参考:https://blog.csdn.net/qq_36426650/article/details/84668741#t6
https://blog.csdn.net/bobobe/article/details/80489303#commentBox
小编也加入了自己的理解
摘要:构建知识图谱包含四个主要的步骤:数据获取、知识抽取、知识融合和知识加工。其中最主要的步骤是知识抽取。知识抽取包括三个要素:命名实体识别(NER)、实体关系抽取(RE) 和 属性抽取。其中属性抽取可以使用python爬虫爬取百度百科、维基百科等网站,操作较为简单,因此命名实体识别(NER)和实体关系抽取(RE)是知识抽取中非常重要的部分,同时其作为自然语言处理(NLP)中最遇到的问题一直以来是科研的研究方向之一。
本文将以深度学习的角度,对命名实体识别和关系抽取进行分析,在阅读本文之前,读者需要了解深度神经网络的基本原理、知识图谱的基本内容以及关于循环神经网络的模型。可参考本人编写的博文:(1)基于深度学习的知识图谱综述;(2)深度神经网络。
本文的主要结构如下,首先引入知识抽取的相关概念;其次对词向量(word2vec)做分析;然后详细讲解循环神经网络(RNN)、长短期记忆神经网络(LSTM)、门控神经单元模型(GRU);了解基于文本的卷积神经网络模型(Text-CNN);讲解隐马尔可夫模型(HMM)与条件随机场等图概率模型(CRF);详细分析如何使用这些模型实现命名实体识别与关系抽取,详细分析端到端模型(End-to-end/Joint);介绍注意力机制(Attention)及其NLP的应用;随后介绍知识抽取的应用与挑战,最后给出TensorFlow源码、推荐阅读以及总结。本文基本总结了整个基于深度学习的NER与RC的实现过程以及相关技术,篇幅会很长,请耐心阅读:
文章目录
一、相关概念
在传统的自然语言处理中,命名实体识别与关系抽取是两个独立的任务,命名实体识别任务是在一个句子中找出具有可描述意义的实体,而关系抽取则是对两个实体的关系进行抽取。命名实体识别是关系抽取的前提,关系抽取是建立在实体识别之后。
1.1 实体与关系
实体是指具有可描述意义的单词或短语,通常可以是人名、地名、组织机构名、产品名称,或者在某个领域内具有一定含义的内容,比如医学领域内疾病、药物、生物体名称,或者法律学涉及到的专有词汇等。实体是构建知识图谱的主要成员。
关系是指不同实体之间的相互的联系。实体与实体之间并不是相互独立的,往往存在一定的关联。例如“马云”和“阿里巴巴”分别属于实体中的人名和机构名,而它们是具有一定关系的。
在命名实体识别和关系抽取之后,需要对所产生的数据进行整合,三元组是能够描述整合后的最好方式。三元组是指(实体1,关系,实体2)组成的元组,在关系抽取任务中,对任意两个实体1和实体2进行关系抽取时,若两者具有关系,则它们可以构建成三元组。例如一句话“马云创办了阿里巴巴”,可以构建的三元组为(“马云”,“创办”,“阿里巴巴”)。
1.2 标注问题
监督学习中有三种问题,分别是分类问题、回归问题和标注问题。分类问题是指通过学习的模型预测新样本在有限类集合中对应的类别;回归问题是指通过学习的模型拟合训练样本,使得新样本可以预测出一个数值;标注问题则是根据输入的序列数据对其用预先设置的标签进行依次标注。
本文的思想便是序列标注,通过输入的序列数据,选择相应的模型对样本进行训练,完成对样本的标注任务。
常用的标注任务包括命名实体识别、词性标注、句法分析、分词、机器翻译等,解决序列标注问题用到的深度学习模型为循环神经网络。
二、序列模型数据
在深度神经网络一文对深度神经网络的分析中已经指出,传统的BP神经网络只能处理长度固定,样本之间相互独立的数据,而对于处理命名实体识别、关系抽取,以及词性标注、情感分类、语音识别、机器翻译等其他自然语言处理的问题中,文本类的数据均以句子为主,而一个句子是由多个单词组成,不同的句子长度不一致,因此对于模型来说,大多数是以单词为输入,而单个词往往没有特定的意义,只有多个词组合在一起才具有一定的含义。例如对于“马云”一词,单个词“马”可能表达的是动物,“云”一词可能表示的是天上飘得云彩,也可以表示“云计算”的云,而“马云”却表示人名。所以这一类数据之间是有关联的。我们对句子级别的数据称为序列模型数据。
对于文本类的序列模型数据,通常是不能直接作为模型的输入数据的,需要进行预处理。
2.1 one-hot向量
将句子中的单词转换为数字的一种方法是采用one-hot向量。例如训练集中有3000个不重复的单词,根据其在词汇表中的排序,可以依次为其编号,例如“a”编号为0,“book”的编号为359,“water”的编号2441。因此这3000个单词都有唯一的编号。
为了能通过向量形式表达,one-hot向量是指除了下标为该单词编号所对应的的值为1以外其他都为0。例如一个集合只有一句话“马云在杭州创办了阿里巴巴”,其中只有11个不重复的词,分别编号0-10,则“马”字的one-hot向量为 [1,0,0,0,0,0,0,0,0,0,0],“阿”字的one-hot向量是[0,0,0,0,0,0,0,0,1,0,0]
one-hot向量能够很清楚得为每一个词进行“数值化表示”,将人理解的内容转换为计算机可以理解的内容。
Ps:有关onehot向量的详解:OneHot编码知识点,数据预处理:独热编码(One-Hot Encoding)
2.2 词嵌入向量(word embeddings)
one-hot向量虽然能够简单的表示一个词,但是却存在三个问题:
(1)one-hot向量是稀疏向量,并不能存储相应的信息;
(2)当语料库中包含的词汇很多时(上百万上千万),一个one-hot向量的维度将会很大,容易造成内存不足;
(3)序列模型的数据需要能够体现出词语词之间的关联性,单纯的one-hot向量不能体现出关联性。例如对于词汇“good”和“well”都表示不错的意思,再某些程度上具有相似关联,而one-hot只是简单的编号,并未体现这层相似性。
因此,为了解决one-hot带来的问题,引入词向量概念。
词向量有许多种表达方式,传统的方法是统计该词附近的词出现的次数。基于深度学习的词向量则有word embeddings,其是通过谷歌提出的word2vec方法训练而来。
word2vec方法是将高维度的one-hot向量进行降维,通常维度设置为128或者300,其通过神经网络模型进行训练。基于神经网络的词向量训练有两种模型,分别是CBOW和Skip-Gram模型,如下图。


(1)CBOW模型是将一个词所在的上下文中的词作为输入,而那个词本身作为输出。通常设置一个窗口,不断地在句子上滑动,每次滑动便以窗口中心的词作为输出,其他词作为输入。基于大量的语句进行模型训练,通过神经网络的梯度下降法进行调参。最终神经网络的权重矩阵即为所有词汇的word embeddings。
(2)Skip-Gram模型与CBOW相反,其随机选择窗口内的一个词的one-hot向量作为输入,来预测其他所有词可能出现的概率,训练后的神经网络的权重矩阵即为所有词汇的word embeddings。
word2vec对训练好的神经网络,需要通过遍历所有词汇表抽取出所有词汇的word embedding,常用的优化模型是哈弗曼树(Hierarchical Softmax)和负采样(Negative Sampling)。
Ps:关于word2vec训练详细解读可参考:如果看了此文还不懂 Word2Vec,那是我太笨,Word Embedding与Word2Vec;关于word2vec的模型优化可参考基于Hierarchical Softmax的模型概述,基于Negative Sampling的模型概述。
三、循环神经网络
循环神经网络是BP神经网络的一种改进,其可以完成对序列数据的训练。根据前面讲解内容,循环神经网络需要能够记住每个词之间的关联性,因为每个词可能会受到之前的词的影响。
3.1 循环神经网络的结构
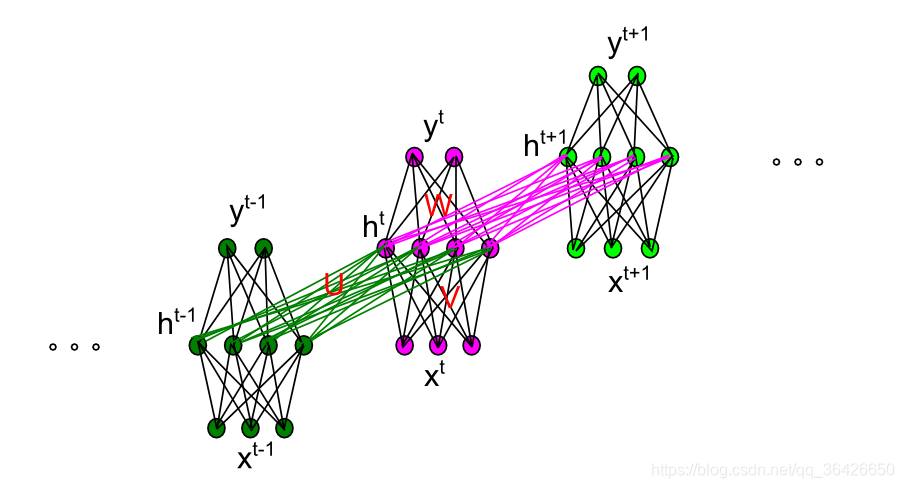
循环神经网络与BP神经网络不同之处在于其隐含层神经元之间具有相互连接。循环神经网络是基于时间概念的模型,因此对于横向的连接每一个神经元代表一个时间点。模型如图所示:

对于时刻 t时刻的输入为
, 即为一个word embedding,输入到中心圆圈(隐层状态神经元)的箭头表示一个神经网络,权重矩阵为U,偏向为 b,对于时间 t-1时刻,中心的圆圈已经存在一个值
该圆圈与t时刻的圆圈的箭头也表示一个神经网络,其权重矩阵为W,偏向也为b。循环神经网络的关键即为某一时刻 t的隐层状态神经元的值不仅取决于当前的输入,也取决于前一时刻的隐层状态,即为:
其中f(·)表示激活函数。
对于网络的输出部分,循环神经网络输出个数与输入数量一致,时刻 t 的输出为:
由于对于序列模型来说,数组的长度是不一致的,即循环神经网络的输入神经元长度是不确定的,因此各个神经网络采用了共享参数 W,U,V,b和c
循环神经网络的剖面图如下图,该图能够比较直观的认识循环神经网络的空间结构(图片为转载,可忽略里面的参数):
3.2 循环神经网络的训练
循环神经网络的训练与传统的BP神经网络训练方法一样,分为前向传播和反向传播,前向传播的公式为:
假设损失函数为 L。反向传播采用BPTT(基于时间的反向梯度下降)算法计算各个参数的梯度。输出层的神经网络梯度下降与BP神经网络的一样。而对于隐含层状态神经元部分,由于其在前向传播过程中的值来自于两个方向,同时又流向另外两个方向,因此在反向传播过程中,梯度将来自当前时刻的输出和下一时刻的状态,同时梯度流向该时刻的输入和上一时刻的状态,如图

因此,假设时间长度为 n,对于某一时刻 t(0<t<n),隐层状态神经元的梯度将是不断累加的。下面给出循环神经网络的参数 W,U,V,b,c的梯度:
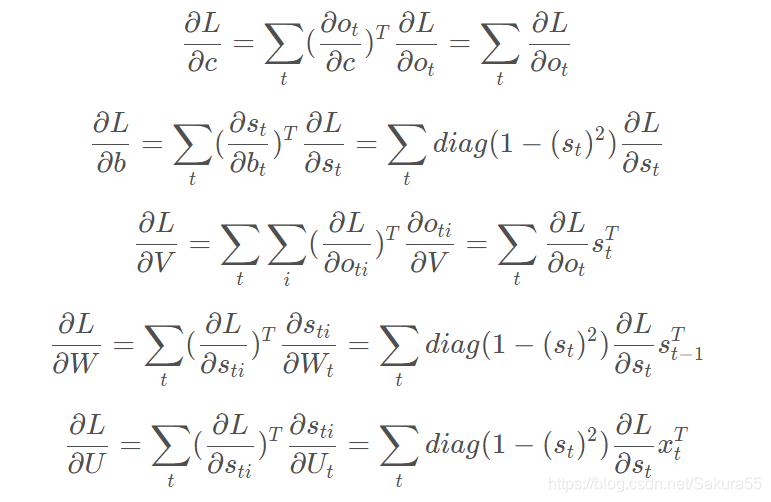
由于循环神经网络的共享参数机制,使得网络可以用很少的参数来构建一个大的模型,同时减少了计算梯度的复杂度。
Ps:关于BPTT算法详细推导,可参考博文:基于时间的反向传播算法BPTT(Backpropagation through time),书籍:人民邮电出版社的《深度学习》233页。
3.3 其他类型的循环神经网络
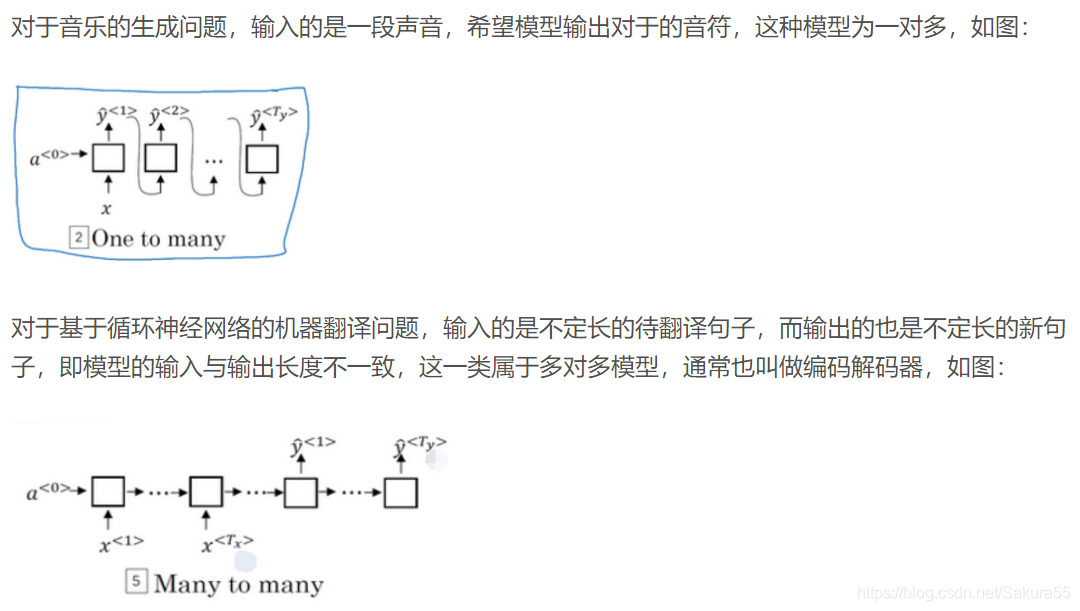
上述的循环神经网络结构是标准的模型,对于不同的应用会产生不同的模型。在基于循环神经网络的情感分类问题中,模型的输入是长度不一的句子,而模型的输出往往只有一个(是积极的还是消极的评论),因此这属于多对一模型,如图:
3.4 双向循环神经网络
在命名实体识别问题中,输入的数据是一个句子,往往一个句子中的词不仅受到前面词的影响,同时也可能受到后面的词的影响,例如句子“王小明是班级上学习最好的同学”中之所以可以识别出人名实体“王小明”,是因为其后的关键词“同学”,而该实体前面没有词可以提供识别的依据。普通的循环神经网络仅考虑了前一时刻的影响,却未考虑后一时刻的影响,因此需要引入了双向循环神经网络模型。
双向循环神经网络的结构如下:

其由输入层、前向隐含层、后向隐含层和输出层组成。输入层输入序列数据,前向隐含层的状态流向是顺着时间,后向隐含层的状态流向是逆着时间的,因此前向隐含层可以记住当前时刻之前的信息,而后向隐含层可以记住当前时刻未来的信息。通过输出层将前向、后向隐含层的向量进行拼接或者求和。
双向循环神经网络的前向传播式子为:
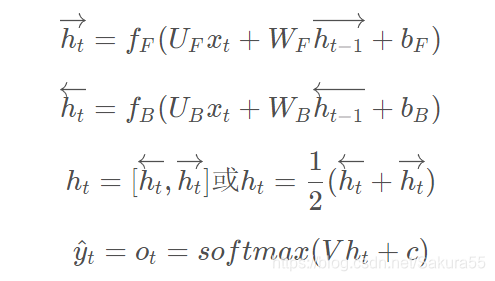
双向循环神经网络的梯度下降法仍然使用BPTT算法,对于前向和后向隐含层,梯度的流向是互不干扰的,因此可以用普通的循环神经网络梯度下降的方法对前向和后向分别计算。
3.5 深度循环神经网络
循环神经网络的结构还是属于浅层模型,可以观察其结构图,只有两层网络组成。为了提高模型的深度,一种深度循环神经网络被提出,其结构如图所示:
深度循环神经网络:
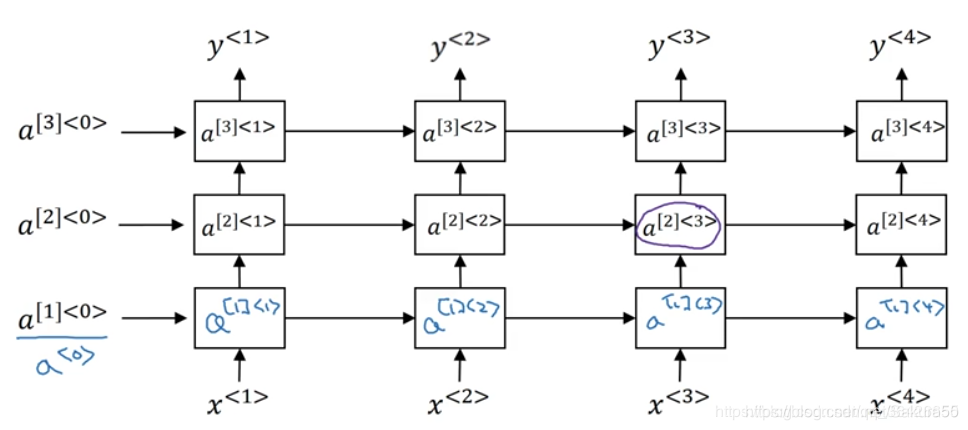
可知每一层便是一个循环神经网络,而下一层的循环神经网络的输出作为上一层的输入,依次进行迭代而成。
深度循环神经网络的应用范围较少,因为对于单层的模型已经可以实现对序列模型的编码,而深层次模型会造成一定的过拟合和梯度问题,因此很少被应用。
四、循环神经网络的缺陷
在命名实体识别任务中,通过训练循环神经网络模型,实体识别的精度往往可以达到60%-70%,同时以其共享参数的机制,构建一个较大的循环神经网络不需要像BP网络那样需要庞大的参数,因此模型的训练效率也大大提高。
但是循环神经网络有两个致命的缺陷,在实验中经常遇到:
**(1)容易造成梯度爆炸或梯度消失问题。当序列长度为100时,第1个输入的梯度在传递100层之后,可能会导致指数上升或者指数下降。
(2)对于较长的序列,模型无法能够长期记住当前的状态。**例如对于句子“这本书,名字叫平凡的世界,白色封皮,有一个书签夹在里面,旁边放着一支笔,…,是我的”,若要提取出有效的信息“这本书是我的”,需要长久的记住“这本书”,直到遇到“是我的”为止,而对于省略号完全可以无限的长。因此普通的循环神经网络无法记住这么久。
因此为了解决这两个问题,需要对循环神经网络做出改进,使得其能够长期记住某一状态。
五、长短期记忆神经网络(LSTM)与门控神经单元(GRU)
链接:https://blog.csdn.net/Sakura55/article/details/81537498
隐含层的部分又称为LSTM单元,如图:
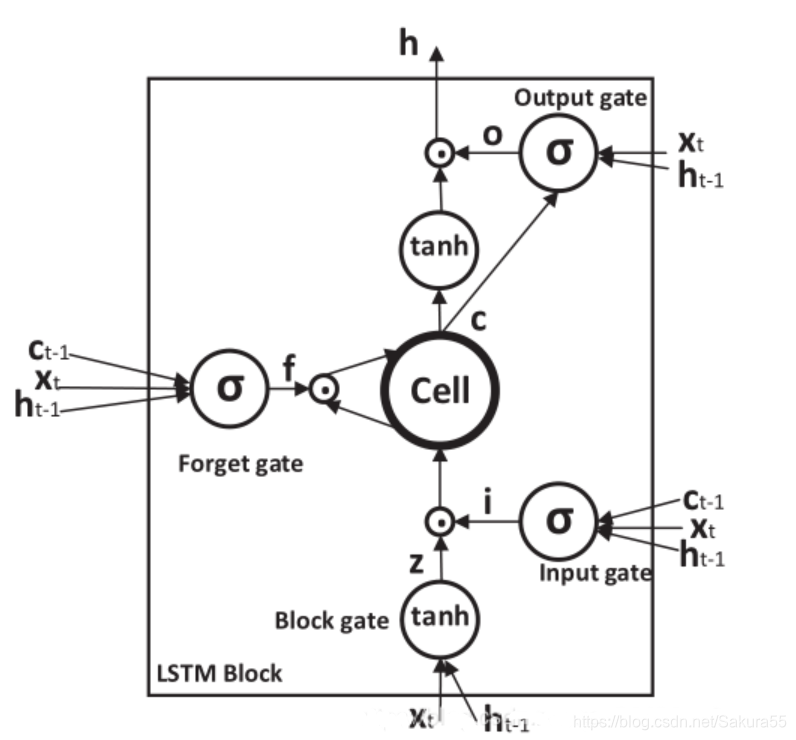
5.1、LSTM-GRU
这里有必要详细讲解一下内部的操作算法:



5.2 双向长短期记忆神经网络(Bi-LSTM)
与循环神经网络一样,单向的模型不能够记住未来时刻的内容,因此采用双向模型,双向模型如图所示:
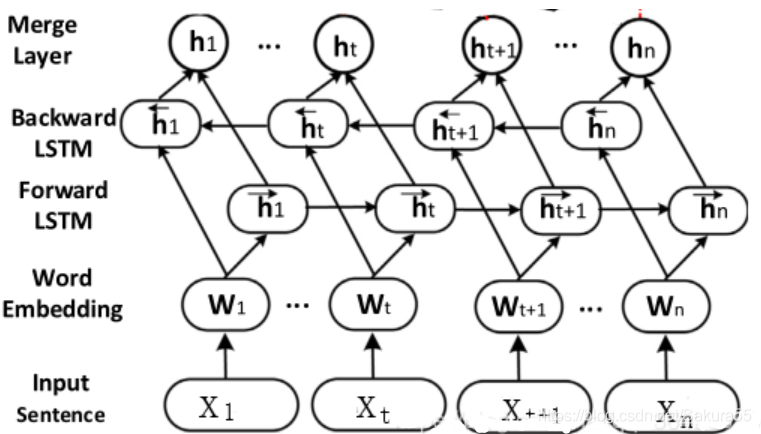
Bi-LSTM的结构与Bi-RNN模型结构一样。同一时刻在隐含层设置两个记忆单元(LSTM unit),分别按照顺时间(前向)和逆时间(后向)顺序进行记忆,最后将该时刻两个方向的输出进行拼接,即:
在诸多学术论文中,对命名实体识别最常用的便是Bi-LSTM模型,该模型实体识别的精度通常高达80%。
六、概率图模型概念
具体细节可以查看原作者的第七节:概率图模型概念
七、运用Bi-LSTM和CRF实现命名实体识别
BiLSTM+softmax
lstm也可以做序列标注问题。如下图所示:
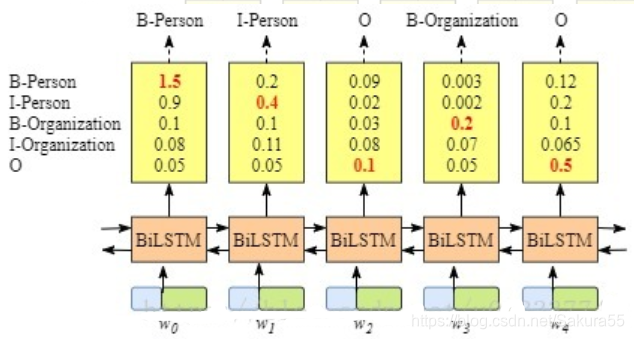
双向lstm后接一个softmax层,输出各个label的概率。那为何还要加一个crf层呢?
我的理解是softmax层的输出是相互独立的,即虽然BiLSTM学习到了上下文的信息,但是输出相互之间并没有影响,它只是在每一步挑选一个最大概率值的label输出。这样就会导致如B-person后再接一个B-person的问题。而crf中有转移特征,即它会考虑输出label之间的顺序性,所以考虑用crf去做BiLSTM的输出层。
BiLSTM+crf的基本思想
BiLSTM+crf的结构如图所示:

7.1 数据获取与处理
数据集可以采用自定义标注的数据,但这一类数据往往会存在很多缺陷,因此,在实验中通常使用公开训练集。
常用的公开训练集有ACE04,ACE05,可以用来完成词性标注(命名实体识别便属于一种词性标注问题)。训练集中包含成千上万个完整的句子,主要以英文句子为主。对于词性标注问题,还将对于一个标注序列。数据通常是以JSON格式保存,在读取数据时需要进行JSON解析。
获取数据后,该数据不能直接作为计算机的输入,需要转化为词向量。词向量可以用自己的语料库使用神经网络(CBOW或Skip-Gram模型)进行训练。实验常用谷歌训练好的词向量,其包含了上千万个语料库,相比自己训练的更加完善。
下面以一句话“马云在杭州创办了阿里巴巴”为例,分析Bi-LSTM+CRF实现命名实体识别的训练与预测过程。实体给定范围的JSON表示为:
{
‘o’:0,
‘B-PER’:1,
‘I-PER’:2,
‘B-LOC’:3,
‘I-LOC’:4,
‘B-ORG’:5,
‘I-ORG’:6
}
该句子每个字对于的语料库(假设共3000字)中的编号假设为:
{
‘马’ : 1683,
‘云’ : 2633,
‘在’ : 2706,
‘杭’ : 941,
‘州’ : 2830,
‘创’ : 550,
‘办’ : 236,
‘了’ : 1436,
‘阿’ : 1,
‘里’ : 1557,
‘巴’ : 213,
}
因此该句子的one-hot向量应该为:{1683,2633,2706,941,2830,550,236,1436,1,1557,213}。其次将该one-hot向量与词嵌入矩阵word embeddings相乘,得到该句子每个字对于的词向量,因此该句子将得到一个句子向量,用 x xx 表示,假设word embedding对每个词的维度为300(通常实验都设定为300),则 x xx 的长度也为300。
Ps:通常在训练数据集时,假设一个数据集中有1000个句子,通常采用的是mini-batch法进行训练,即将1000个句子分为若干组(假设分为10组),则每组将平均随机分到batch_size个句子(即每组100个句子),其次将这一组内的句子进行合并。因为每个句子长度不一致,所以取最长的句子为矩阵的列数,其他句子多余的部分则填充0。
7.2 LSTM单元编码
获取该句子的向量后,便将其放入LSTM的的输入层(论文中也多称为input layer或者embedding layer),每个输入神经元对应一个字的词向量,正向传播则从第一个字“马”开始,随着时间推移一直到“巴”。
每个时刻 t对于的字
通过前向传播和后向传播并拼接得到
,其次得到
,该值即为当前时刻 t tt 对应的7个标签中每个标签预测的概率。例如对于“马”字,
=[0.031,0.305,0.219,0.015,0.129,0.133,0.168] ,最大的值为0.305,对应于下标1,即标签“B-PER”。
7.3 CRF解码
在CRF中要解决的问题之一是解码问题,对于
的结果不一定完全符合输出规则,因此需要将其按照输出规则进行解码。输出规则则体现在CRF中的超参数和参数。例如对于 t=5 t=5t=5 时刻,字为“州”,对应的
=[0.085,0.113,0.153,0.220,0.207,0.108,0.114] ,可知最大的值对应下标表示的标签为“B-LOC”,虽然成功的预测了其属于地区这一类实体,但很显然应该是“I-LOC”。因此将该输出概率向量做下列计算:
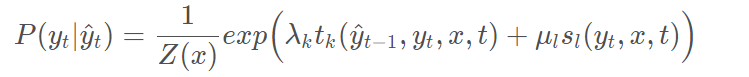
然后对其他词按照该式子进行计算,通过维特比算法求出最大值,即对应的序列中,“州”字的概率向量可能变为:
=[0.085,0.113,0.153,0.207,0.220,0.108,0.114] 。
应用Bi-LSTM和CRF模型的命名实体识别在论文《Bidirectional LSTM-CRF Models for Sequence Tagging》中被提出,可参考该论文,点击一键下载。
八、基于文本的卷积神经网络(Text-CNN)的关系抽取
8.1 Text-CNN的结构
原理:https://blog.csdn.net/Sakura55/article/details/86488691
8.2 Text-CNN应用于关系抽取

九、基于依存关系模型的关系抽取
卷积神经网络可以很好的对实体与实体关系进行分类,而在自然语言处理中,通常会对句子进行句法分析,通过不同语言的语法规则建立起模型——依存关系。基于依存关系的关系抽取是该模型的一个应用方向,其主要是通过句法分析实现,而不是通过深度模型自动挖掘。本文虽然主要是以深度学习角度分析,但传统的“浅层态”模型也需要了解,以方便将其与深度模型进行整合。
9.1依存句法分析
基于依存关系模型的关系抽取也叫做开放式实体关系抽取,解决关系抽取的思路是对一个句子的词性进行预处理,例如对于一句话“马云在杭州创办了阿里巴巴”。不同于之前所讲的深度模型,词性分析则是对该句话中每一个词进行预先标注,例如“马云”、“杭州”和“阿里巴巴”被标记为名词,“在”和“了”被标记为介词,“创办”被标记为动词。所谓的依存关系则体现在不同词性的词之间存在着依存关系路径。“在”通常后面跟着地名,也就是名词,“创办”动词前通常为名词,而“在…创办了”便是一个依存关系。因此依存关系即为不同词性的词之间的关系结构,下标列出了关于中文的依存标注:
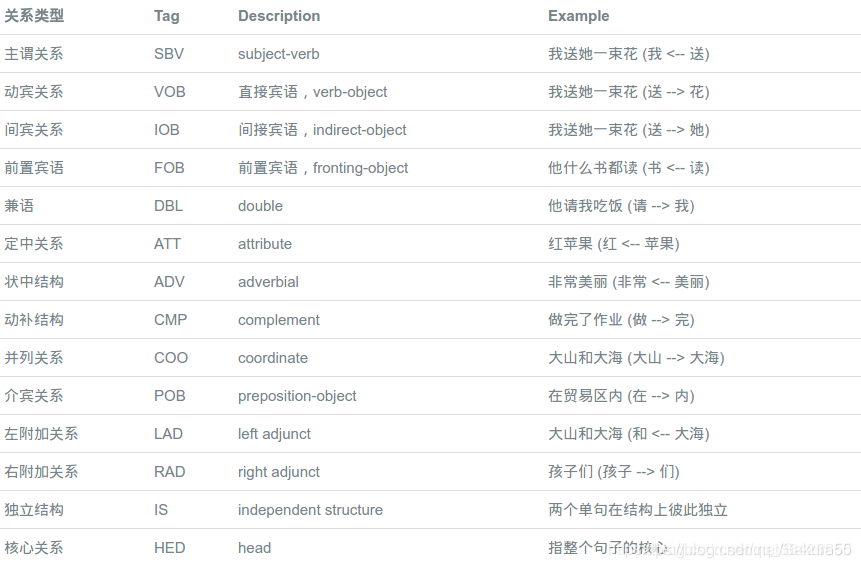
例如对于一句话“国务院总理李克强调研上海外高桥时提出,支持上海积极探索新机制。”,句子开头设置一个“ROOT”作为开始,句子结束则为句号“。”,依存关系可以表示为下图:

在传统的实体识别中,是通过基于规则的词性分析实现的,最简单的是正则表达式匹配,其次是使用NLP词性标注工具。通常认为名词是实体,因此实体可以通过词性标注实现抽取。因为词性对每一个词进行了标注,自然根据语法规则可以构建起上图所示的依存关系。每一个词根据语法规则构建起一条关系路径。所有路径的最终起始点即为句子的核心(HED)。
例如对上述的例句进行分析,“国务院总理李克强”包含三个名词,根据上表可查名词的组合为定中关系,前一个名词作为定于修饰后一个名词,因此“国务院总理李克强”的核心名词因为“李克强”,而“国务院”和“总理”是修饰“李克强”的,因此这三个词生成了依存路径类型被标注为ATT。同理“上海外高桥”也存在ATT类型的依存路径。“时”作为状态词,在动词前做时间状语,因此“调研…时”是“提出”的时间状语,虽然“上海外高桥”是名词,但其存在状语结构中,不可能是状语后面动词的主语,因此可以根据路径看出“提出”的主语不是“上海外高桥”,而是状语前的名词“国务院总理李克强”的核心词“李克强”。对于后半句“支持上海积极探索新机制”,可知“新”和“机制”是ATT关系,因此核心词为“机制”,其前面的动词“探索”则与“机制”组成动宾结构VOB,“积极”作为副词是修饰动词“探索”,则“支持上海积极探索新机制”可简化为“支持上海探索机制”,构成“动词+名词+动词+名词”结构,因此机制是后半句的核心词,“上海”只是间接宾语。经过分析,整句话则表达的含义是“李克强提出支持探索新机制”,类似于语文里的缩句。
9.2 依存句法分析实现关系抽取
对于关系抽取问题,基于依存关系的关系抽取模型中,关系词并非是预先设置的类别,而是存在于当前的句子中。例如“马云在杭州创办了阿里巴巴”,预定义的关系可能是“创始人”,而“创始人”一词在句子中不存在,但是句中存在一个与其相似的词“创办”。因此在句法分析中,能够提取出核心词“创办”,该词前面有一个名词“杭州”,而“杭州”前面有一个介词“在”,因此“在杭州”是一个介宾短语,依存路径被标记为POB,所以“杭州”不是“创办”的主语,自然是“马云”。“创办”一词后面是助词“了”可以省略,再往后则是名称“阿里巴巴”,因此“创办阿里巴巴”为动宾关系VOB,与上面的“探索机制”一样。因此可分析得到语义为“马云创办阿里巴巴”,核心词“创办”即为关系,“马云”和阿里巴巴则是两个实体。
因此基于依存关系的关系抽取算法步骤如下:
(1)获取句子 x xx;
(2)对句子 x xx 进行词性标注;
(3)构建依存关系路径,并依据依存标注表对路径进行标注;
(4)提取核心词;
(5)构建起动宾结构,以核心词为关系寻找主语和宾语作为两个实体。
可以发现,基于依存关系不仅可以抽取关系,也可以提取出其对应的实体。因此包括基于深度学习模型在内,一种端到端的联合实体识别与关系抽取被提出。