这一章,我们要介绍关系抽取的背景,即知道什么是知识图谱--关系抽取,以及相关的基本概述。
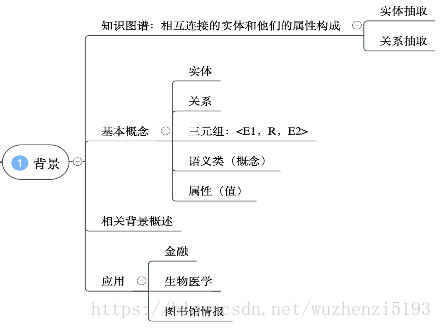
一、知识图谱
介绍关系抽取前,我们需要了解一下什么是知识图谱,知识图谱最早由谷歌提出,初衷是为了让机器具备推理的能力,让它去“理解”语义层面,提供更好的查询
我们最早的搜索,是输入一个查询词,或者一个词的集合,在数据集中进行匹配,分词,将文档集进行排序,然后返回给用户,当时我们觉得他很有用,但是比如说有这么一个问题,我们想要搜索:
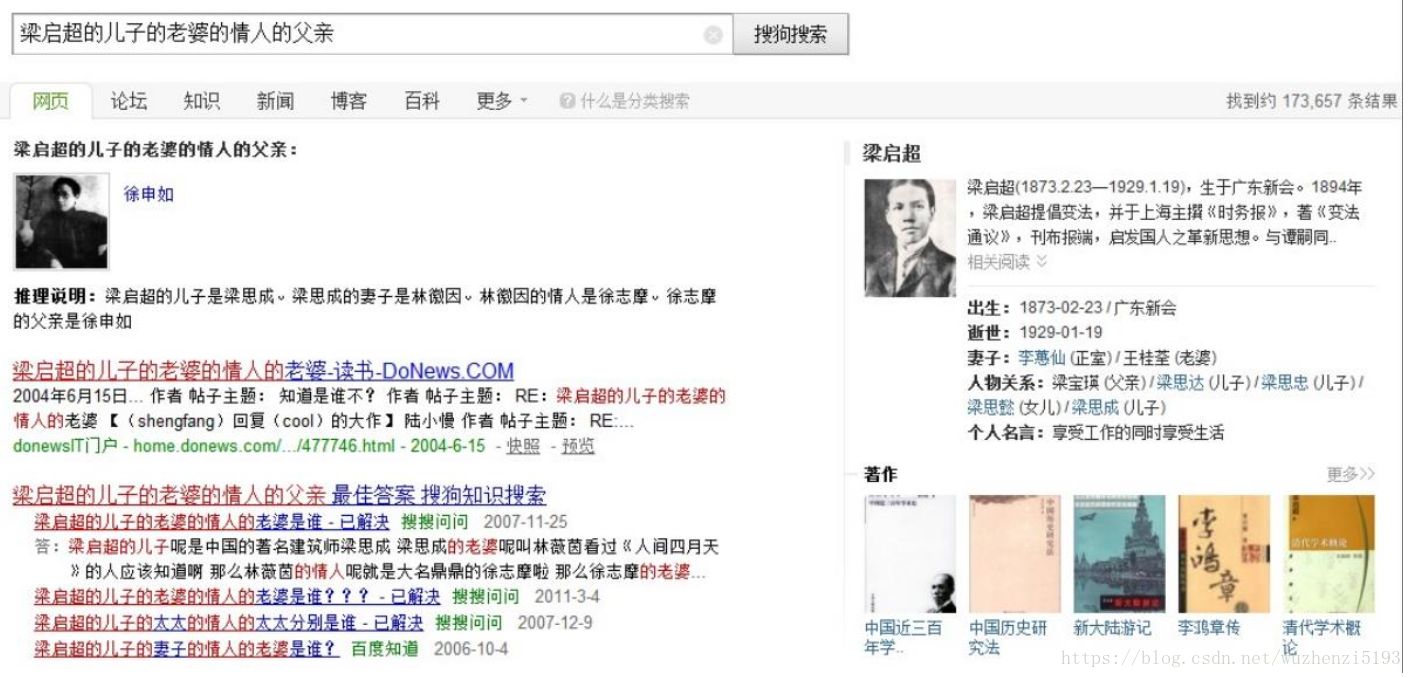
这个问题已经不是以前的关键词匹配所能满足的了,你无法在一篇现有的文章数据中找到这个问题的答案,所以在这个大数据的时代里,我们想要机器去思考语义、推理问题,
再比方说图灵的全名

图灵教育背景

这些都不是返回某篇文档,或者某段话,而是直接将答案返回给我们,就好像你在问一个人,你问他图灵的全名是什么,而不是问一个不会思考的机器,所以我们使用知识图谱希望机器可以思考,可以理解句子
这样,当机器再次被检索到图灵的时候,除了相关网页,还会返回一个“知识卡片”,包含了查询对象的基本信息和其相关的其他对象(艾伦 图灵也简称图灵,在搜索的时候搜索图灵即可获取艾伦图灵的相关内容)。如果我们只是想知道图灵的国籍、年龄、婚姻状况、子女信息,那么我们不用再做多余的操作。在最短的时间内,我们获取了最为简洁,最为准确的信息。这和我们人类看到熟悉的事物,会进行联想和推理一个道理

基于这个知识卡片,我们获得了关于图灵的一系列的知识,我们可以说他像人类一样展开思考,他好像能够理解艾伦图灵与图灵的关系,它能够理解图灵与计算机科学家的联系
所以基于上述因素,我们就得到了知识图谱
A knowledge graph consists of a set of interconnected typed entities and their attributes.
即知识图谱由一些相互连接的实体和他们的属性构成的,里面有更多的知识,知识之间存在联系,存在着思考和联想推理,这种思考其实就是我们经常提到的人工智能,而知识图谱就被誉为人工智能大脑的知识库。

知识图谱综合了众多方面,其中从Web角度看KG,它像建立文本之间的超链接一样,建立数据之间的语义链接,并支持语义搜索。 从NLP角度看,它主要在做怎么能够从文本中抽取语义和结构化的数据。从知识表示角度看是怎么利用计算机符号来表示和处理知识。 从AI角度则是怎么利用知识库来辅助理解人类的语言。 从数据库角度看就是用图的方式存储知识。因此要做好KG要综合利用好KR、NLP、Web、ML、DB等多方面的方法和技术。
二、关系抽取
所以我们自然而然的发现,如果我们想建立这样的一个图谱,我们需要这些圆圈,需要知道这些线上的关联词,知道各种知识的关系,知道他们是不是相关联的,就需要发现“知识”以及知识间的关系,也就是我们称作实体和实体的关系,即知识图谱中的实体抽取和关系抽取。

所以我们可以得到说,关系抽取就是识别出实体和他们之间关系,最终构造出知识图谱来。

最终,我们得到关于关系抽取的定义:

三、关系抽取背景

四、应用
知识图谱在学术界和工业界受到越来越多的关注,现已被广泛应用于智能搜索、智能问答、个性化推荐、内容分发、权限管理,人力资源管理等领域。
针对人工智能领域,知识图谱第一个就是用来搜索,这也是Google提出知识图谱的初衷;第二个就是聊天机器人,第三个就是用来做问答;还有很多私人的助理,比如说苹果手机里的Siri,还有微软的小娜,百度的度秘;同时还有很多的穿戴设备里面也用到了知识图谱相关的技术,比如iWatch;最后一个就是出行的手,国内做的非常好的“出门问问”,它也是用了相关的技术。
接下来我们对各行业中应用做一些简单的描述。
金融行业智能顾投这个听起来非常漂亮,但是目前为止,还很少有成熟的产品出来。国外的kensho做了一些探索,经过我们的分析和学习,应该还远远未达到智能投顾的级别。
生物医学领域还可以做辅助诊疗,即前面提到的IBM Watson, 即根据症状智能开方;同时也可以做相似病例的发现,目前医生在诊断的时候很大程度也是根据历史病例进行参考,因此我们可以利用知识图谱实现相似病例发现。
