转自:https://www.cnblogs.com/Luv-GEM/p/11598294.html (ok)
1.关系抽取从实现的算法来看,主要分为四种:
1、手写规则(Hand-Written Patterns);
2、监督学习算法(Supervised Machine Learning);
3、半监督学习算法(Semi-Supervised Learning,比如Bootstrapping和Distant Supervision);
4、无监督算法。
2.针对半监督,
Bootstrapping不需要标注好实体和关系的句子作为训练集,不用训练分类器;而Distant Supervision可以看做是Bootstrapping和Supervise Learning的结合,需要训练分类器。
远程监督:
直接从知识图谱中,抽取三元组,并从语料集中抽取包含三元组两个名词中的任意一个的句子,对句中的上下文结构学习,并且给句子打分,设置阈值来判断是否本句属于当前关系类别。
远程监督算法有一个非常重要的假设:对于一个已有的知识图谱(论文用的Freebase)中的一个三元组(由一对实体和一个关系构成),假设外部文档库(论文用的Wikipedia)中任何包含这对实体的句子,在一定程度上都反映了这种关系。
基于这个假设,远程监督算法可以基于一个标注好的小型知识图谱,给外部文档库中的句子标注关系标签,相当于做了样本的自动标注,因此是一种半监督的算法。
具体来说,在训练阶段,用命名实体识别工具,把训练语料库中句子的实体识别出来。如果多个句子包含了两个特定实体,而且这两个实体是Freebase中的实体对(对应有一种关系),那么基于远程监督的假设,认为这些句子都表达了这种关系。于是从这几个句子中提取文本特征,拼接成一个向量,作为这种关系的一个样本的特征向量,用于训练分类器。

从bag-of-words中抽取文本特征,作为关系的特征向量表示。
从多个句子中抽出特征进行拼接,作为某个样本(实体对)的特征向量,有两个好处:
一是单独的某个句子可能仅仅包含了这个实体对,并没有表达Freebase中的关系,那么综合多个句子的信息,就可以消除噪音数据的影响。
二是可以从海量无标签的数据中获取更丰富的信息,提高分类器的准确率。
但是就算一个句子中同时出现了这两个实体对,也可能表达的不是本关系的意思,那么就会产生偏差啊,可能是越来越大的偏差。
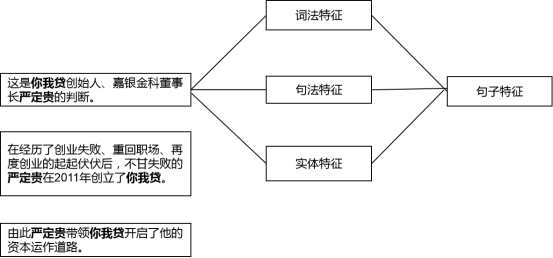
从句子中抽取如上三种特征。
远程监督基于一个非常强的假设,就是只要freebase的关系对中的实体出现在了句子中,就假定实体关系为当前关系。
https://www.jiqizhixin.com/articles/2017-08-31-22
1. 假设过于肯定,难免引入大量的噪声数据。如 "Steven Jobs passed away the daybefore Apple unveiled iPhone 4s in late 2011."这句话中并没有表示出 Steven Jobs 与 Apple 之间存在 founder 的关系。
2. 数据构造过程依赖于 NER 等 NLP 工具,中间过程出错会造成错误传播问题。针对这些问题,目前主要有四类方法:(1)在构造数据集过程中引入先验知识作为限制;(2)利用指称与指称间关系用图模型对数据样例打分,滤除置信度较低的句子;(3)利用多示例学习方法对测试包打标签;(4)采用 attention 机制对不同置信度的句子赋予不同的权值。
3.Freebase介绍
https://developer.aliyun.com/article/717320
Freebase 是一个由元数据组成的大型合作知识库。
- Topic:即实例或实体,每一条信息叫做Topic,比如:姚明等。
- Type:类型或概念,每个Topic可以属于多个Type,比如:人、运动员等。
- Domain:域,对类型的分组,便于schema管理,比如:人物。
- Property:属性,每个Type可以设置多个属性,其值默认可以有多个,可通过设置unique为true限制只能有一个值。比如:出生日期、所在球队等。
属性值类型可以是基本类型,比如:整型、文本等;也可以是另一个type,比如:所在球队、父母等,这种情况叫做CVT,compound value type 组合值类型,比如:所在球队就是一个CVT,它有自身结构化的属性,不仅仅只是一种简单的值。
通过类型及其配置的属性,可结构化一个Topic,如果Topic属于多个Type,则其结构为这些Type属性的集合。如果属性是基本类型则存储在该topic本身;若是CVT则作为另一个topic存储,通过边进行关联。
//听起来就像一个个结构化的数据然后通过属性关联,这样就形成了图。
4.开放领域关系抽取
无需预先定义关系类型,而是直接从开放文本中抽取(s1,p,s2),s为实体,p为动词。(个人理解)
《开放式文本信息抽取 》
开放式实体关系抽取的目标就是突破封闭的关系类型限定以及训练语料的约束,从海量的网络文本中抽取实体关系三元组(Arg1, Pred, Arg2),这里 Arg1 表示实体,Arg2 表示实体关系值,通常也为实体, Pred 表示关系名称,通常为动词、名词或者名词短语。
5.通用模式关系抽取
infobox也是结构化数据,https://zh.wikipedia.org/wiki/Template:Infobox
{{Infobox |name = {{subst:PAGENAME}} |title = 可选顶栏的用例 |header1 = {{#if:{{{item_one|}}}{{{item_two|}}}{{{item_three|}}} |可选顶栏}} |label2 = 项目一 |data2 = {{{item_one|}}} |label3 = 项目二 |data3 = {{{item_two|}}} |label4 = 项目三 |data4 = {{{item_three|}}} }}
需要看一下那篇引用的文章。