一文讲通谱域图神经网络:从图信号处理GSP到图卷积网络GCN
文章目录
图信号处理
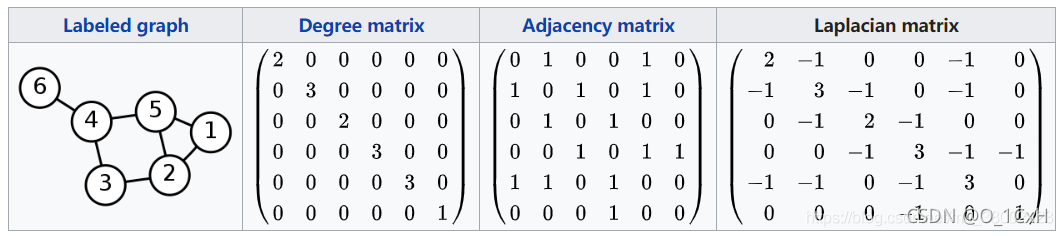
图G=<V,E>,包含两方面的信息:
一是节点集合 V={…,v_i,…}上带有的各节点信号强度向量x={…,x_i,…},其中x_i是v_i的信号强度;
二是图的结构信息,即点之间的相连关系,使用拉普拉斯矩阵来描述。
拉普拉斯矩阵
拉普拉斯矩阵定义为L=D-A,其中A是图的邻接矩阵,D=diag([…,deg(v_i),…])。
例子:
拉普拉斯矩阵的意义
图上的梯度在边上的分量:理解为边的属性,描述这条边连接的两个节点之间信号强度的变化速度,定义为(注意分量方向与边的方向一致):
g ⃗ i j = x j − x i e ⃗ i j \vec g_{ij} = \frac{x_j-x_i}{\vec e_{ij}} gij=eijxj−xi
图上的梯度:理解为点的属性,认为该点连接的边都是正交的,因此梯度也分开到各个维度,即
g ⃗ i = [ . . , g ⃗ i j , . . ] , ( i , j ) ∈ E \vec g_i = [.., \vec g_{ij} ,..], (i,j)\in E gi=[..,gij,..],(i,j)∈E
图上的散度:理解为点的属性,描述这个点处流入流出的向量之和,形式上为这些向量的直接加和;
图上的梯度的散度在点上的分量:理解为点的属性,将该点处的梯度分量相加,并以边的方向区分流入流出的向量,即
s i = ∑ j g ⃗ i j = ( − 1 ) ∗ ∣ g ⃗ i p ∣ + 1 ∗ ∣ g ⃗ q i ∣ , { ( i , p ) , ( q , i ) } ⊂ E s_i = \sum_j \vec g_{ij} = (-1)*|\vec g_{ip}|+1*|\vec g_{qi}|, \{(i,p),(q,i)\}\subset E si=j∑gij=(−1)∗∣gip∣+1∗∣gqi∣,{
(i,p),(q,i)}⊂E

图上的梯度的散度:理解为图的属性,即图上所有点处的散度组成的向量,即
s i g n ( A ) × g ⃗ sign(\mathcal A)\times \vec g sign(A)×g
这个计算梯度的散度的过程(记为S*T)就是拉普拉斯矩阵的含义。所有矩阵都是一种空间变换,因此也被称作算子,拉普拉斯算子就是计算图上各点处的梯度的散度的算子。该算子本身与图的结构有关,作用对象是点的信号强度。
恰巧,S*T变换的结果与D-A刚好一致,而矩阵乘法比加减法更难计算,因此,直接使用D-A的形式。
总体来说,拉普拉斯矩阵将图这种非欧式空间结构转化到了欧氏空间。说人话就是将图转化成了矩阵,更方便处理。
注:实际上,因为边的方向同时改变梯度正负号和散度中计算流入流出的正负号,所以边的方向是任意指定的,换句话说,拉普拉斯矩阵只能描述无向图。
注2:拉普拉斯矩阵描述的是图的局部平滑程度
拉普拉斯矩阵的变形
对称正则化拉普拉斯矩阵:
L s y m = D − 1 / 2 L D 1 / 2 L_{sym} = D^{-1/2}LD^{1/2} Lsym=D−1/2LD1/2
随机游走正则化拉普拉斯矩阵:
L r w = D − 1 L L_{rw} = D^{-1}L Lrw=D−1L
重归一化拉普拉斯矩阵(在定义图神经网络时用到):
L ~ s y m = D ~ − 1 / 2 A ~ D ~ 1 / 2 , A ~ = A + I , D ~ i i = ∑ j A ~ i i \tilde L_{sym} = \tilde D^{-1/2} \tilde A \tilde D^{1/2}, \tilde A = A+I, \tilde D_{ii}=\sum_j \tilde A_{ii} L~sym=D~−1/2A~D~1/2,A~=A+I,D~ii=j∑A~ii
图傅里叶变换
将图信号从空域转换到频域。说人话就是找到该图的拉普拉斯矩阵的特征向量、特征值。
一个传统的傅里叶变换示意图如下:

关于矩阵特征向量、值
如果找到向量v和值λ,对于矩阵M满足:
M v ⃗ = λ v ⃗ \mathcal M \vec v = \lambda \vec v Mv=λv
那么向量v和值λ就是矩阵M的特征向量和特征值。
前面说到,一个矩阵代表一种空间变换,而在空间变换前后,特征向量的方向不改变,只是按照特征值进行了缩放;即对空间进行矩阵M对应的变换,变换前后原本空间内的向量v在新空间内方向不变,长度变为原来的λ倍(可以为0或负值)。
特征值的个数等于矩阵的秩,特征向量的个数至少等于矩阵的秩。
拉普拉斯矩阵的特征向量、值
拉普拉斯矩阵必然是一个满秩、对称、实数矩阵,因此:
一个节点数为n的图,对应秩为n的拉普拉斯矩阵;
对一个秩为n的拉普拉斯矩阵,必然有n对特征向量v1…vn和对应的特征值λ1…λn,这n对向量必然正交,因此可以用v1…vn作为基向量建立n维正交坐标系;
可以进行矩阵对角化,而且是正交对角化;
这n对特征向量(列向量形式)组成的矩阵V必然是正交矩阵,因此有V的逆等于V的转置。
根据以上结论,将拉普拉斯矩按照特征向量分解:

L算子可以按照全新的方式解读,即当L作用于信号x:
(1)首先将x变换到新的正交坐标系<v1, …, vn>中,各分量从…,x_i,…变为…,t_i,…
x ~ = V T x \tilde x = V^T x x~=VTx
(2)然后将每个坐标轴上的分量伸缩λ1…λn倍,即…,t_i,…变为…,λ_it_i,…
d i a g ( [ λ 1 , . . , λ n ] ) × x ~ diag([\lambda_1, .., \lambda_n]) \times \tilde x diag([λ1,..,λn])×x~
(3)再将…,λ_it_i,…从正交坐标系<v1, …, vn>变换回到原来的坐标系
x = V x ~ x = V \tilde x x=Vx~
图傅里叶变换
各种资料里用的术语,其实就是这些东西换壳:
图傅里叶基:上面说的特征向量v1,…,vn
图傅里叶系数:图信号x在基v1,…,vn上的投影
图傅里叶变换GFT:上面的步骤(1)
逆图傅里叶变换IGFT:上面的步骤(3)
频率:上面说的特征值λ1…λn可以理解为传统傅里叶变换里抽取出来的频率值,因为特征值越低对应的是图信号变化越慢,也就是图信号越平滑,相近节点的信号值趋于一致;反之如果特征值越高,则变化越剧烈。下图展示了不同频率值与图信号平滑程度的关系:
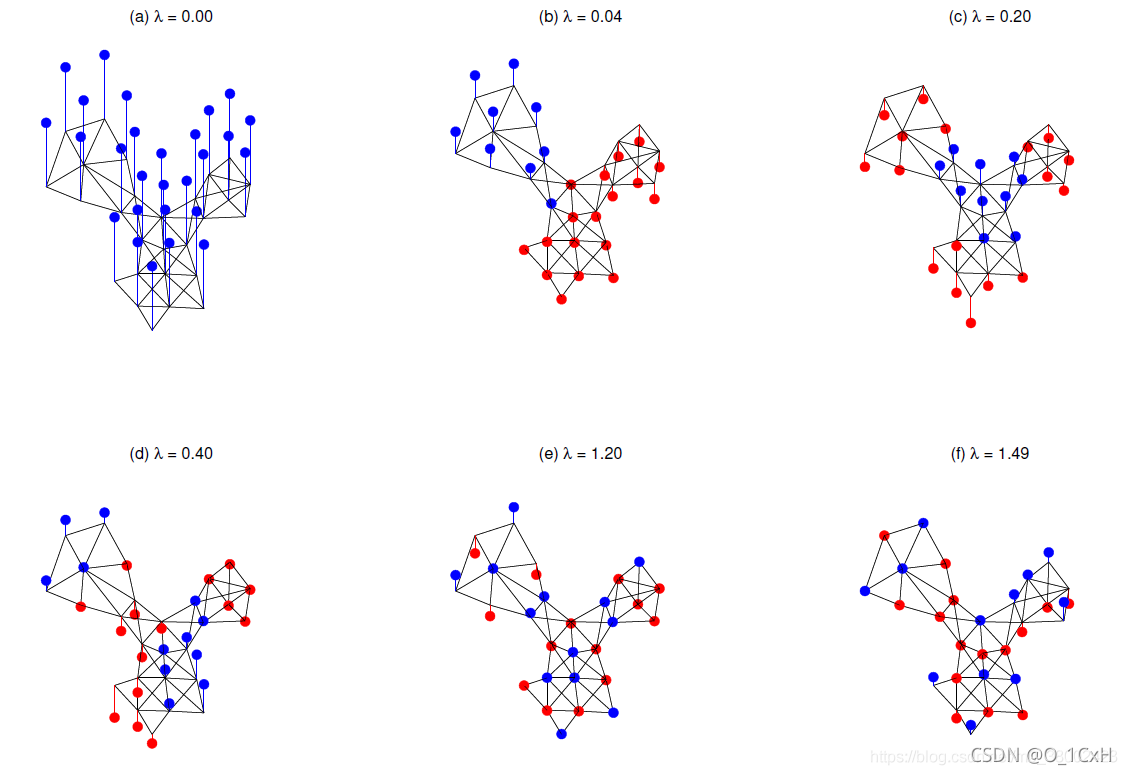
能量:有了频率这一定义,那么可以接着定义类似传统傅里叶变换里的能量,如果图信号在λ_i对应的v_i上的投影越大,说明图信号在频率λ_i上的幅值越大,即该频率分量上的能量强度。
图信号的频谱:一个图信号,经过上述转换,得到一系列频率(特征值)和频率上的能量(在对应特征向量上的分量),可以画出类似传统傅里叶变换的频谱出来,这个频谱描述了整个图信号在不同频率上的能量值。
图滤波器
类似于传统的滤波器,图滤波器对图信号频谱中的各频率分量进行增强或衰减。这一操作通过直接修改λ1…λn来实现,即滤波器算子H作用于图信号x上的结果Hx=

这一点就比较好理解了,直接修改λ1…λn值到h(λ1)…h(λn)实际上就是为每一个频率项添加一个系数,并且系数乘到能量上,让该频率的能量增强或减小。
向量diag([h(λ1),…,h(λn)])是是频率响应矩阵,函数h()被称为频率响应函数。
例如,想要仅保留(响应)低频信号,就把高频部分能量调小或归零(实际上大部分图都关注低频信号);想要仅保留(响应)高频信号,就把低频部分能量调小或归零。
注:图滤波器满足交换律:H1(H2(x)) = H2(H1(x))
任意频率响应
但是,理想情况是能够实现任意的滤波器,可以将信号的频谱整成任意函数,即h()能够实现任意函数,这就需要用到泰勒展开,即用L的多项式逼近任意函数H:

将其放到之前的对角化矩阵中来看,也就是:

原来的对角矩阵中的值从λ1…λn变成了对应的多项式:
d i a g ( [ λ 1 , . . , λ n ] ) ⇒ d i a g ( [ ∑ k h k λ 1 k , . . , ∑ k h k λ n k ] ) diag([\lambda_1, .., \lambda_n]) \Rightarrow diag([\sum_k h_k\lambda_1^k, .., \sum_k h_k\lambda_n^k]) diag([λ1,..,λn])⇒diag([k∑hkλ1k,..,k∑hkλnk])
即H算子作用于x上的时候,发生如下事情:
(1)首先将x变换到新的正交坐标系<v1, …, vn>中,即
x ~ = V T x \tilde x = V^T x x~=VTx
(2)然后将每个坐标轴上的分量伸缩多项式函数倍(滤波),即
y ~ = d i a g ( [ ∑ k h k λ 1 k , . . , ∑ k h k λ n k ] ) × x ~ \tilde y = diag([\sum_k h_k\lambda_1^k, .., \sum_k h_k\lambda_n^k]) \times \tilde x y~=diag([k∑hkλ1k,..,k∑hkλnk])×x~
(3)最后变换回到原来的坐标系,即
y = V y ~ y = V \tilde y y=Vy~
在空域上的含义
y=Hx在空域上可以看作是逐步迭代发生的:
y = H x = ∑ k h k L k x = ∑ k h k x ( k ) y = Hx = \sum_k h_k L^k x = \sum_k h_k x^{(k)} y=Hx=k∑hkLkx=k∑hkx(k)
x ( k ) = L x ( k − 1 ) x^{(k)}=Lx^{(k-1)} x(k)=Lx(k−1)
对于x(k),需要k阶(k-hop)邻居参与,而执行的操作就是聚合这些k阶邻居

例如上图中的例子,以该图自身的邻接矩阵作为滤波器,第一次迭代将v1本身的值修改为其邻居值的和,第二次迭代将v1的一阶邻居的值修改为其邻居值的和。
图卷积层
图卷积
在传统的傅里叶变换中,认为时域的卷积运算等于频域的乘法运算,那么在图里类似的有空域的卷积运算等于频域的乘法运算,即给定两个图信号x1、x2,其卷积计算为:
x 1 ∗ x 2 = I G F T ( G F T ( x 1 ) ⊙ G F T ( x 1 ) ) = V ( ( V T x 1 ) ⊙ ( V T x 2 ) ) x_1*x_2= IGFT(GFT(x_1) \odot GFT(x_1)) \\ =V((V^Tx_1) \odot (V^Tx_2)) x1∗x2=IGFT(GFT(x1)⊙GFT(x1))=V((VTx1)⊙(VTx2))
令
x ~ 1 = V T x 1 , H x ~ 1 = V × d i a g ( x ~ 1 ) × V T \tilde x_1 = V^Tx_1, H_{\tilde x_1}=V\times diag(\tilde x_1 )\times V^T x~1=VTx1,Hx~1=V×diag(x~1)×VT
则有:
x 1 ∗ x 2 = H x ~ 1 x 2 x_1*x_2 = H_{\tilde x_1}x_2 x1∗x2=Hx~1x2
也就是说,把图卷积运算转换成了图滤波运算。也就是说,任意两个图上的卷积运算可以由之前定义的滤波转化为图1对图2的滤波,这一点就与普通神经网络中的设计(卷积核对输入进行过滤)很类似了。
参数化、SCNN与ChebNet
单独来看图滤波器(对标卷积核),如果有一个任意频率响应的滤波器,那么理论上来说,其内置的泰勒展开多项式可以拟合任意函数,也就可以过滤得到任意想要的输出图,因此频率响应矩阵
d i a g ( [ ∑ k h k λ 1 k , . . , ∑ k h k λ n k ] ) diag([\sum_k h_k\lambda_1^k, .., \sum_k h_k\lambda_n^k]) diag([k∑hkλ1k,..,k∑hkλnk])
很显然可以作为学习对象来参数化(SCNN的做法),就像学习一个卷积核一样来学习一个图滤波器;但是这样做引入的参数太多,理论上一个n节点图(对应n秩拉普拉斯矩阵)就有n个参数需要学习,这显然是不合理的(代价高、容易过拟合),因此将需要学习的参数转化为h1…hk这k个系数(ChebNet的做法),即k阶泰勒展开的参数,k也可以理解为卷积核感受野大小,因为k是可以自由改变的,泰勒展开的阶数越大,那么拟合的滤波函数就越复杂。
形式化定义为:
X ′ = σ ( V d i a g ( Ψ θ ) V T X ) = σ ( V ( ∑ k θ k Λ k ) V T X ) X'=\sigma (V diag(\Psi \theta ) V^T X) = \sigma (V (\sum_k \theta_k \Lambda^k) V^T X) X′=σ(Vdiag(Ψθ)VTX)=σ(V(k∑θkΛk)VTX)
其中ψ为范德蒙矩阵,用于从参数θ中获得多项式系数。
Kipf的GCN layer
Kipf的论文中,提出限制k=1、每个h_i应当相等为参数θ=1,上式简化为
X ′ = σ ( θ ( I + L ) X ) X' = \sigma (\theta (I+L) X) X′=σ(θ(I+L)X)
限制k=1(一阶ChebNet)的好处在于,限制在一阶泰勒展开的话,就不需要进行耗时矩阵分解运算(O(N^3)->O(|E|d))。
由于限制了了标量参数θ相等且为1,需要补充一个W矩阵对X进行仿射变换(伸缩和平移);
另一方面,I+L作为一个整体,对应前面提到的重归一化形式的拉普拉斯矩阵,因此上式进一步转化为
X ′ = σ ( L ~ s y m X W ) X'=\sigma(\tilde L_{sym}XW) X′=σ(L~symXW)
这就是Kipf的图卷积层,GCN就是通过堆叠多个这样的1阶图卷积层来达到本来需要高阶泰勒展开才能达到的拟合效果。
空域模型与频域模型
频域图卷积模型:只能从频域进行矩阵特征分解然后执行图卷积计算。
空域图卷积模型:不需要矩阵特征分解,直接在空域进行计算。
显然Kipf的GCN层就属于后者。
图卷积网络GCN
GCN与CNN的联系
从节点视角看GCN层
GCN层计算式为
X ′ = σ ( L ~ s y m X W ) X'=\sigma(\tilde L_{sym}XW) X′=σ(L~symXW)
将矩阵乘法拆开,得到针对每一个输入信号对用的处理,
x i = σ ( ∑ j ∈ N ( i ) L ~ s y m [ i , j ] ( W x j ) ) x_i= \sigma(\sum_{j\in N(i)} \tilde L_{sym}[i,j](Wx_j)) xi=σ(j∈N(i)∑L~sym[i,j](Wxj))
即i的输出值等于i的所有邻居节点的输入值经过仿射变换和L算子加和后通过非线性函数。这种加和是一种对邻居节点的聚合操作。
由于GCN中K=1,因此聚合的只有1阶邻居节点,也就是该卷积核感受野为1。
从节点视角看GCN与CNN
本节讨论假设一般处理图像的CNN常用的卷积核K=3。
如果将图像的节点看作图,那么就是规则的图,每个节点都有八个邻居节点,因此在该图上运行GCN卷积和在原图像上运行CNN卷积是一样的;实际上的图并非规整的八邻域,因此GCN适用于更普遍的图结构。
局部连接:GCN与CNN的卷积都是聚合邻域信息的运算。GCN聚合其一阶邻居子图,而CNN聚合其中心3*3的栅格内。因此这是一种局部连接,即本层的输出特征只和输入特征的中心点的邻域信息相关。
权值共享:GCN和CNN都有“卷积核”的对等概念,因此都是权值共享的。
感受野:GCN每一层的感受野只有一阶邻居,CNN也只有中心3*3的部分,但随着层数的堆叠,二者的感受野都逐渐扩大。
区别:GCN的卷积核只有一个参数,而CNN有9个参数。CNN的拟合能力更强。
GCN的性质与问题
GCN与Weisfeiler-Lehman算法的相似性
Weisfeiler-Leman算法是检验图同构算法,其思想是:
- 给每个节点一个独特的初始标签,使用embedding得到
- 将每个节点的邻居节点的标签拼接起来,并进行hash
- 将hash值作为新标签,重复上一步
在这个过程中,两图应该保持hash值一致,否则不是同构。
GCN则可以理解为带参数、自动微分的Weisfeiler-Leman算法,并且
- 用单层感知机替换hash函数
- 用加权平均替换邻域信息拼接
低通滤波器
随着参数k的增加,在低频段上的缩放效果更强;另外,低频段的信号对学习任务实际上更有效。
有实验说明,如果高频信号加入信号重构,会导致分类效果下降。
过平滑、其他问题
拉普拉斯算子本身就是一种平滑算子,因为它聚合了近邻节点的特征。
如果堆叠了过多的GCN层,会导致学习效果急剧下降,其原因就是其低通滤波的本质:从谱域上来看,由于进行了低通滤波,信号变得更加平滑,在堆叠多层之后,信号不断平滑,逐渐趋同,极限情况下,仅剩一个频率为0的基上还有信号。
但如果堆叠的层数过少,又不够有效。
参考资料
《深入浅出图神经网络》
https://blog.csdn.net/m0_38002423/article/details/90758200
https://blog.csdn.net/sinat_41667427/article/details/106160643
https://www.kechuang.org/t/84022?page=0&highlight=859356
3Blue1Brown 线性代数 https://www.bilibili.com/video/BV1ys411472E
GCN原文:Thomas N. Kipf, Max Welling, Semi-Supervised Classification with Graph Convolutional Networks (ICLR 2017) (http://arxiv.org/abs/1609.02907)
https://archwalker.github.io/blog/2019/06/22/GNN-Theory-WL.html