准备
1、hadoop已部署(若没有可以参考:Centos7安装Hadoop2.7),集群情况如下(IP地址与之前文章有变动):
| hostname | IP地址 | 部署规划 |
| node1 | 172.20.0.2 | NameNode、DataNode |
| node2 | 172.20.0.3 | DataNode |
| node3 | 172.20.0.4 | DataNode |
2、官网下载安装包:spark-2.4.4-bin-hadoop2.7.tgz(推荐去清华大学或中科大的开源镜像站)。
3、spark将部署在三台都已存在的路径/mydata,配置环境变量:
export SPARK_HOME=/mydata/spark-2.4.4 export PATH=${SPARK_HOME}/bin:${SPARK_HOME}/sbin:$PATH
本地模式
在机器node1解压spark-2.4.4-bin-hadoop2.7.tgz到/mydata,并重命名文件夹为/mydata/spark-2.4.4。
跟hadoop文章保持一致,下面执行一个spark版的wordcount任务(Python版本):
shell> vim 1.txt # 创建一个文件,写入一些内容
hadoop hadoop
hbase hbase hbase
spark spark spark spark
shell> spark-submit $SPARK_HOME/examples/src/main/python/wordcount.py 1.txt # 向spark提交wordcount任务,统计1.txt中的单词及其数量,结果如下
spark: 4
hbase: 3
hadoop: 2
spark是一个计算引擎,查看文件wordcount.py可以看到实现同样的功能,其代码量远小于mapreduce,大大降低了大数据的开发难度。
Standalone模式
可以翻译成独立模式,由spark自带的集群来完成除了存储以外的工作;下面先在node1上进行配置:
spark的配置文件位于 $SPARK_HOME/conf:
从 spark-env.sh.template 拷贝一个 spark-env.sh
从 slaves.template 拷贝一个slaves
# 文件名 spark-env.sh SPARK_MASTER_HOST=node1 SPARK_LOCAL_DIRS=/mydata/data/spark/scratch SPARK_WORKER_DIR=/mydata/data/spark/work SPARK_PID_DIR=/mydata/data/pid SPARK_LOG_DIR=/mydata/logs/spark
# 文件名 slaves
node1
node2
node3
由于 $SPARK_HOME/sbin 下的start-all.sh和stop-all.sh与hadoop冲突,建议进行重命名:
shell> mv start-all.sh spark-start-all.sh shell> mv stop-all.sh spark-stop-all.sh
配置完成后将spark程序文件拷贝到其他两台:
shell> scp -qr /mydata/spark-2.4.4/ root@node2:/mydata/ shell> scp -qr /mydata/spark-2.4.4/ root@node3:/mydata/
然后在node1启动集群:
shell> spark-start-all.sh
| node1上用jps命令验证进程 | Master、Worker |
| node2上用jps命令验证进程 | Worker |
| node3上用jps命令验证进程 | Worker |
可以通过浏览器访问 http://node1:8080/ :

下面把上一节的文件1.txt多复制一份为2.txt,然后都放到hdfs上,最后通过spark集群执行wordcount任务:
shell> cp 1.txt 2.txt
shell> hdfs dfs -mkdir /tmp/wc/
shell> hdfs dfs -put 1.txt 2.txt /tmp/wc/
shell> spark-submit --master spark://node1:7077 $SPARK_HOME/examples/src/main/python/wordcount.py hdfs://node1:9000/tmp/wc/*
shell> spark-submit --master spark://node1:7077 $SPARK_HOME/examples/src/main/python/pi.py 9 # 顺带测试一个计算圆周率的任务,最后的数字9表示分片(partitions)数量,输出结果类似这样:Pi is roughly 3.137564
在 http://node1:8080/ 上可以看到执行的任务:
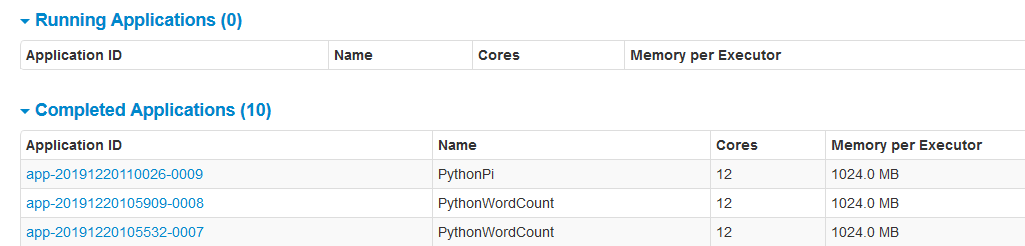
Yarn模式
实际使用中,通常是让spark运行于已存在的集群,比如利用hadoop自带的yarn来进行资源调度。
spark on yarn不需要spark的集群,所以停掉它:
shell> spark-stop-all.sh
配置很简单,只需要有这个环境变量即可:
export HADOOP_CONF_DIR=${HADOOP_HOME}/etc/hadoop
不过,为了方便查看历史记录和日志,这里要配置 spark history server ,并且与hadoop的jobhistory联系起来:
进入目录 $SPARK_HOME/conf,从spark-defaults.conf.template拷贝一个spark-defaults.conf:
# 文件名 spark-defaults.conf spark.eventLog.enabled true spark.eventLog.dir hdfs://node1:9000/spark/history spark.history.fs.logDirectory hdfs://node1:9000/spark/history spark.yarn.historyServer.allowTracking true spark.yarn.historyServer.address node1:18080
进入目录 $HADOOP_HOME/etc/hadoop,在 yarn-site.xml 中添加一下内容:
# 文件名 yarn-site.xml <property> <name>yarn.log.server.url</name> <value>http://node1:19888/jobhistory/logs/</value> </property>
在hdfs创建必要的路径:
shell> hdfs dfs -mkdir -p /spark/history
将hadoop和spark的配置同步更新到其他所有节点(勿忘)。
下面在node1重启yarn,并且启动spark history server:
shell> stop-yarn.sh
shell> start-yarn.sh
shell> start-history-server.sh # 启动后通过jps可以看到多出一个HistoryServer
执行下面的命令,通过yarn及cluster模式执行wordcount任务:
shell> spark-submit --master yarn --deploy-mode cluster $SPARK_HOME/examples/src/main/python/wordcount.py hdfs://node1:9000/tmp/wc/*
浏览器访问 http://node1:18080/ 可以看到spark的history:
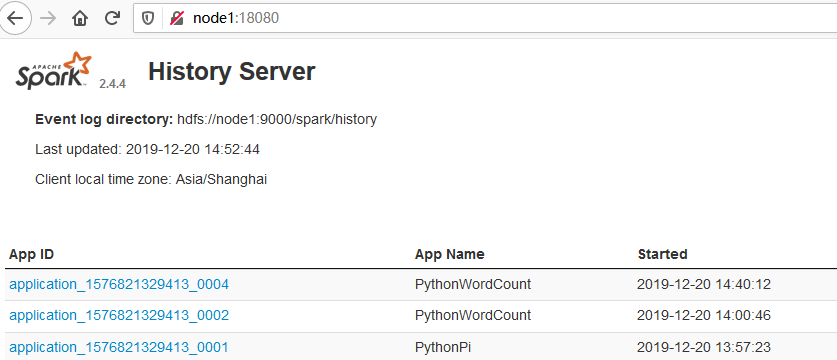
点击 App ID 进入,然后定位到 Executors ,找到 Executor ID 为driver的,查看它的stdout或stderr:

即可看到日志和计算结果:

同样,可以通过yarn命令访问日志:
shell> yarn logs -applicationId [application id]
over