单变量线性回归方程的表达式为
h
θ
(
x
)
=
θ
0
+
θ
1
x
h_\theta(x)=\theta_0+\theta_1x
h θ ( x ) = θ 0 + θ 1 x
但现实生活中往往预测值不止受一个变量的影响,由此我们探讨多元线性回归。
现在我们对房价模型增加更多的特征,例如房间数楼层等,构成一个含有多个变量的模型,模型中的特征为
(
x
1
,
x
2
,
.
.
.
,
x
n
)
\left( {x_{1}},{x_{2}},...,{x_{n}} \right)
( x 1 , x 2 , . . . , x n )
n
n
n
x
(
i
)
{x^{\left( i \right)}}
x ( i )
i
i
i
i
i
i 向量 (vector )。
x
j
(
i
)
{x}_{j}^{\left( i \right)}
x j ( i )
i
i
i
j
j
j
i
i
i
j
j
j
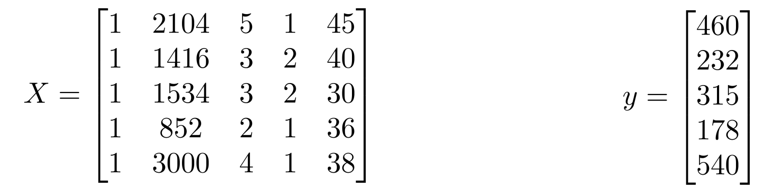
比方说,上图的
x
(
2
)
=
[
1416
3
2
40
]
{x}^{(2)}\text{=}\begin{bmatrix} 1416\\\ 3\\\ 2\\\ 40 \end{bmatrix}
x ( 2 ) = ⎣ ⎢ ⎢ ⎡ 1 4 1 6 3 2 4 0 ⎦ ⎥ ⎥ ⎤
x
2
(
2
)
=
3
,
x
3
(
2
)
=
2
x_{2}^{\left( 2 \right)}=3,x_{3}^{\left( 2 \right)}=2
x 2 ( 2 ) = 3 , x 3 ( 2 ) = 2
支持多变量的假设
h
h
h
h
θ
(
x
)
=
θ
0
+
θ
1
x
1
+
θ
2
x
2
+
.
.
.
+
θ
n
x
n
h_{\theta}\left( x \right)={\theta_{0}}+{\theta_{1}}{x_{1}}+{\theta_{2}}{x_{2}}+...+{\theta_{n}}{x_{n}}
h θ ( x ) = θ 0 + θ 1 x 1 + θ 2 x 2 + . . . + θ n x n
n
+
1
n+1
n + 1
n
n
n
x
0
=
1
x_{0}=1
x 0 = 1
h
θ
(
x
)
=
θ
0
x
0
+
θ
1
x
1
+
θ
2
x
2
+
.
.
.
+
θ
n
x
n
h_{\theta} \left( x \right)={\theta_{0}}{x_{0}}+{\theta_{1}}{x_{1}}+{\theta_{2}}{x_{2}}+...+{\theta_{n}}{x_{n}}
h θ ( x ) = θ 0 x 0 + θ 1 x 1 + θ 2 x 2 + . . . + θ n x n
θ
=
[
θ
0
θ
1
θ
2
.
.
.
θ
n
]
\theta=\begin{bmatrix}{\theta_0}&{\theta_1}&{\theta_2}&{...}&{\theta_n}\end{bmatrix}
θ = [ θ 0 θ 1 θ 2 . . . θ n ] 、
X
=
[
x
0
x
1
x
2
.
.
.
x
n
]
X=\begin{bmatrix}{x_0}&{x_1}&{x_2}&{...}&{x_n}\end{bmatrix}
X = [ x 0 x 1 x 2 . . . x n ]
x
0
=
1
x_0=1
x 0 = 1
n
+
1
n+1
n + 1
n
+
1
n+1
n + 1
X
X
X
m
∗
(
n
+
1
)
m*(n+1)
m ∗ ( n + 1 )
h
θ
(
x
)
=
θ
T
X
h_{\theta} \left( x \right)={\theta^{T}}X
h θ ( x ) = θ T X
T
T
T
在单变量线性回归中
J
(
θ
0
,
θ
1
)
=
1
2
m
∑
i
=
0
m
(
h
θ
(
x
)
−
y
(
i
)
)
2
J(\theta_0,\theta_1)=\frac{1}{2m}\sum_{i=0}^{m}(h_\theta(x)-y^{(i)})^2
J ( θ 0 , θ 1 ) = 2 m 1 ∑ i = 0 m ( h θ ( x ) − y ( i ) ) 2
在多变量线性回归中,我们也构建一个代价函数,则这个代价函数是所有建模误差的平方和,即:
J
(
θ
0
,
θ
1
.
.
.
θ
n
)
=
1
2
m
∑
i
=
1
m
(
h
θ
(
x
(
i
)
)
−
y
(
i
)
)
2
J\left( {\theta_{0}},{\theta_{1}}...{\theta_{n}} \right)=\frac{1}{2m}\sum\limits_{i=1}^{m}{{{\left( h_{\theta} \left({x}^{\left( i \right)} \right)-{y}^{\left( i \right)} \right)}^{2}}}
J ( θ 0 , θ 1 . . . θ n ) = 2 m 1 i = 1 ∑ m ( h θ ( x ( i ) ) − y ( i ) ) 2
其中:
h
θ
(
x
)
=
θ
T
X
=
θ
0
+
θ
1
x
1
+
θ
2
x
2
+
.
.
.
+
θ
n
x
n
h_{\theta}\left( x \right)=\theta^{T}X={\theta_{0}}+{\theta_{1}}{x_{1}}+{\theta_{2}}{x_{2}}+...+{\theta_{n}}{x_{n}}
h θ ( x ) = θ T X = θ 0 + θ 1 x 1 + θ 2 x 2 + . . . + θ n x n
θ
=
[
θ
0
θ
1
θ
2
.
.
.
θ
n
]
\theta=\begin{bmatrix}{\theta_0}&{\theta_1}&{\theta_2}&{...}&{\theta_n}\end{bmatrix}
θ = [ θ 0 θ 1 θ 2 . . . θ n ]
cost function:
J
(
θ
)
=
1
2
m
∑
i
=
1
m
(
h
θ
(
x
(
i
)
)
−
y
(
i
)
)
2
J\left( {\theta}\right)=\frac{1}{2m}\sum\limits_{i=1}^{m}{{{\left( h_{\theta} \left({x}^{\left( i \right)} \right)-{y}^{\left( i \right)} \right)}^{2}}}
J ( θ ) = 2 m 1 i = 1 ∑ m ( h θ ( x ( i ) ) − y ( i ) ) 2
gradient descent:
Repeat{
θ
j
:
=
θ
j
−
α
∂
∂
θ
j
J
(
θ
)
\theta_j:=\theta_j-\alpha\frac{\partial}{\partial\theta_j}J(\theta)
θ j : = θ j − α ∂ θ j ∂ J ( θ )
}
即:
Repeat{
θ
j
:
=
θ
j
−
α
∂
∂
θ
j
1
2
m
∑
i
=
1
m
(
h
θ
(
x
(
i
)
)
−
y
(
i
)
)
2
\theta_j:=\theta_j-\alpha\frac{\partial}{\partial\theta_j}\frac{1}{2m}\sum\limits_{i=1}^{m}{{{\left( h_{\theta} \left({x}^{\left( i \right)} \right)-{y}^{\left( i \right)} \right)}^{2}}}
θ j : = θ j − α ∂ θ j ∂ 2 m 1 i = 1 ∑ m ( h θ ( x ( i ) ) − y ( i ) ) 2
}
求导数后得到:
Repeat{
θ
j
:
=
θ
j
−
α
∂
∂
θ
j
1
m
∑
i
=
1
m
(
h
θ
(
x
(
i
)
)
−
y
(
i
)
)
⋅
x
j
(
i
)
\theta_j:=\theta_j-\alpha\frac{\partial}{\partial\theta_j}\frac{1}{m}\sum\limits_{i=1}^{m}{{{\left( h_{\theta} \left({x}^{\left( i \right)} \right)-{y}^{\left( i \right)} \right)}·x_j^{(i)}}}
θ j : = θ j − α ∂ θ j ∂ m 1 i = 1 ∑ m ( h θ ( x ( i ) ) − y ( i ) ) ⋅ x j ( i )
(simultaneously update
θ
j
\theta_j
θ j
}
我们的目标和单变量线性回归问题中一样,是要找出使得代价函数最小的一系列参数。
当
n
>
=
1
n>=1
n > = 1
θ
0
:
=
θ
0
−
a
1
m
∑
i
=
1
m
(
h
θ
(
x
(
i
)
)
−
y
(
i
)
)
x
0
(
i
)
{{\theta }_{0}}:={{\theta }_{0}}-a\frac{1}{m}\sum\limits_{i=1}^{m}{({{h}_{\theta }}({{x}^{(i)}})-{{y}^{(i)}})}x_{0}^{(i)}
θ 0 : = θ 0 − a m 1 i = 1 ∑ m ( h θ ( x ( i ) ) − y ( i ) ) x 0 ( i )
θ
1
:
=
θ
1
−
a
1
m
∑
i
=
1
m
(
h
θ
(
x
(
i
)
)
−
y
(
i
)
)
x
1
(
i
)
{{\theta }_{1}}:={{\theta }_{1}}-a\frac{1}{m}\sum\limits_{i=1}^{m}{({{h}_{\theta }}({{x}^{(i)}})-{{y}^{(i)}})}x_{1}^{(i)}
θ 1 : = θ 1 − a m 1 i = 1 ∑ m ( h θ ( x ( i ) ) − y ( i ) ) x 1 ( i )
θ
2
:
=
θ
2
−
a
1
m
∑
i
=
1
m
(
h
θ
(
x
(
i
)
)
−
y
(
i
)
)
x
2
(
i
)
{{\theta }_{2}}:={{\theta }_{2}}-a\frac{1}{m}\sum\limits_{i=1}^{m}{({{h}_{\theta }}({{x}^{(i)}})-{{y}^{(i)}})}x_{2}^{(i)}
θ 2 : = θ 2 − a m 1 i = 1 ∑ m ( h θ ( x ( i ) ) − y ( i ) ) x 2 ( i )
…
Python 代码:
def computeCost ( X, y, theta) :
inner = np. power( ( ( X * theta. T) - y) , 2 )
return np. sum ( inner) / ( 2 * len ( X) )
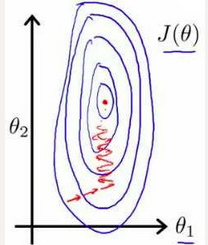
当等高线过于扁时,梯度下降算法需要非常多次的迭代才能收敛。
解决的方法是尝试将所有特征的尺度都尽量缩放到-1到1之间,其中最简单的方法是令:
x
n
=
x
n
−
μ
n
s
n
{{x}_{n}}=\frac{{{x}_{n}}-{{\mu}_{n}}}{{{s}_{n}}}
x n = s n x n − μ n
μ
n
{\mu_{n}}
μ n
s
n
{s_{n}}
s n
例:房屋的尺寸和房间的数量,尺寸的值为 0-2000平方英尺,平均尺寸为1000平方英尺,而房间数量的值则是0-5,平均数目为2个,以两个参数分别为横纵坐标,绘制代价函数的等高线图能,看出图像会显得很扁
其中可得:
x
1
=
s
i
z
e
−
1000
2000
x_1=\frac{size-1000}{2000}
x 1 = 2 0 0 0 s i z e − 1 0 0 0
x
2
=
n
u
m
b
e
r
o
f
b
e
d
r
o
o
m
−
2
5
x_2=\frac{number\ of\ bedroom -2}{5}
x 2 = 5 n u m b e r o f b e d r o o m − 2
梯度下降算法收敛所需要的迭代次数根据模型的不同而不同,我们不能提前预知,但我们可以绘制迭代次数和代价函数的图表来观测算法在何时趋于收敛。
梯度下降算法的每次迭代受到学习率的影响,如果学习率
a
a
a
a
a
a
通常可以考虑尝试些学习率:
α
=
0.01
,
0.03
,
0.1
,
0.3
,
1
,
3
,
10
\alpha=0.01,0.03,0.1,0.3,1,3,10
α = 0 . 0 1 , 0 . 0 3 , 0 . 1 , 0 . 3 , 1 , 3 , 1 0
以房价预测为例,假设房价与临街宽度、纵向深度和占地面积有关,且训练集为下图:
x
1
=
f
r
o
n
t
a
g
e
{x_{1}}=frontage
x 1 = f r o n t a g e
x
2
=
d
e
p
t
h
{x_{2}}=depth
x 2 = d e p t h
x
=
f
r
o
n
t
a
g
e
∗
d
e
p
t
h
=
a
r
e
a
x=frontage*depth=area
x = f r o n t a g e ∗ d e p t h = a r e a
h
θ
(
x
)
=
θ
0
+
θ
1
x
{h_{\theta}}\left( x \right)={\theta_{0}}+{\theta_{1}}x
h θ ( x ) = θ 0 + θ 1 x
则可知可能存在二次方模型:
h
θ
(
x
)
=
θ
0
+
θ
1
x
1
+
θ
2
x
2
2
h_{\theta}\left( x \right)={\theta_{0}}+{\theta_{1}}{x_{1}}+{\theta_{2}}{x_{2}^2}
h θ ( x ) = θ 0 + θ 1 x 1 + θ 2 x 2 2
h
θ
(
x
)
=
θ
0
+
θ
1
x
1
+
θ
2
x
2
2
+
θ
3
x
3
3
h_{\theta}\left( x \right)={\theta_{0}}+{\theta_{1}}{x_{1}}+{\theta_{2}}{x_{2}^2}+{\theta_{3}}{x_{3}^3}
h θ ( x ) = θ 0 + θ 1 x 1 + θ 2 x 2 2 + θ 3 x 3 3
可知不是线性方程,所以我们可以令:
x
2
=
x
2
2
,
x
3
=
x
3
3
{{x}_{2}}=x_{2}^{2},{{x}_{3}}=x_{3}^{3}
x 2 = x 2 2 , x 3 = x 3 3
在计算代价函数
J
(
θ
)
J(\theta)
J ( θ )
易知导数等于0时,代价函数最小。
我们用正规方程计算。正规方程是通过求解下面的方程来找出使得代价函数最小的参数的:
∂
∂
θ
j
J
(
θ
j
)
=
0
\frac{\partial}{\partial{\theta_{j}}}J\left( {\theta_{j}} \right)=0
∂ θ j ∂ J ( θ j ) = 0
假设我们的训练集特征矩阵为
X
X
X
x
0
=
1
{{x}_{0}}=1
x 0 = 1
y
y
y
θ
=
(
X
T
X
)
−
1
X
T
y
\theta ={{\left( {X^T}X \right)}^{-1}}{X^{T}}y
θ = ( X T X ) − 1 X T y T 代表矩阵转置,上标-1 代表矩阵的逆。
其中:
X
=
[
1
x
1
(
1
)
x
1
(
2
)
x
1
(
3
)
⋯
x
1
(
m
)
1
x
2
(
1
)
x
2
(
2
)
x
2
(
3
)
⋯
x
2
(
m
)
1
x
3
(
1
)
x
3
(
2
)
x
3
(
3
)
⋯
x
3
(
m
)
1
⋮
⋮
⋮
⋱
⋮
1
x
n
(
1
)
x
n
(
2
)
x
n
(
3
)
⋯
x
n
(
m
)
]
X=\begin{bmatrix}{1}&{x_{1}^{(1)}}&{x_{1}^{(2)}}&{x_{1}^{(3)}}&{\cdots}&{{x_{1}^{(m)}}}\\{1}&{x_{2}^{(1)}}&{x_{2}^{(2)}}&{x_{2}^{(3)}}&{\cdots}&{{x_{2}^{(m)}}}\\{1}&{x_{3}^{(1)}}&{x_{3}^{(2)}}&{x_{3}^{(3)}}&{\cdots}&{{x_{3}^{(m)}}}\\{1}&{\vdots}&{\vdots}&{\vdots}&{\ddots}&{{\vdots}}\\{1}&{x_{n}^{(1)}}&{x_{n}^{(2)}}&{x_{n}^{(3)}}&{\cdots}&{{x_{n}^{(m)}}}\end{bmatrix}
X = ⎣ ⎢ ⎢ ⎢ ⎢ ⎢ ⎢ ⎡ 1 1 1 1 1 x 1 ( 1 ) x 2 ( 1 ) x 3 ( 1 ) ⋮ x n ( 1 ) x 1 ( 2 ) x 2 ( 2 ) x 3 ( 2 ) ⋮ x n ( 2 ) x 1 ( 3 ) x 2 ( 3 ) x 3 ( 3 ) ⋮ x n ( 3 ) ⋯ ⋯ ⋯ ⋱ ⋯ x 1 ( m ) x 2 ( m ) x 3 ( m ) ⋮ x n ( m ) ⎦ ⎥ ⎥ ⎥ ⎥ ⎥ ⎥ ⎤
y
=
[
y
1
y
2
y
3
⋮
y
n
]
y=\begin{bmatrix}{y_1}\\{y_2}\\{y_3}\\{\vdots}\\{y_n}\\\end{bmatrix}
y = ⎣ ⎢ ⎢ ⎢ ⎢ ⎢ ⎡ y 1 y 2 y 3 ⋮ y n ⎦ ⎥ ⎥ ⎥ ⎥ ⎥ ⎤
正规方程:
θ
=
(
X
(
T
)
X
)
−
1
X
T
y
\theta=({X^{(T)}X})^{-1}X^{T}y
θ = ( X ( T ) X ) − 1 X T y
正规方程
θ
=
(
X
T
X
)
−
1
X
T
y
\theta ={{\left( {X^{T}}X \right)}^{-1}}{X^{T}}y
θ = ( X T X ) − 1 X T y
J
(
θ
)
=
1
2
m
∑
i
=
1
m
(
h
θ
(
x
(
i
)
)
−
y
(
i
)
)
2
J\left( \theta \right)=\frac{1}{2m}\sum\limits_{i=1}^{m}{{{\left( {h_{\theta}}\left( {x^{(i)}} \right)-{y^{(i)}} \right)}^{2}}}
J ( θ ) = 2 m 1 i = 1 ∑ m ( h θ ( x ( i ) ) − y ( i ) ) 2
h
θ
(
x
)
=
θ
T
X
=
θ
0
x
0
+
θ
1
x
1
+
θ
2
x
2
+
.
.
.
+
θ
n
x
n
{h_{\theta}}\left( x \right)={\theta^{T}}X={\theta_{0}}{x_{0}}+{\theta_{1}}{x_{1}}+{\theta_{2}}{x_{2}}+...+{\theta_{n}}{x_{n}}
h θ ( x ) = θ T X = θ 0 x 0 + θ 1 x 1 + θ 2 x 2 + . . . + θ n x n
将向量表达形式转为矩阵表达形式,则有
J
(
θ
)
=
1
2
(
X
θ
−
y
)
2
J(\theta )=\frac{1}{2}{{\left( X\theta -y\right)}^{2}}
J ( θ ) = 2 1 ( X θ − y ) 2
X
X
X
m
m
m
n
n
n
m
m
m
n
n
n
θ
\theta
θ
n
n
n
y
y
y
m
m
m
J
(
θ
)
J(\theta )
J ( θ )
J
(
θ
)
=
1
2
(
X
θ
−
y
)
T
(
X
θ
−
y
)
J(\theta )=\frac{1}{2}{{\left( X\theta -y\right)}^{T}}\left( X\theta -y \right)
J ( θ ) = 2 1 ( X θ − y ) T ( X θ − y )
=
1
2
(
θ
T
X
T
−
y
T
)
(
X
θ
−
y
)
=\frac{1}{2}\left( {{\theta }^{T}}{{X}^{T}}-{{y}^{T}} \right)\left(X\theta -y \right)
= 2 1 ( θ T X T − y T ) ( X θ − y )
=
1
2
(
θ
T
X
T
X
θ
−
θ
T
X
T
y
−
y
T
X
θ
−
y
T
y
)
=\frac{1}{2}\left( {{\theta }^{T}}{{X}^{T}}X\theta -{{\theta}^{T}}{{X}^{T}}y-{{y}^{T}}X\theta -{{y}^{T}}y \right)
= 2 1 ( θ T X T X θ − θ T X T y − y T X θ − y T y )
接下来对
J
(
θ
)
J(\theta )
J ( θ )
d
A
B
d
B
=
A
T
\frac{dAB}{dB}={{A}^{T}}
d B d A B = A T
d
X
T
A
X
d
X
=
2
A
X
\frac{d{{X}^{T}}AX}{dX}=2AX
d X d X T A X = 2 A X
所以有:
∂
J
(
θ
)
∂
θ
=
1
2
(
2
X
T
X
θ
−
X
T
y
−
(
y
T
X
)
T
−
0
)
\frac{\partial J\left( \theta \right)}{\partial \theta }=\frac{1}{2}\left(2{{X}^{T}}X\theta -{{X}^{T}}y -{}({{y}^{T}}X )^{T}-0 \right)
∂ θ ∂ J ( θ ) = 2 1 ( 2 X T X θ − X T y − ( y T X ) T − 0 )
=
1
2
(
2
X
T
X
θ
−
X
T
y
−
X
T
y
−
0
)
=\frac{1}{2}\left(2{{X}^{T}}X\theta -{{X}^{T}}y -{{X}^{T}}y -0 \right)
= 2 1 ( 2 X T X θ − X T y − X T y − 0 )
=
X
T
X
θ
−
X
T
y
={{X}^{T}}X\theta -{{X}^{T}}y
= X T X θ − X T y
令
∂
J
(
θ
)
∂
θ
=
0
\frac{\partial J\left( \theta \right)}{\partial \theta }=0
∂ θ ∂ J ( θ ) = 0
则有
θ
=
(
X
T
X
)
−
1
X
T
y
\theta ={{\left( {X^{T}}X \right)}^{-1}}{X^{T}}y
θ = ( X T X ) − 1 X T y
对于那些不可逆矩阵,正规方程是不可以用的。
梯度下降与正规方程的比较:
梯度下降
正规方程
需要选择学习率
α
\alpha
α
不需要
需要多次迭代
一次运算得出
当特征数量
n
n
n
需要计算
(
X
T
X
)
−
1
{{\left( {{X}^{T}}X \right)}^{-1}}
( X T X ) − 1
O
(
n
3
)
O\left( {{n}^{3}} \right)
O ( n 3 )
n
n
n
适用于各种类型的模型
只适用于线性模型,不适合逻辑回归模型等其他模型
正规方程的python 实现:
import numpy as np
def normalEqn ( X, y) :
theta = np. linalg. inv( X. T@X) @X. T@y
return theta