由于学东西比较死,不够灵活,学校的acm实验室做算法题,打比赛,我是真的跟不上那些大佬...就看到人以前实验室退出的,加到 其他实验室学习项目,做项目,做项目相对学习算法来说,没有那么烧脑,还能做出有趣的东西....我就想学习做项目,因为打比赛我是拿不到能看的成绩.....我们实验室的指导老师,也挺为大家考虑的,让喜欢打比赛的暑假集训,继续刷题,学习算法,还为了,一部分人开设了项目组,进行机器学习,网络爬虫.....哈哈,学了两个月的python,正好有一些基础,正好也想学习网络爬虫,首先得感谢mooc上面的北京理工大学嵩天等老师开设的 python程序设计,和网络爬虫课程,收益良多,起码能用python做点cf的题了,还学习了爬虫。。
在爬虫课程里面,模仿到嵩天老师的爬取淘宝的商品信息,价格和名字,然后自己改了一部分,增加了存入excel表的功能,然后增加提示,增加用户体验感,虽然说还是有很多不足,但是对于小白来说,有这个程度很开心了....
爬虫难点:需要对网页里面大量的网页代码里面找需要的信息,用正则表达式提取出来,正则表达式,表示很头疼...然后就是python基础能够是否灵活的运用,还有第三方库的用法。
首先:分析网页的搜索接口,以便我们通过自己的输入爬取对应的商品
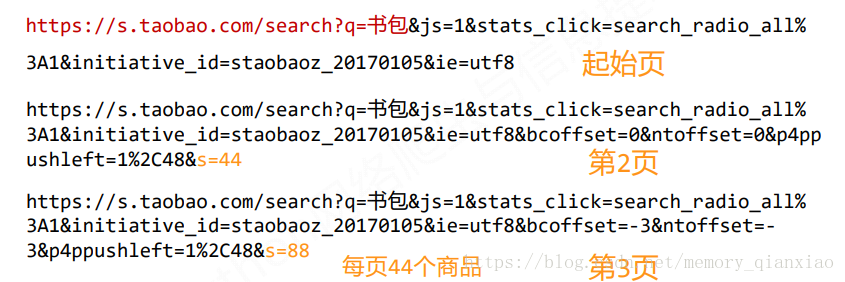
可以发现搜索接口是:
https://s.taobao.com/search?q= (后面就是自己输入的商品名称在调用这个接口)我们一般会爬取不止一页:所以需要翻页,可以有上面图片发现,每翻一页,最后的&s=()是44的倍数,所以到时候翻页的时候,就for 循环用变量自动翻页。
这里分享一下这里自己的代码:仅供互相学习。
首先看下效果吧:
由于我是打包成可运行.exe文件的就直接运行:

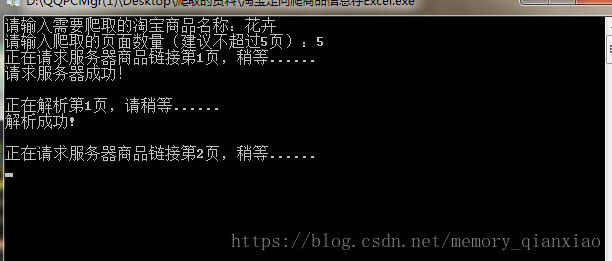

爬完后保存的是这个代码文件的位置打开后:
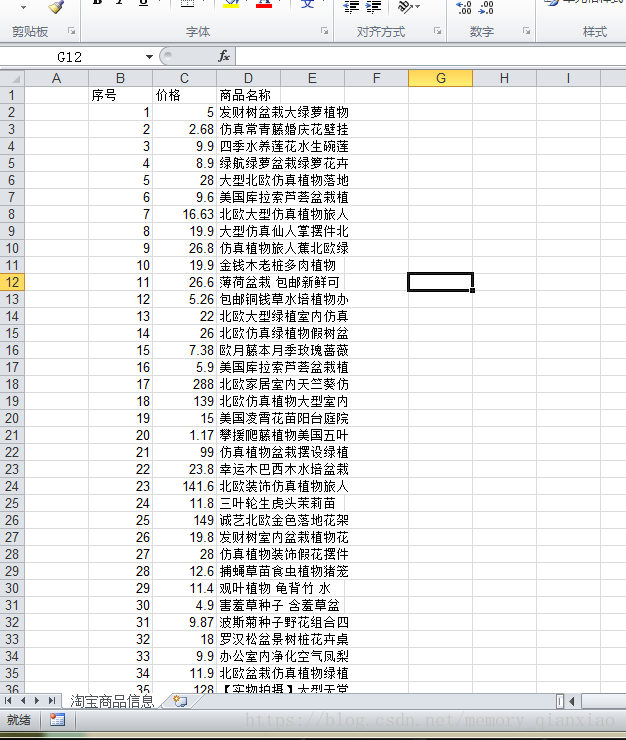
爬取成功也保存了进来了,还可以对照这淘宝上搜索一下花卉,发现都有的。说明爬取非常成功!
切忌:非法爬取数据,超大量爬取数据对服务器性能造成影响,未经本人允许,用作商业用途。
import requests,re,xlwt
#获取页面
def getHtml(url):
try:
r=requests.get(url,timeout=30)
r.raise_for_status()
r.encoding=r.apparent_encoding
print("请求服务器成功!\n")
return r.text
except:
print("请求失败")
#解析页面 正则表达式提取信息
def parsePage(ilt,html):
try:
plt=re.findall(r'\"view_price\"\:\"[\d\.]*\"',html)
tlt=re.findall(r'\"raw_title\"\:\".*?\"',html)
print("解析成功!\n")
for i in range(len(plt)):
price=eval(plt[i].split(':')[1])
title=eval(tlt[i].split(':')[1])
ilt.append([price,title])
except:
print("解析失败!\n")
#写入Excel
def Write_Excel(ilt):
print("正在写入Exel表格....")
#创建工作簿指定编码
file=xlwt.Workbook(encoding='utf-8')
#创建表
table=file.add_sheet("淘宝商品信息")
count=0
#print(tplt.format("序号","价格","商品名称"))
value=["序号","价格","商品名称"]
for i in range(len(value)):
table.write(count,i+1,value[i])
for g in ilt:
count+=1
value=[count,float(g[0]),g[1][0:10]]
for j in range(3):
table.write(count,j+1,value[j])
#Write_Excel(count,value=[g[0],g[1]],f=file)
file.save("淘宝商品信息.xls")
print("写入成功!")
#print(tplt.format(count,g[0],g[1]))
#把数据写入Excel表
def main():
goods=input("请输入需要爬取的淘宝商品名称:")
#爬取的页面深度
depth=int(input("请输入爬取的页面数量(建议不超过5页):"))
start_url="https://s.taobao.com/search?q="+goods
inforList=[]
for i in range(depth):
try:
#翻页,起始页面s,在a起始页面上进行翻页
url=start_url+'&s='+str(44*i)
print("正在请求服务器商品链接第%d页,请稍等......"%(i+1))
html=getHtml(url)
print("正在解析第%d页,请稍等......"%(i+1))
parsePage(inforList,html)
except:
continue
Write_Excel(inforList)
#printGoodsList(inforList)
main()