(1)集合类体系结构:
- Collection单列集合,每个元素(数据)只包含一个值。
- Collection集合格式:[元素1,元素2,元素3...]。
- Map双列集合,每个元素包含两个值(键值对)。
- Map集合的完整格式:{key1=value1,key2=value2,key3=value3...}。
(2)Collection集合体系如下(无边框的是接口,有边框的是实现类):
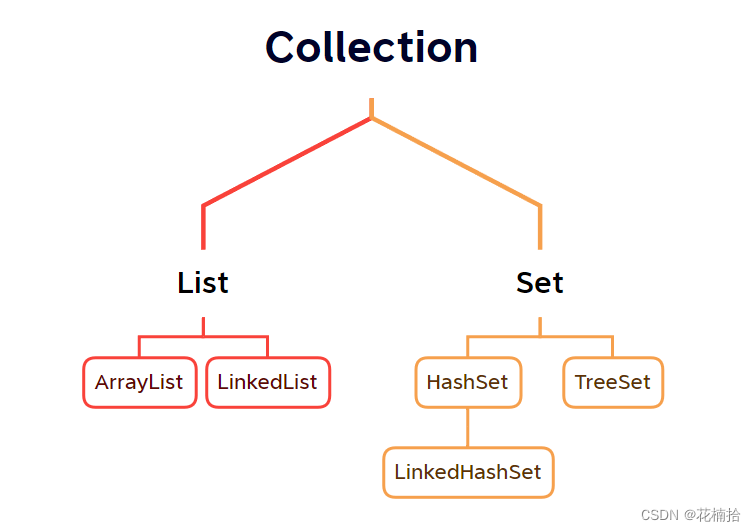
(3)Collection集合特点:
1.List系列集合:(ArrayList,LinkedList)添加的元素是有序,可重复,有索引。
- 有序:存储和取出元素顺序一致。
- 有索引:可以通过索引操作元素。
- 可重复:存储的元素可以重复。
2.Set系列集合:(HashSet)添加的元素是无序,不重复,无索引。
- 无序:存取顺序不一致。
- 不重复:可以去除重复。
- 无索引:没有带索引的方法,所以不能使用普通for循环遍历,也不能通过索引取元素。
- LinkedHashSet:有序,不重复,无索引。
- TreeSet:按照大小默认升序排序,不重复,无索引。
(4)Map集合体系如下(无边框的是接口,有边框的是实现类):
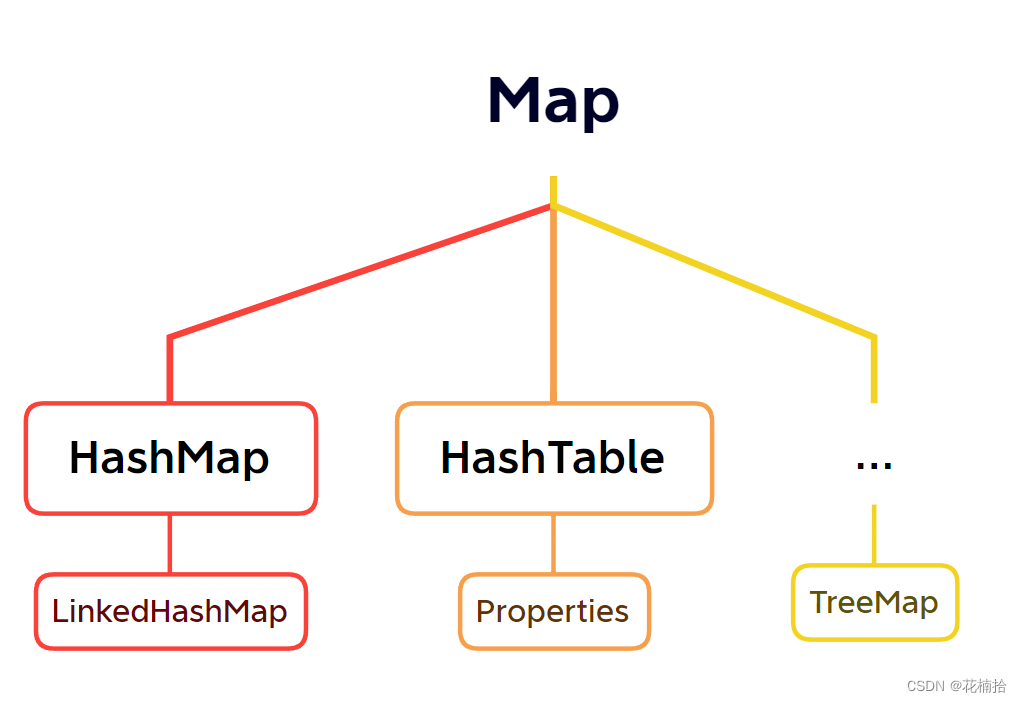
- 使用最多的Map集合是HashMap。
- 重点掌握HashMap,LinkedHashMap,TreeMap。
(5)Map集合体系特点:
- Map集合的键无序,不重复。
- Map集合的值不做要求,可重复。
- Map集合后面重复的键对应的值会覆盖前面重复键的值。
- Map集合的键值对都可以为null。
(6)Map集合实现类特点:
- HashMap:元素按照键是无序,不重复,无索引,值不做要求。(与Map体系一致)
- LinkedHashMap:元素按照键是有序,不重复,无索引,值不做要求。
- TreeMap:元素按照键是排序,不重复,无索引,值不做要求。
1.HashMap
特点:
- 特点都是由键决定:无序,不重复,无索引。
- 没有额外的学习方法,直接使用Map里面的方法即可。
- HashMap跟HashSet底层原理是一模一样的,都是哈希表结果,只是HashMap的每个元素包含两个值而已(Set系列集合的底层就是Map实现的,只是Set集合只要键数据,不要值数据)。
- 依赖hashCode方法和equals方法保证键的唯一(如果键要存储的是自定义对象,需要重写hashCode方法和equals方法)。
2.LinkedHashMap
特点:
- 由键决定:有序(保证存储和取出的元素顺序一致),不重复,无索引
- 原理:底层数据结构是依然哈希表,只是每个键值对元素又额外的多了一个双链表的机制记录存储的顺序。
3.TreeMap
特点:
- 可排序:按照键数据大小默认升序(有小到大)排序。只能对键排序。(TreeMap集合是一定要排序,可以默认排序,也可以将键按照指定的规则进行排序==》自定义排序规则:1.类实现Comparable接口,重写比较规则。2.集合自定义Comparator比较器对象,重写比较规则。)
- TreeMap跟TreeSet一样底层原理。