel_size=[3, 3], padding="same", activation=tf.nn.relu),
layers.MaxPool2D(pool_size=[2, 2], strides=2, padding='same')
]
def main():
# 整个网络分为两个部分,卷积层和全连接层
# 卷积层, 效果:[b, 32, 32, 3] => [b, 1, 1, 512]
conv_net = Sequential(conv_layers)
#全连接层的网络搭建, 效果:[b, 512] => [100]
fc_net = Sequential([
layers.Dense(256, activation=tf.nn.relu),
layers.Dense(128, activation=tf.nn.relu),
layers.Dense(100, activation=None),
])
conv_net.build(input_shape=[None, 32, 32, 3])
fc_net.build(input_shape=[None, 512])
optimizer = optimizers.Adam(lr=1e-4)
# 第三步,训练网络
# [1, 2] + [3, 4] => [1, 2, 3, 4]
variables = conv_net.trainable_variables + fc_net.trainable_variables
for epoch in range(50):
for step, (x, y) in enumerate(train_db):
with tf.GradientTape() as tape:
# [b, 32, 32, 3] => [b, 1, 1, 512]
out = conv_net(x)
# flatten, => [b, 512]
out = tf.reshape(out, [-1, 512])
# [b, 512] => [b, 100]
logits = fc_net(out)
# [b] => [b, 100]
y_onehot = tf.one_hot(y, depth=100)
# compute loss
loss = tf.losses.categorical_crossentropy(y_onehot, logits, from_logits=True)
loss = tf.reduce_mean(loss)
grads = tape.gradient(loss, variables)
optimizer.apply_gradients(zip(grads, variables))
if step %100 == 0:
print(epoch, step, 'loss:', float(loss))
#第四步, 测试网络
total_num = 0
total_correct = 0
for x,y in test_db:
out = conv_net(x)
out = tf.reshape(out, [-1, 512])
logits = fc_net(out)
prob = tf.nn.softmax(logits, axis=1)
pred = tf.argmax(prob, axis=1)
pred = tf.cast(pred, dtype=tf.int32)
correct = tf.cast(tf.equal(pred, y), dtype=tf.int32)
correct = tf.reduce_sum(correct)
total_num += x.shape[0]
total_correct += int(correct)
acc = total_correct / total_num
print(epoch, 'acc:', acc)
if __name__ == '__main__':
main()
可参考下图来理解上面卷积神经网络的架构。