实例介绍
目的:获取某种类别商品的信息,提取商品的名称与价格
可行性分析
1.查看淘宝的robots协议,附网址https://www.taobao.com/robots.txt

查看发现淘宝不允许任何人对淘宝信息进行爬取。那么作为一名守法公民为了不要引起不必要的麻烦,
一,不要爬取,二,爬取的程序不要做任何商业用途,仅仅只能用作技术学习。
程序结构
1.请求搜索商品,循环获取页面
2.解析页面内容,获取商品价格名称
3.输出获得的信息
结构分析
查看商品的数量,比如,我要查看卫衣
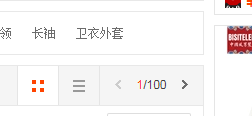
显示了一百页,那么我们查看时就要考虑查看多少了,如果是一页,就只需要爬取一个链接里的信息,
如果要爬取多个页面的信息,就需要多个链接了,这时就需要找到链接之间的关系。
第一个页面的URL:
https://s.taobao.com/search?initiative_id=tbindexz_20170306&ie=utf8&spm=a21bo.2017.201856-taobao-item.2&sourceId=tb.index&search_type=item&ssid=s5e&commend=all&imgfile=&q=卫衣&suggest=history_1&_input_charset=utf8&wq=&suggest_query=&source=suggest&bcoffset=6&ntoffset=6&p4ppushleft=1%2C48&s=0
第二个页面的URL:
https://s.taobao.com/search?initiative_id=tbindexz_20170306&ie=utf8&spm=a21bo.2017.201856-taobao-item.2&sourceId=tb.index&search_type=item&ssid=s5e&commend=all&imgfile=&q=卫衣&suggest=history_1&_input_charset=utf8&wq=&suggest_query=&source=suggest&bcoffset=3&ntoffset=3&p4ppushleft=1%2C48&s=44
第二个页面的URL:
https://s.taobao.com/search?initiative_id=tbindexz_20170306&ie=utf8&spm=a21bo.2017.201856-taobao-item.2&sourceId=tb.index&search_type=item&ssid=s5e&commend=all&imgfile=&q=卫衣&suggest=history_1&_input_charset=utf8&wq=&suggest_query=&source=suggest&bcoffset=0&ntoffset=6&p4ppushleft=1%2C48&s=88
连续查看三个页面的URL后发现,每个URL尾部s以44递增。找到规律后,就可以用循环语句进行页面请求了。
实例编写
1 import requests 2 import re 3 4 def getHTMLText(url): 5 try: 6 r = requests.get(url,timeout = 30) 7 r.raise_for_status() 8 r.encoding = r.apparent_encoding 9 return r.text 10 except: 11 return "" 12 def parsePage(ilt,html): 13 #正则表达式获取商品名称和商品价格 14 try: 15 #使用正则表达式,\表示引入一个"view_price"的键,后面\引入键的值 16 plt = re.findall(r'\"view_price\"\:\"[\d\.]*\"',html) 17 #*?表示最小匹配 18 tlt = re.findall(r'\"raw_title\"\:\".*?\"',html) 19 for i in range(len(plt)): 20 price = eval(plt[i].split(":")[1]) 21 title = eval(tlt[i].split(":")[1]) 22 ilt.append([price,title]) 23 except: 24 print(" ") 25 def printGoodslist(ilt): 26 tplt = "{:4}\t{:8}\t{:16}" 27 print(tplt.format("序号","价格","商品名称")) 28 count = 0 29 for x in ilt: 30 count = count + 1 31 print(tplt.format(count,x[0],x[1])) 32 def main(): 33 goods = '卫衣' 34 depth = 2 35 star_url = 'https://s.taobao.com/search?q=' +goods 36 infoList = [] 37 for i in range(depth): 38 try: 39 url = star_url + '&s=' + str(44*i) 40 html = getHTMLText(url) 41 parsePage(infoList,html) 42 except: 43 continue 44 printGoodslist(infoList) 45 main()
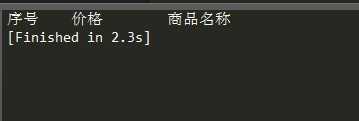
编译运行后发现程序并没有报错,但没有出现商品的输出信息,着实让人摸不着头脑。于是在百度帮助下,
我先是检查自己的URL是不是正确的,复制程序中的URL在浏览器打开,发现可以进入淘宝,URL是正确的。
不是URL的问题,那就是淘宝的问题了,原来淘宝设置反爬虫机制,需要用户登录验证。爬取时需要模拟浏
览器登录才能获取信息。
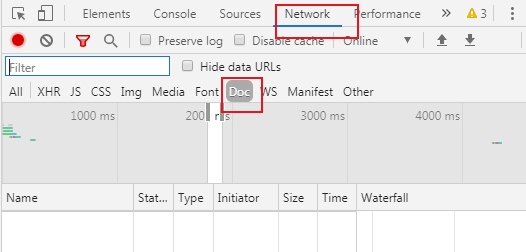
1.浏览器打开淘宝,登录
2.搜索框搜索自己想要爬取的东西,例如卫衣,按F12打开开发者工具
3.选中网络,再选中doc文件
4.回到淘宝首页,开发者工具不要关闭!
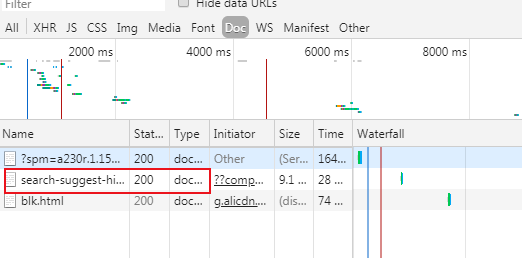
刷新出如图的一个文件
5.打开文件,找到cookie和user-agent,将里面的内容完全复制下来
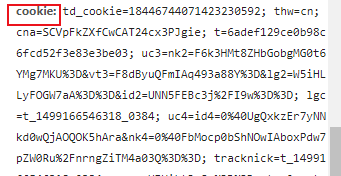
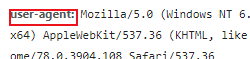
最后在原来的代码写一个headers字典模拟浏览器请求访问,放入刚才复制的cookie和user-agent
全代码:
1 import requests 2 import re 3 4 def getHTMLText(url): 5 headers={'cookie':'td_cookie=18446744071423230592; thw=cn; v=0; cna=SCVpFkZXfCwCAT24cx3PJgie; t=6adef129ce0b98c6fcd52f3e83e3be03; cookie2=7de44eefb19e3e48e25b7349163592b7; _tb_token_=f1fae43e5e551; unb=3345403123; uc3=nk2=F6k3HMt8ZHbGobgMG0t6YMg7MKU%3D&vt3=F8dByuQFmIAq493a88Y%3D&lg2=W5iHLLyFOGW7aA%3D%3D&id2=UNN5FEBc3j%2FI9w%3D%3D; csg=07879b0c; lgc=t_1499166546318_0384; cookie17=UNN5FEBc3j%2FI9w%3D%3D; dnk=t_1499166546318_0384; skt=759aebdc118b2fc5; existShop=MTU3NTEwNzAyMg%3D%3D; uc4=id4=0%40UgQxkzEr7yNNkd0wQjAOQOK5hAra&nk4=0%40FbMocp0bShNOwIAboxPdw7pZW0Ru%2FnrngZiTM4a03Q%3D%3D; tracknick=t_1499166546318_0384; _cc_=UIHiLt3xSw%3D%3D; tg=0; _l_g_=Ug%3D%3D; sg=439; _nk_=t_1499166546318_0384; cookie1=B0TwtzQNNmewbhSpcaaRe7U24nc6DXOpwhexZLEN8Zo%3D; mt=ci=0_1; _m_h5_tk=ec0a32b82d6a8d5c46fe6f873373169b_1575114952532; _m_h5_tk_enc=cfea89ad4f02b520c3a094931d00e376; enc=CnjhIlaGaoA3J%2FSi2PeXU8%2FNC4cXQUAZjulyZI%2Bd9Z8JjGflldsE%2F%2B8F0Ty2oLD4v1wKgm3CuiGftr11IfyB5w%3D%3D; hng=CN%7Czh-CN%7CCNY%7C156; l=dBIBcdfeq5nSzFl5BOCa-urza77ThIRvfuPzaNbMi_5Ia1T6YV7OknJtce96cjWfTG8B4HAa5Iy9-etlwrZEMnMgcGAw_xDc.; uc1=cookie15=VFC%2FuZ9ayeYq2g%3D%3D&cookie14=UoTbmEp9zNxMrw%3D%3D; isg=BDk53DNPQMq9RRxe_Fnoei4wSKUTRi34hR8HPVturmDf4ll0o5Y9yKc0YOYUrsUw', 6 'user-agent':'Mozilla/5.0'} 7 try: 8 r = requests.get(url,headers = headers,timeout = 30) 9 r.raise_for_status() 10 r.encoding = r.apparent_encoding 11 return r.text 12 except: 13 return "" 14 def parsePage(ilt,html): 15 #正则表达式获取商品名称和商品价格 16 try: 17 #使用正则表达式,\表示引入一个"view_price"的键,后面\引入键的值 18 plt = re.findall(r'\"view_price\"\:\"[\d\.]*\"',html) 19 #*?表示最小匹配 20 tlt = re.findall(r'\"raw_title\"\:\".*?\"',html) 21 for i in range(len(plt)): 22 price = eval(plt[i].split(":")[1]) 23 title = eval(tlt[i].split(":")[1]) 24 ilt.append([price,title]) 25 except: 26 print(" ") 27 def printGoodslist(ilt): 28 tplt = "{:4}\t{:8}\t{:16}" 29 print(tplt.format("序号","价格","商品名称")) 30 count = 0 31 for x in ilt: 32 count = count + 1 33 print(tplt.format(count,x[0],x[1])) 34 def main(): 35 goods = '卫衣' 36 depth = 2 37 star_url = 'https://s.taobao.com/search?q=' +goods 38 infoList = [] 39 for i in range(depth): 40 try: 41 url = star_url + '&s=' + str(44*i) 42 html = getHTMLText(url) 43 parsePage(infoList,html) 44 except: 45 continue 46 printGoodslist(infoList) 47 main()
在headers字典时,程序一直报错,报错在user-agent后面的冒号上,弄了很长时间不得解,百度也没办法
最后才想起写字典时中间的键值对没有给英文逗号,令人啼笑皆非。
最后的编译结果:
