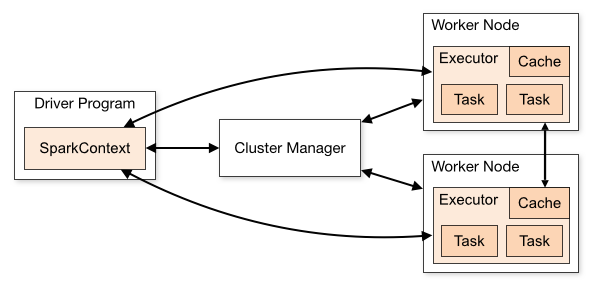
从物理部署层面上来看,Spark主要分为两种类型的节点,Master节点和Worker节点,Master节点主要运行集群管理器的中心化部分,所承载的作用是分配Application到Worker节点,维护Worker节点,Driver,Application的状态。Worker节点负责具体的业务运行。
从Spark程序运行的层面来看,Spark主要分为驱动器节点和执行器节点。
1、机器准备
准备两台以上Linux服务器,安装好JDK1.8
我这里的是
| ip地址 | 系统 |
|---|---|
| Carlota1 | CentOS7.3 |
| Carlota2 | CentOS7.3 |
| Carlota3 | CentOS7.3 |
2、下载Spark安装包
http://spark.apache.org/downloads.html
3、上传解压
//上传
scp spark-3.0.1-bin-hadoop3.2.tgz root@Carlota1:/usr/local/apps/
scp spark-3.0.1-bin-hadoop3.2.tgz root@Carlota2:/usr/local/apps/
scp spark-3.0.1-bin-hadoop3.2.tgz root@Carlota3:/usr/local/apps/
//解压
tar -zxvf spark-3.0.1-bin-hadoop3.2.tgz
//改个名
mv spark-3.0.1-bin-hadoop3.2 spark-3.0.1
4、配置环境变量
vi /etc/profile
#Spark
export SPARK_HOME=/usr/local/apps/spark-3.0.1
export PATH=$PATH:$SPARK_HOME/bin:$SPARK_HOME/sbin
source /etc/profile
5、配置Spark【Standalone模式】
Spark的部署模式有Local、Local-Cluster、Standalone、Yarn、Mesos,我们选择最具代表性的Standalone集群部署模式。
-
进入到Spark安装目录
cd /usr/local/apps/spark-3.0.1/conf -
将slaves.template复制为slaves
cp slaves.template slaves -
将spark-env.sh.template复制为spark-env.sh
cp spark-env.sh.template spark-env.sh -
修改slaves文件,将work的hostname输入
vi slaves
Carlota2
Carlota3
- 修改spark-env.sh文件
vi spark-env.sh,添加如下配置:
SPARK_MASTER_HOST=Cralota1
SPARK_MASTER_PORT=7077
- 同步数据到Carlota2和Carlota3
scp -r conf root@Carlota2:/usr/local/apps/spark-3.0.1
scp -r conf root@Carlota3:/usr/local/apps/spark-3.0.1
-
进入sbin目录
-
vi spark-config.sh在下方添加
JAVA_HOME=/usr/local/java/jdk1.8
- 同步一下
scp -r spark-config.sh root@Carlota2:/usr/local/apps/spark-3.0.1/sbin
scp -r spark-config.sh root@Carlota3:/usr/local/apps/spark-3.0.1/sbin
Spark集群配置完毕,目前是1个Master,2个Wor
6、Spark启动集群
- Carlota1上启动集群
./sbin/start-all.sh
[root@Carlota1 spark-3.0.1]# ./sbin/start-all.sh
starting org.apache.spark.deploy.master.Master, logging to /usr/local/apps/spark-3.0.1/logs/spark-root-org.apache.spark.deploy.master.Master-1-Carlota1.out
Carlota2: starting org.apache.spark.deploy.worker.Worker, logging to /usr/local/apps/spark-3.0.1/logs/spark-root-org.apache.spark.deploy.worker.Worker-1-Carlota2.out
Carlota3: starting org.apache.spark.deploy.worker.Worker, logging to /usr/local/apps/spark-3.0.1/logs/spark-root-org.apache.spark.deploy.worker.Worker-1-Carlota3.out
- 启动后执行jps命令,主节点上有Master进程,其他子节点上有Work进行
[root@Carlota1 spark-3.0.1]# jps
10551 Master
10603 Jps
[root@Carlota3 spark-3.0.1]# jps
17085 Jps
16959 Worker
- 登录Spark管理界面查看集群状态(主节点):http://Carlota1:8080/

到此为止,Spark集群安装完毕.
注意:如果遇到 “JAVA_HOME not set” 异常,可以在sbin目录下的spark-config.sh 文件中加入如下配置:
export JAVA_HOME=XXXX