讲授Boosting算法的原理,AdaBoost算法的基本概念,训练算法,与随机森林的比较,训练误差分析,广义加法模型,指数损失函数,训练算法的推导,弱分类器的选择,样本权重削减,实际应用
AdaBoost算法将用三节课来讲,ANN、SVM、AdaBoost这三种算法都是用三节课来讲,因为这三种算法都非常重要,都有一些成功的应用。AdaBoost和SVM一样整个理论的根基是非常完善的,而且他们都是从1995年左右开始出现,在出现的十几年里边他们都得到了成功的应用。
随即森林它是一种称为Bagging集成学习算法的具体的一种实现,而AdaBoost它是Boosting算法的一种具体的实现。
大纲:
再论集成学习算法
Boosting算法简介
AdaBoost算法简介
训练算法
训练算法的解释
与随机森林的比较
训练误差分析
再论集成学习算法:
集成学习它是整个机器学习里边的一种思想,而不是某一种具体的算法,它有很多种不同的实现,比如说随机森林、AdaBoost,都是集成学习算法具体的实现。
集成学习的精髓:是一种思想,而不是一种具体的算法,有多种不同的实现方案。预测时,依靠多个弱学习器进行预测,投票,加权。训练时,要用原始的训练集构造每个弱学习器的训练集,采样,加权。
典型实现:Bagging与Boosting。
把一些不靠谱精度不是很高的模型,组合起来,能形成一个精度大有提升的一个模型,这是集成学习一个最根本的思想。
Boosting算法简介:
Boosting算法采用了随机采样。
训练算法:每次训练一个弱分类器时,有一部分样本是被上一个弱分类器错分的,这样使得后面的弱分类器重点关注难分的样本。
预测算法:和随机森林是一样的,最后的预测结果是各个弱分类器的预测结果投票。
AdaBoost算法简介:
全称是Adaptive Boosting,自适应提升算法,是一种二分类算法,只能用于分类问题,是Boosting算法的一种实现。
用弱分类器的线性组合来构造强分类器,预测的时候根据强分类器来预测。
弱分类器不用太精确,只要保证准确率大于0.5即可,即比随机猜测要强。
弱分类器的准确率是可以保证的,对于二分类问题,如果准确率低于0.5,只要将预测结果反转即可。
样本标签值为+1和-1。
强分类器: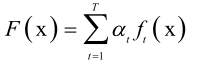 其中,at是一个加权系数,at、ft(x)都是通过训练算法来确定的,T通过实验、人为的经验或其他判断条件来确定的。
其中,at是一个加权系数,at、ft(x)都是通过训练算法来确定的,T通过实验、人为的经验或其他判断条件来确定的。
最后用一个符号函数来做分类 :sgn(F(x)),符号函数,大于0为+1,小于0为-1。
训练算法: