Multiple Regression
When to use it
Null hypothesis
How it works
Using nominal variables in a multiple regression
Selecting variables in multiple regression
Assumptions
See the Handbook for information on these topics.
Example
The Maryland Biological Stream Survey example is shown in the “How to do the multiple regression” section.

Graphing the results
Similar tests
See the Handbook for information on these topics.
How to do multiple regression
Multiple correlation
Whenever you have a dataset with multiple numeric variables, it is a good idea to look at the correlations among these variables. One reason is that if you have a dependent variable, you can easily see which independent variables correlate with that dependent variable. A second reason is that if you will be constructing a multiple regression model, adding an independent variable that is strongly correlated with an independent variable already in the model is unlikely to improve the model much, and you may have good reason to chose one variable over another.
Finally, it is worthwhile to look at the distribution of the numeric variables. If the distributions differ greatly, using Kendall or Spearman correlations may be more appropriate. Also, if independent variables differ in distribution from the dependent variable, the independent variables may need to be transformed. In this example, Longnose, Acreage, Maxdepth, NO3, and SO4 are relatively log-normally distributed, while DO2 and Temp are relatively normal in distribution. It may be advisable in this case to transform these variable so that they all have similar distributions (not shown here).
With the corr.test function in the psych package, the “Correlation matrix” shows r-values and the “Probability values” table shows p-values. The PerformanceAnalytics plot shows r-values, with asterisks indicating significance, as well as a histogram of the individual variables. Either of these indicates that Longnose is significantly correlated with Acreage, Maxdepth, and NO3.
### --------------------------------------------------------------
### Multiple correlation and regression, stream survey example
### pp. 236–237
### --------------------------------------------------------------
Input = ("
Stream Longnose Acerage DO2 Maxdepth NO3 SO4 Temp
BASIN_RUN 13 2528 9.6 80 2.28 16.75 15.3
BEAR_BR 12 3333 8.5 83 5.34 7.74 19.4
BEAR_CR 54 19611 8.3 96 0.99 10.92 19.5
BEAVER_DAM_CR 19 3570 9.2 56 5.44 16.53 17
BEAVER_RUN 37 1722 8.1 43 5.66 5.91 19.3
BENNETT_CR 2 583 9.2 51 2.26 8.81 12.9
BIG_BR 72 4790 9.4 91 4.1 5.65 16.7
BIG_ELK_CR 164 35971 10.2 81 3.2 17.53 13.8
BIG_PIPE_CR 18 25440 7.5 120 3.53 8.2 13.7
BLUE_LICK_RUN 1 2217 8.5 46 1.2 10.85 14.3
BROAD_RUN 53 1971 11.9 56 3.25 11.12 22.2
BUFFALO_RUN 16 12620 8.3 37 0.61 18.87 16.8
BUSH_CR 32 19046 8.3 120 2.93 11.31 18
CABIN_JOHN_CR 21 8612 8.2 103 1.57 16.09 15
CARROLL_BR 23 3896 10.4 105 2.77 12.79 18.4
COLLIER_RUN 18 6298 8.6 42 0.26 17.63 18.2
CONOWINGO_CR 112 27350 8.5 65 6.95 14.94 24.1
DEAD_RUN 25 4145 8.7 51 0.34 44.93 23
DEEP_RUN 5 1175 7.7 57 1.3 21.68 21.8
DEER_CR 26 8297 9.9 60 5.26 6.36 19.1
DORSEY_RUN 8 7814 6.8 160 0.44 20.24 22.6
FALLS_RUN 15 1745 9.4 48 2.19 10.27 14.3
FISHING_CR 11 5046 7.6 109 0.73 7.1 19
FLINTSTONE_CR 11 18943 9.2 50 0.25 14.21 18.5
GREAT_SENECA_CR 87 8624 8.6 78 3.37 7.51 21.3
GREENE_BR 33 2225 9.1 41 2.3 9.72 20.5
GUNPOWDER_FALLS 22 12659 9.7 65 3.3 5.98 18
HAINES_BR 98 1967 8.6 50 7.71 26.44 16.8
HAWLINGS_R 1 1172 8.3 73 2.62 4.64 20.5
HAY_MEADOW_BR 5 639 9.5 26 3.53 4.46 20.1
HERRINGTON_RUN 1 7056 6.4 60 0.25 9.82 24.5
HOLLANDS_BR 38 1934 10.5 85 2.34 11.44 12
ISRAEL_CR 30 6260 9.5 133 2.41 13.77 21
LIBERTY_RES 12 424 8.3 62 3.49 5.82 20.2
LITTLE_ANTIETAM_CR 24 3488 9.3 44 2.11 13.37 24
LITTLE_BEAR_CR 6 3330 9.1 67 0.81 8.16 14.9
LITTLE_CONOCOCHEAGUE_CR 15 2227 6.8 54 0.33 7.6 24
LITTLE_DEER_CR 38 8115 9.6 110 3.4 9.22 20.5
LITTLE_FALLS 84 1600 10.2 56 3.54 5.69 19.5
LITTLE_GUNPOWDER_R 3 15305 9.7 85 2.6 6.96 17.5
LITTLE_HUNTING_CR 18 7121 9.5 58 0.51 7.41 16
LITTLE_PAINT_BR 63 5794 9.4 34 1.19 12.27 17.5
MAINSTEM_PATUXENT_R 239 8636 8.4 150 3.31 5.95 18.1
MEADOW_BR 234 4803 8.5 93 5.01 10.98 24.3
MILL_CR 6 1097 8.3 53 1.71 15.77 13.1
MORGAN_RUN 76 9765 9.3 130 4.38 5.74 16.9
MUDDY_BR 25 4266 8.9 68 2.05 12.77 17
MUDLICK_RUN 8 1507 7.4 51 0.84 16.3 21
NORTH_BR 23 3836 8.3 121 1.32 7.36 18.5
NORTH_BR_CASSELMAN_R 16 17419 7.4 48 0.29 2.5 18
NORTHWEST_BR 6 8735 8.2 63 1.56 13.22 20.8
NORTHWEST_BR_ANACOSTIA_R 100 22550 8.4 107 1.41 14.45 23
OWENS_CR 80 9961 8.6 79 1.02 9.07 21.8
PATAPSCO_R 28 4706 8.9 61 4.06 9.9 19.7
PINEY_BR 48 4011 8.3 52 4.7 5.38 18.9
PINEY_CR 18 6949 9.3 100 4.57 17.84 18.6
PINEY_RUN 36 11405 9.2 70 2.17 10.17 23.6
PRETTYBOY_BR 19 904 9.8 39 6.81 9.2 19.2
RED_RUN 32 3332 8.4 73 2.09 5.5 17.7
ROCK_CR 3 575 6.8 33 2.47 7.61 18
SAVAGE_R 106 29708 7.7 73 0.63 12.28 21.4
SECOND_MINE_BR 62 2511 10.2 60 4.17 10.75 17.7
SENECA_CR 23 18422 9.9 45 1.58 8.37 20.1
SOUTH_BR_CASSELMAN_R 2 6311 7.6 46 0.64 21.16 18.5
SOUTH_BR_PATAPSCO 26 1450 7.9 60 2.96 8.84 18.6
SOUTH_FORK_LINGANORE_CR 20 4106 10.0 96 2.62 5.45 15.4
TUSCARORA_CR 38 10274 9.3 90 5.45 24.76 15
WATTS_BR 19 510 6.7 82 5.25 14.19 26.5
")
Data = read.table(textConnection(Input),header=TRUE)
### Create a new data frame with only the numeric variables.
### This is required for corr.test and chart.Correlation
library(dplyr)
Data.num =
select(Data,
Longnose,
Acerage,
DO2,
Maxdepth,
NO3,
SO4,
Temp)
library(FSA)
headtail(Data.num)
Longnose Acerage DO2 Maxdepth NO3 SO4 Temp
1 13 2528 9.6 80 2.28 16.75 15.3
2 12 3333 8.5 83 5.34 7.74 19.4
3 54 19611 8.3 96 0.99 10.92 19.5
66 20 4106 10.0 96 2.62 5.45 15.4
67 38 10274 9.3 90 5.45 24.76 15.0
68 19 510 6.7 82 5.25 14.19 26.5
library(psych)
corr.test(Data.num,
use = "pairwise",
method="pearson",
adjust="none", # Can adjust p-values; see ?p.adjust for options
alpha=.05)
Correlation matrix
Longnose Acerage DO2 Maxdepth NO3 SO4 Temp
Longnose 1.00 0.35 0.14 0.30 0.31 -0.02 0.14
Acerage 0.35 1.00 -0.02 0.26 -0.10 0.05 0.00
DO2 0.14 -0.02 1.00 -0.06 0.27 -0.07 -0.32
Maxdepth 0.30 0.26 -0.06 1.00 0.04 -0.05 0.00
NO3 0.31 -0.10 0.27 0.04 1.00 -0.09 0.00
SO4 -0.02 0.05 -0.07 -0.05 -0.09 1.00 0.08
Temp 0.14 0.00 -0.32 0.00 0.00 0.08 1.00
Sample Size
Probability values (Entries above the diagonal are adjusted for multiple tests.)
Longnose Acerage DO2 Maxdepth NO3 SO4 Temp
Longnose 0.00 0.00 0.27 0.01 0.01 0.89 0.26
Acerage 0.00 0.00 0.86 0.03 0.42 0.69 0.98
DO2 0.27 0.86 0.00 0.64 0.02 0.56 0.01
Maxdepth 0.01 0.03 0.64 0.00 0.77 0.69 0.97
NO3 0.01 0.42 0.02 0.77 0.00 0.48 0.99
SO4 0.89 0.69 0.56 0.69 0.48 0.00 0.52
Temp 0.26 0.98 0.01 0.97 0.99 0.52 0.00
pairs(data=Data,
~ Longnose + Acerage + DO2 + Maxdepth + NO3 + SO4 + Temp)
library(PerformanceAnalytics)
chart.Correlation(Data.num,
method="pearson",
histogram=TRUE,
pch=16)
Multiple regression
Model selection using the step function
The step function has options to add terms to a model (direction="forward"), remove terms from a model (direction="backward"), or to use a process that both adds and removes terms (direction="both"). It uses AIC (Akaike information criterion) as a selection criterion. You can use the option k = log(n) to use BIC instead.
You can add the test="F" option to see the p-value for adding or removing terms, but the test will still follow the AIC statistic. If you use this, however, note that a significant p-value essentially argues for the term being included in the model, whether it’s its addition or its removal that’s being considered.
A full model and a null are defined, and then the function will follow a procedure to find the model with the lowest AIC. The final model is shown at the end of the output, with the Call: indication, and lists the coefficients for that model.
Stepwise procedure
model.null = lm(Longnose ~ 1,
data=Data)
model.full = lm(Longnose ~ Acerage + DO2 + Maxdepth + NO3 + SO4 + Temp,
data=Data)
step(model.null,
scope = list(upper=model.full),
direction="both",
data=Data)
Longnose ~ 1
Df Sum of Sq RSS AIC
+ Acerage 1 17989.6 131841 518.75
+ NO3 1 14327.5 135503 520.61
+ Maxdepth 1 13936.1 135894 520.81
<none> 149831 525.45
+ Temp 1 2931.0 146899 526.10
+ DO2 1 2777.7 147053 526.17
+ SO4 1 45.3 149785 527.43
.
.
< snip... more steps >
.
.
Longnose ~ Acerage + NO3 + Maxdepth
Df Sum of Sq RSS AIC
<none> 107904 509.13
+ Temp 1 2948.0 104956 509.24
+ DO2 1 669.6 107234 510.70
- Maxdepth 1 6058.4 113962 510.84
+ SO4 1 5.9 107898 511.12
- Acerage 1 14652.0 122556 515.78
- NO3 1 16489.3 124393 516.80
Call:
lm(formula = Longnose ~ Acerage + NO3 + Maxdepth, data = Data)
Coefficients:
(Intercept) Acerage NO3 Maxdepth
-23.829067 0.001988 8.673044 0.336605
Define final model
model.final = lm(Longnose ~ Acerage + Maxdepth + NO3,
data=Data)
summary(model.final) # Show coefficients, R-squared, and overall p-value
Estimate Std. Error t value Pr(>|t|)
(Intercept) -2.383e+01 1.527e+01 -1.560 0.12367
Acerage 1.988e-03 6.742e-04 2.948 0.00446 **
Maxdepth 3.366e-01 1.776e-01 1.896 0.06253 .
NO3 8.673e+00 2.773e+00 3.127 0.00265 **
Multiple R-squared: 0.2798, Adjusted R-squared: 0.2461
F-statistic: 8.289 on 3 and 64 DF, p-value: 9.717e-05
Analysis of variance for individual terms
library(car)
Anova(model.final,
Type="II")
Anova Table (Type II tests)
Response: Longnose
Sum Sq Df F value Pr(>F)
Acerage 14652 1 8.6904 0.004461 **
Maxdepth 6058 1 3.5933 0.062529 .
NO3 16489 1 9.7802 0.002654 **
Residuals 107904 64
Simple plot of predicted values with 1-to-1 line
Data$predy = predict(model.final)
plot(predy ~ Longnose,
data=Data,
pch = 16,
xlab="Actual response value",
ylab="Predicted response value")
abline(0,1, col="blue", lwd=2)
Checking assumptions of the model
hist(residuals(model.final),
col="darkgray")
A histogram of residuals from a linear model. The distribution of these residuals should be approximately normal.
plot(fitted(model.final),
residuals(model.final)
)
A plot of residuals vs. predicted values. The residuals should be unbiased and homoscedastic. For an illustration of these properties, see this diagram by Steve Jost at DePaul University: condor.depaul.edu/sjost/it223/documents/resid-plots.gif.
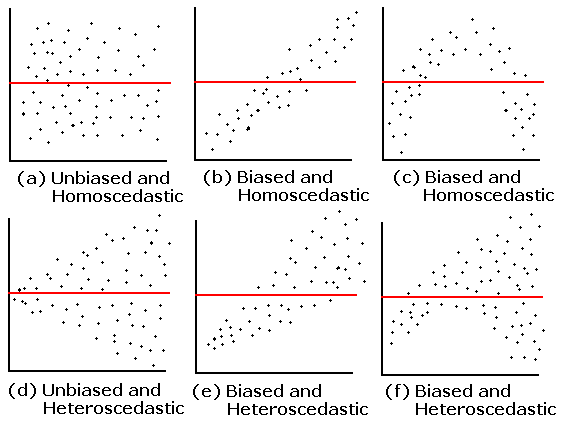{kind=link}
### additional model checking plots with: plot(model.final)
Model fit criteria
Model fit criteria are available to decide which model is most appropriate. The step function uses AIC, or optionally BIC, but there are others. You don’t want to use multiple R-squared, because it will continue to improve as more terms are added into the model. Instead, you want to use a criterion that balances the improvement in explanatory power with not adding extraneous terms to the model. Adjusted R-squared is a modification of R-squared that includes this balance. Larger is better. AIC is based on information theory and measures this balance. AICc is an adjustment to AIC that is more appropriate for data sets with relatively fewer observations. BIC is similar to AIC, but penalizes more for additional terms in the model. Smaller is better for AIC, AICc, and BIC. There are differing opinions on which model fitting criteria is best to use, but if you have no opinion, I would recommend AICc for routine use.
Using the step procedure to automatically find an optimal model is an option, but some people caution against using an automated procedure because it might not hone in on the best model. Instead, you can look at the model fit criteria for competing models manually. There may be reasons why you wish to include or exclude some terms in the model, and it may be useful to look at different model selection criteria simultaneously.
In my compare.lm function below, Shapiro.W and Shapiro.p are results from the Shapiro–Wilks test for normality on the model residuals. A higher Shapiro W and a higher Shapiro p indicate that the residuals are more normally distributed. You should be aware, however, that any model with a high number of observation may yield a significant p-value (p < 0.05) for the Shapiro–Wilks test. It is best to investigate the residuals visually.
In the following example, we’ll look only at the terms that are significantly correlated with Longnose(Acreage, Maxdepth, and NO3), and then add in the other terms just to show the decrease in AICc by adding extra terms.
Note that AIC and BIC are calculated differently than in the step function.
model.1 = lm(Longnose ~ Acerage, data=Data)
model.2 = lm(Longnose ~ Maxdepth, data=Data)
model.3 = lm(Longnose ~ NO3, data=Data)
model.4 = lm(Longnose ~ Acerage + Maxdepth, data=Data)
model.5 = lm(Longnose ~ Acerage + NO3, data=Data)
model.6 = lm(Longnose ~ Maxdepth + NO3, data=Data)
model.7 = lm(Longnose ~ Acerage + Maxdepth + NO3, data=Data)
model.8 = lm(Longnose ~ Acerage + Maxdepth + NO3 + DO2, data=Data)
model.9 = lm(Longnose ~ Acerage + Maxdepth + NO3 + SO4, data=Data)
model.10 = lm(Longnose ~ Acerage + Maxdepth + NO3 + Temp, data=Data)
library(rcompanion)
compareLM(model.1, model.2, model.3, model.4, model.5, model.6,
model.7, model.8, model.9, model.10)
$Models
Formula
1 "Longnose ~ Acerage"
2 "Longnose ~ Maxdepth"
3 "Longnose ~ NO3"
4 "Longnose ~ Acerage + Maxdepth"
5 "Longnose ~ Acerage + NO3"
6 "Longnose ~ Maxdepth + NO3"
7 "Longnose ~ Acerage + Maxdepth + NO3"
8 "Longnose ~ Acerage + Maxdepth + NO3 + DO2"
9 "Longnose ~ Acerage + Maxdepth + NO3 + SO4"
10 "Longnose ~ Acerage + Maxdepth + NO3 + Temp"
$Fit.criteria
Rank Df.res AIC AICc BIC R.squared Adj.R.sq p.value Shapiro.W Shapiro.p
1 2 66 713.7 714.1 720.4 0.12010 0.10670 3.796e-03 0.7278 6.460e-10
2 2 66 715.8 716.2 722.4 0.09301 0.07927 1.144e-02 0.7923 2.115e-08
3 2 66 715.6 716.0 722.2 0.09562 0.08192 1.029e-02 0.7361 9.803e-10
4 3 65 711.8 712.4 720.6 0.16980 0.14420 2.365e-03 0.7934 2.250e-08
5 3 65 705.8 706.5 714.7 0.23940 0.21600 1.373e-04 0.7505 2.055e-09
6 3 65 710.8 711.4 719.6 0.18200 0.15690 1.458e-03 0.8149 8.405e-08
7 4 64 704.1 705.1 715.2 0.27980 0.24610 9.717e-05 0.8108 6.511e-08
8 5 63 705.7 707.1 719.0 0.28430 0.23890 2.643e-04 0.8041 4.283e-08
9 5 63 706.1 707.5 719.4 0.27990 0.23410 3.166e-04 0.8104 6.345e-08
10 5 63 704.2 705.6 717.5 0.29950 0.25500 1.409e-04 0.8225 1.371e-07
### Model 7 is the model which minimizes AICc, which is the same model
### chosen by the step function
Result = compare.lm(model.1, model.2, model.3, model.4, model.5, model.6,
model.7, model.8, model.9, model.10)
plot(Result$Fit.criteria$AICc,
xlab = "Model number",
ylab = "AICc")
lines(Result$Fit.criteria$AICc)
A plot of AICc (modified Akaike information criterion) of several models. Model 7 minimizes AICc, and is therefore chosen as the best model out of this set.
Comparing models with likelihood ratio test
It may also be helpful to compare models with the extra sum of squares test or likelihood ratio test to see if additional terms significantly reduce the error sum of squares.
One of the compared models should be nested within the other. That is, the one model should be the same as the other, except with additional terms. For example in the set of models below, it is appropriate to compare model.7 to model.4. Or to compare each of model.8, model.9, and model.10 to model.7.
For a single comparison, the anova function can be used for the Extra SS test, or lrtest in lmtest can be used for the likelihood ratio test. For multiple comparisons, the extraSS and lrt functions in the FSA package can be used. The extraSS function works only for lm and nls models, whereas the lrt function works on a wider range of model objects.
model.4 = lm(Longnose ~ Acerage + Maxdepth, data=Data)
model.7 = lm(Longnose ~ Acerage + Maxdepth + NO3, data=Data)
model.8 = lm(Longnose ~ Acerage + Maxdepth + NO3 + DO2, data=Data)
model.9 = lm(Longnose ~ Acerage + Maxdepth + NO3 + SO4, data=Data)
model.10 = lm(Longnose ~ Acerage + Maxdepth + NO3 + Temp, data=Data)
anova(model.7, model.4)
Analysis of Variance Table
Model 1: Longnose ~ Acerage + Maxdepth + NO3
Model 2: Longnose ~ Acerage + Maxdepth
Res.Df RSS Df Sum of Sq F Pr(>F)
1 64 107904
2 65 124393 -1 -16489 9.7802 0.002654 **
library(lmtest)
lrtest(model.7, model.4)
Likelihood ratio test
Model 1: Longnose ~ Acerage + Maxdepth + NO3
Model 2: Longnose ~ Acerage + Maxdepth
#Df LogLik Df Chisq Pr(>Chisq)
1 5 -347.05
2 4 -351.89 -1 9.6701 0.001873 **
library(FSA)
extraSS(model.8, model.9, model.10,
com=model.7)
Model 1: Longnose ~ Acerage + Maxdepth + NO3 + DO2
Model 2: Longnose ~ Acerage + Maxdepth + NO3 + SO4
Model 3: Longnose ~ Acerage + Maxdepth + NO3 + Temp
Model A: Longnose ~ Acerage + Maxdepth + NO3
DfO RSSO DfA RSSA Df SS F Pr(>F)
1vA 63 107234.38 64 107903.97 -1 -669.59 0.3934 0.5328
2vA 63 107898.06 64 107903.97 -1 -5.91 0.0035 0.9533
3vA 63 104955.97 64 107903.97 -1 -2948.00 1.7695 0.1882
lrt(model.8, model.9, model.10,
com=model.7)
Model 1: Longnose ~ Acerage + Maxdepth + NO3 + DO2
Model 2: Longnose ~ Acerage + Maxdepth + NO3 + SO4
Model 3: Longnose ~ Acerage + Maxdepth + NO3 + Temp
Model A: Longnose ~ Acerage + Maxdepth + NO3
DfO logLikO DfA logLikA Df logLik Chisq Pr(>Chisq)
1vA 63 -346.83881 64 -347.05045 -1 0.21164 0.4233 0.5153
2vA 63 -347.04859 64 -347.05045 -1 0.00186 0.0037 0.9513
3vA 63 -346.10863 64 -347.05045 -1 0.94182 1.8836 0.1699
# # #
Power analysis
See the Handbook for information on this topic.