1. k近邻(knn)
1.1 步骤:
1.随机选择k个样本作为初始均值向量;
2.计算样本到各均值向量的距离,把它划到距离最小的簇;
3.计算新的均值向量;
4.迭代,直至均值向量未更新或到达最大次数。
优点:
- 原理比较简单,实现也是很容易;
- 算法的可解释度比较强;
- 调参方便,参数仅仅是簇数k。
缺点:
- 聚类中心的个数K 需要事先给定,交叉验证;
- 数据不平衡,或者非凸数据聚类效果差;
- 对噪音和异常点比较的敏感。
1.2 k如何选择
- 方法1: k-means++, 轮盘法选择距离较远的点

- 方法2: 选用层次聚类进行出初始聚类,然后从k个类别中分别随机选取k个点。
1.3 大数据情形
mini batch k-means

1.4 knn和k-Means
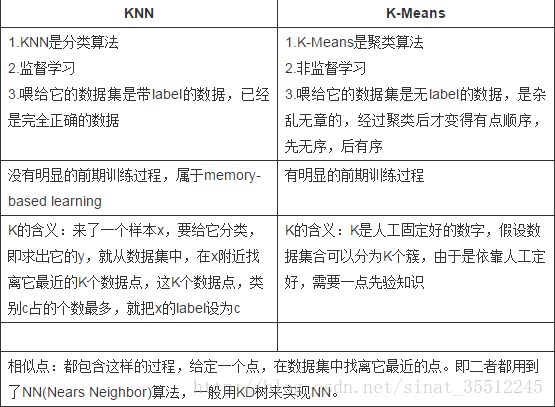
2. DBSCAN
步骤:
1、找到任意一个核心点,对该核心点进行扩充;
2、扩充方法是寻找从该核心点出发的所有密度相连的数据点;
3、遍历该核心的邻域内所有核心点,寻找与这些数据点密度相连的点。
相应概念:
邻域:对于任意样本i和给定距离e,样本i的e邻域是指所有与样本i距离不大于e的样本集合;
核心对象:若样本i的e邻域中至少包含MinPts个样本,则i是一个核心对象;
密度直达:若样本j在样本i的e邻域中,且i是核心对象,则称样本j由样本i密度直达;
密度可达:对于样本i和样本j,如果存在样本序列p1,p2,...,pn,其中p1=i,pn=j,并且pm由pm-1密度直达,则称样本i与样本j密度可达;
密度相连:对于样本i和样本j,若存在样本k使得i与j均由k密度可达,则称i与j密度相连

优点:
- 不需要确定要划分的聚类个数;
- 抗噪声,在聚类的同时发现异常点,对数据集中的异常点不敏感;
- 处理任意形状和大小的簇,可以用于凸数据集。
缺点:
- 数据量大时内存消耗大,相比K-Means参数多一些;
- 样本集的密度不均匀、类间距很大时,聚类质量较差;
3. mean-shift

