- task
参考:spark partition 理解 / coalesce 与 repartition的区别 https://www.cnblogs.com/jiangxiaoxian/p/9539760.html
spark中是以vcore级别调度task的
如果读取的是hdfs,那么有多少个block,就有多少个partition
分配的task(即vcore)的数量是num-executors * executor-cores,同时运行executor数不超过spark.dynamicAllocation.maxExecutors,同时运行task数(即并行度)不超过spark.default.parallelism
这些partition依次给这些task并行处理。如果partition过多,调度时间过多;如果partition过少,有task未被利用。
coalesce(n):没有shuffle操作,用于减少partition数:并行task数不会超过n,无法实现增加partition数。
repartition(n):有shuffle操作,适合用于增加partition数:上游各个partition依次给所有待命的task处理,按某个partitioner规则写入下游n个partition。
- 资源申请参数
- 内存管理
Spark内存管理模型详解 http://www.yidooo.net/2018/07/29/spark-memory-management.html
Apache Spark 内存管理详解 https://www.ibm.com/developerworks/cn/analytics/library/ba-cn-apache-spark-memory-management/index.html
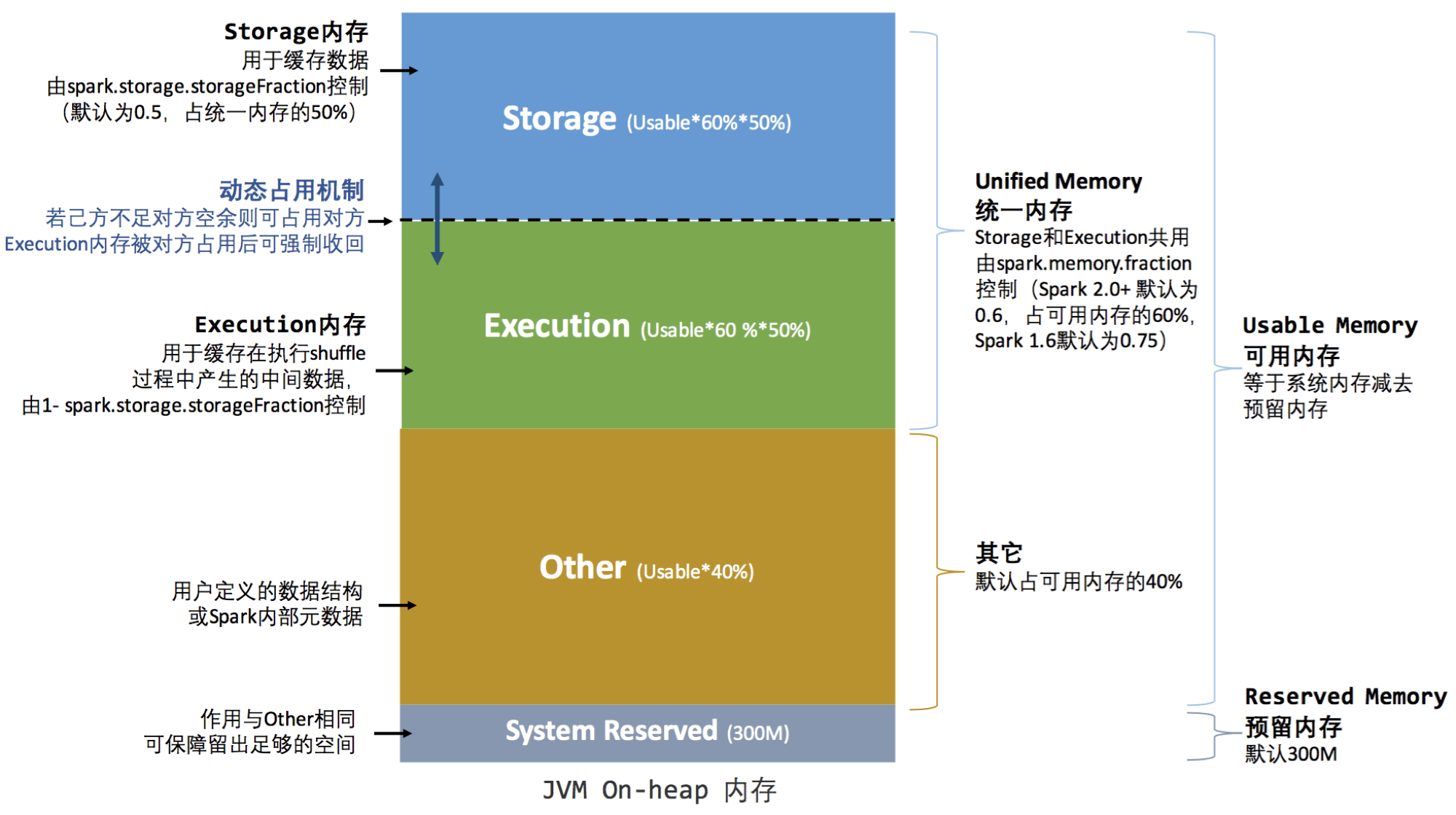
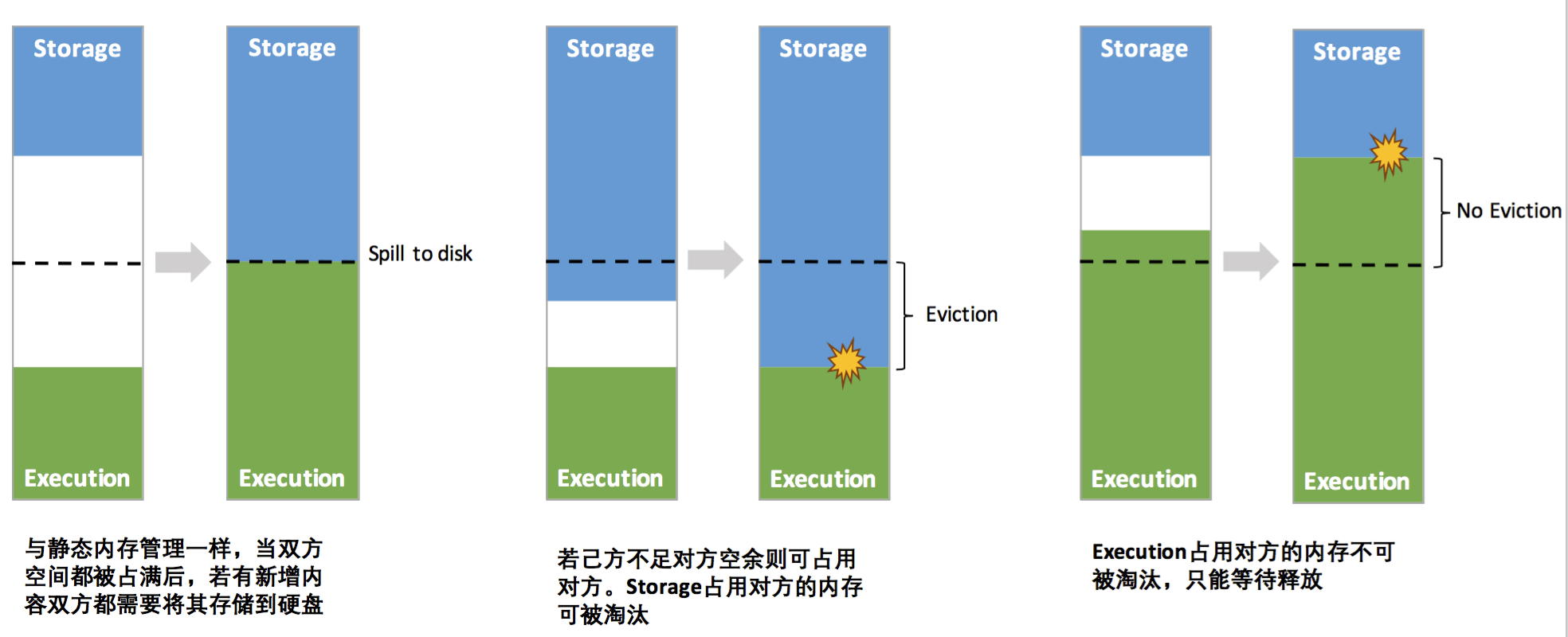
Spark 1.6 之后默认使用统一内存管理

-
-
Storage内存(Storage Memory):主要用于存储Spark的cache数据,例如RDD的缓存、Broadcast变量,Unroll数据等。Execution内存(Execution Memory):主要用于存放 Shuffle、Join、Sort、Aggregation等计算过程中的临时数据。用户内存(User Memory):主要用于存储 RDD 转换操作所需要的数据,例如 RDD 依赖等信息。预留内存(Reserved Memory):系统预留内存,会用来存储Spark内部对象。
- JVM OnHeap内存: 大小由“executor-memory”参数指定。Executor中运行的并发任务共享JVM堆内内存。
- JVM OffHeap内存:大小由“spark.yarn.executor.memoryOverhead”参数指定,主要用于JVM自身,字符串, NIO Buffer等开销。
- Yarn集群管理模式中,Spark 以Executor Container的形式在NodeManager中运行,其可使用的内存上限由“yarn.scheduler.maximum-allocation-mb” 指定
-
- 常见问题
Spark常见问题 http://www.yidooo.net/2019/04/21/spark-troubleshooting-guide.html
Spark面对OOM问题的解决方法及优化总结 https://blog.csdn.net/yhb315279058/article/details/51035631
Spark处理百亿规模数据优化实战 https://blog.csdn.net/aijiudu/article/details/75206590