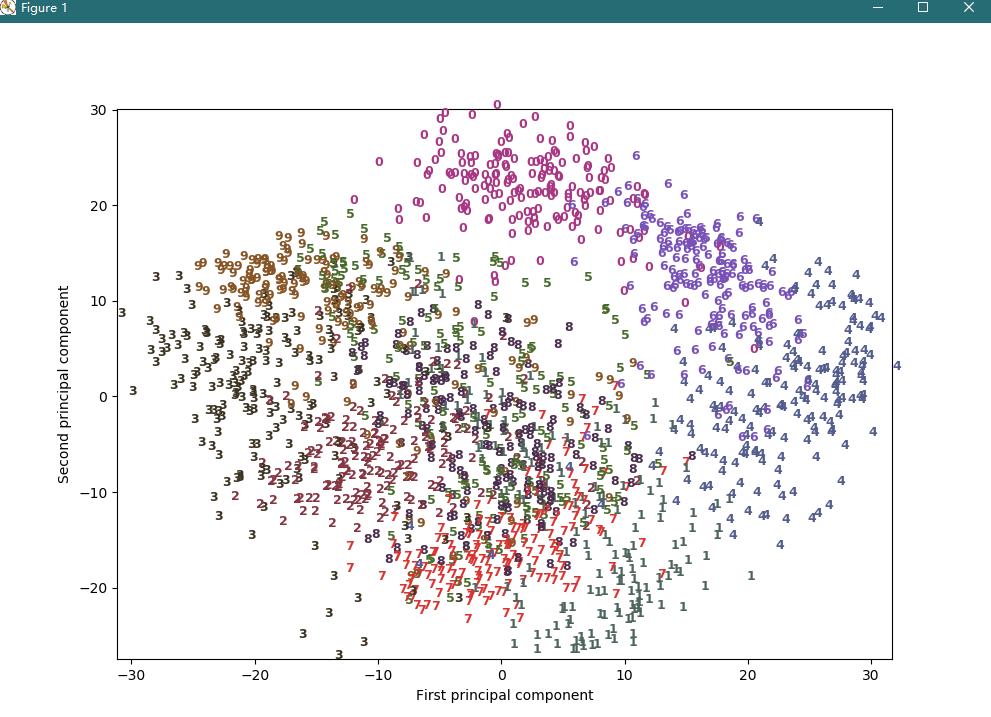
在 skilearn 的手写数据集中,每个数据点都是 0 到 9 之间手写数字的一张 8*8 灰度图像。用 PCA 将其降维到二维,并可视化数据点,如下:
1、digits 数据演示:
from sklearn.datasets import load_digits
import matplotlib.pyplot as plt
digits = load_digits() fig, axes = plt.subplots(2, 5, figsize=(10, 5), subplot_kw={'xticks': (), 'yticks': ()}) for ax, img in zip(axes.ravel(), digits.images): ax.imshow(img) plt.show()

2、将 PCA 降维到二维的数据可视化
from sklearn.datasets import load_digits
from sklearn.decomposition import PCA import matplotlib.pyplot as plt # 加载数据 digits = load_digits() # 初始化一个 PCA 模型,在数据中提取两个主成分 pca = PCA(n_components=2, random_state=27) pca.fit(digits.data) digits_pca = pca.transform(digits.data) colors = ['#A83683', '#4E655E', '#853541', '#3A3120', '#535D8E', '#476A2A', '#7851B8', '#DB3430', '#4A2D4E', '#875525'] plt.figure(figsize=(10, 10)) plt.xlim(digits_pca[:, 0].min(), digits_pca[:, 0].max()) plt.ylim(digits_pca[:, 1].min(), digits_pca[:, 1].max()) # 以数字符号显示每个类别的位置 for i in range(len(digits.data)): plt.text(digits_pca[i, 0], digits_pca[i, 1], str(digits.target[i]), color=colors[digits.target[i]], fontweight='bold', fontsize=9) plt.xlabel('First principal component') plt.ylabel('Second principal component') plt.show()
3、按语
用 PCA 提取的前两个主成分,可以很好的将 0、6、4 区分开来,但其他数字多有重叠。