常用的Java集合有两部分组成Map与Collection
简介
- Collection
- Map
Map
- HashMap
hashMap既具有ArrayList的查询快,也具有LinkedList的增删快。其实将ArrayList(也叫哈希表)与LinkedList组合起来,就是我们经常使用的HashMap。
HashMap的数据结构
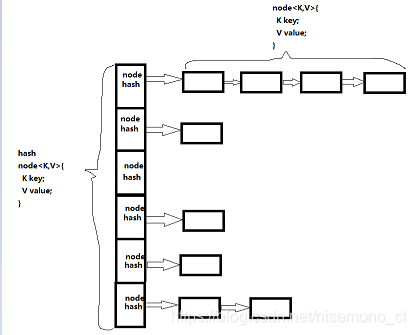
从源码中分析可知,初始化的时候这个ArrayList的长度为16。存放之后,肯定会出现键值对冲突问题。HashMap是如何解决键值对的冲突问题呢?
hashMap中引入了hashcode(),作为ArrayList的键值。 - 当要存放的ArrayList判断hash后为空的时候,就直接存放到ArrayList中
- 当要存放的ArrayList判断hash后不为空的时候,就在当前ArrayList的下标下,接上了一个单链表。
在1.8之前,新插入的元素都是放在了链表的头部位置,但是这种操作在高并发的环境下容易导致死锁,所以1.8之后,新插入的元素都放在了链表的尾部。
上源码
public class HashMap<K,V> extends AbstractMap<K,V>
implements Map<K,V>, Cloneable, Serializable {
//初始化的时候ArrayList的长度
static final int DEFAULT_INITIAL_CAPACITY = 1 << 4; // aka 16
//ArrayList最大可扩容长度
static final int MAXIMUM_CAPACITY = 1 << 30;
//加载因子 也就是说,当ArrayList存放数量达到了3/4,就会动态扩容ArrayList
static final float DEFAULT_LOAD_FACTOR = 0.75f;
//每个ArrayList的下标允许的最大单链表长度。一旦超过,单链表就换转化为红黑树
static final int TREEIFY_THRESHOLD = 8;
//Map中包含的元素数量
transient int size;
//阈值,用于判断是否需要扩容(threshold = 容量*负载因子)
int threshold;
//加载因子实际的大小
final float loadFactor;
//链表扩容的时候,每个节点
static class Node<K,V> implements Map.Entry<K,V> {
final int hash; //确定每个节点的hash值
final K key; //每个节点的键
V value; //每个节点的值
Node<K,V> next; //下一个节点指向
Node(int hash, K key, V value, Node<K,V> next) {
this.hash = hash;
this.key = key;
this.value = value;
this.next = next;
}
public final K getKey() { return key; }
public final V getValue() { return value; }
public final String toString() { return key + "=" + value; }
public final int hashCode() {
return Objects.hashCode(key) ^ Objects.hashCode(value);
}
public final V setValue(V newValue) {
V oldValue = value;
value = newValue;
return oldValue;
}
public final boolean equals(Object o) {
if (o == this)
return true;
if (o instanceof Map.Entry) {
Map.Entry<?,?> e = (Map.Entry<?,?>)o;
if (Objects.equals(key, e.getKey()) &&
Objects.equals(value, e.getValue()))
return true;
}
return false;
}
}
//hashMap的put方法
public V put(K key, V value) {
return putVal(hash(key), key, value, false, true);
}
final V putVal(int hash, K key, V value, boolean onlyIfAbsent,boolean evict) {
Node<K,V>[] tab;
Node<K,V> p;
int n, i;
if ((tab = table) == null || (n = tab.length) == 0) n = (tab = resize()).length;
/*如果table的在(n-1)&hash的值是空,就新建一个节点插入在该位置*/
if ((p = tab[i = (n - 1) & hash]) == null)
tab[i] = newNode(hash, key, value, null);
/*表示有冲突,开始处理冲突*/
else {
Node<K,V> e;
K k;
/*检查第一个Node,p是不是要找的值*/
if (p.hash == hash &&((k = p.key) == key || (key != null && key.equals(k))))
e = p;
else if (p instanceof TreeNode)
e = ((TreeNode<K,V>)p).putTreeVal(this, tab, hash, key, value);
else {
for (int binCount = 0; ; ++binCount) {
/*指针为空就挂在后面*/
if ((e = p.next) == null) {
p.next = newNode(hash, key, value, null);
//如果冲突的节点数已经达到8个,看是否需要改变冲突节点的存储结构,
//treeifyBin首先判断当前hashMap的长度,如果不足64,只进行
//resize,扩容table,如果达到64,那么将冲突的存储结构为红黑树
if (binCount >= TREEIFY_THRESHOLD - 1) // -1 for 1st
treeifyBin(tab, hash);
break;
}
/*如果有相同的key值就结束遍历*/
if (e.hash == hash &&((k = e.key) == key || (key != null && key.equals(k))))
break;
p = e;
}
}
/*就是链表上有相同的key值*/
if (e != null) { // existing mapping for key,就是key的Value存在
V oldValue = e.value;
if (!onlyIfAbsent || oldValue == null)
e.value = value;
afterNodeAccess(e);
return oldValue;//返回存在的Value值
}
}
++modCount;
/*如果当前大小大于门限,门限原本是初始容量*0.75*/
if (++size > threshold)
resize();//扩容两倍
afterNodeInsertion(evict);
return null;
}
}
大致执行流程图
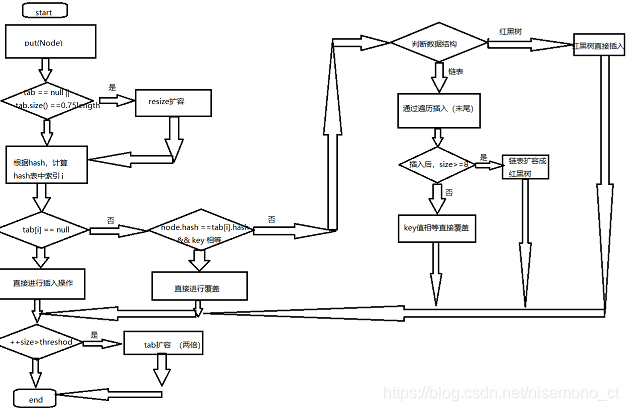
总的来说HashMap是以牺牲内存空间为代价,换取的高速的查询与插入删除操作的。
HashMap有且允许一个主键(key)的值为Null,value无限制。当出现多个主键为Null的值插入的时候,保留最后一个插入的元素的值。
2. HashTable
HashTable的实现原理几乎与HashMap类似。但是不同的是,hashTable中的方法。大部分了加了synchronized关键字。也就是线程同步的。并且,hashTable中只是使用了链表来解决hash冲突的问题,不会演化为红黑树。
public class Hashtable<K,V>
extends Dictionary<K,V>
implements Map<K,V>, Cloneable, java.io.Serializable {
/**
* The hash table data.
* ArrayList结构式的哈希表
*/
private transient Entry<?,?>[] table;
/**
* The total number of entries in the hash table.
* 统计哈希表的长度的
*/
private transient int count;
/**
* The table is rehashed when its size exceeds this threshold. (The
* value of this field is (int)(capacity * loadFactor).)
*
* @serial
* 判断哈希表是否需要扩容
*/
private int threshold;
//hashtable新增的方法
public synchronized V put(K key, V value) {
// Make sure the value is not null
if (value == null) {
throw new NullPointerException();
}
// Makes sure the key is not already in the hashtable.
Entry<?,?> tab[] = table;
int hash = key.hashCode();
int index = (hash & 0x7FFFFFFF) % tab.length;
@SuppressWarnings("unchecked")
Entry<K,V> entry = (Entry<K,V>)tab[index];
for(; entry != null ; entry = entry.next) {
if ((entry.hash == hash) && entry.key.equals(key)) {
V old = entry.value;
entry.value = value;
return old;
}
}
addEntry(hash, key, value, index);
return null;
}
//新增节点
private void addEntry(int hash, K key, V value, int index) {
modCount++;
Entry<?,?> tab[] = table;
if (count >= threshold) {
// Rehash the table if the threshold is exceeded
rehash();
tab = table;
hash = key.hashCode();
index = (hash & 0x7FFFFFFF) % tab.length;
}
// Creates the new entry.
@SuppressWarnings("unchecked")
Entry<K,V> e = (Entry<K,V>) tab[index];
tab[index] = new Entry<>(hash, key, value, e);
count++;
}
HashTable不允许主键(key)与值(value)为空的情况。若出现了主键为空的情况。编译可以通过,但是运行的时候会出现空指针异常。
- HashSet
HashSet的添加方法使用的是add()方法,但是我们debug可以发现。其实hashSet使用的就是HashMap的put方法进行新增。并且将新增的值放入到key当中,不设置value的值。
hashSet继承hashMap的加载因子0.75也就是3/4,初始容量也为16。扩容机制也与HashMap完全一样。
Map集合探究到此为止,本想继续深究LinkedHashMap与LinkedHashSet。但是Java的与Map有关的方法,被ExpiringCacheache(java.io包下的)修饰了,第二次往map相关的子类中存放东西,优先查询这个缓存类。导致的调试起来困难。
