我遇到下面的问题:给定一批ID,大约几万个,然后去日志里面把包含他们的记录捞出来。我们很自然想到的解决方法是:把这些ID写入一个文件,spark任务先读出这个文件的内容,然后再把内容广播到每个工作节点。这样做的话,我们又有两个选择,一是把ID写入一个HDFS文件,spark任务读出并广播,然而这种做法需要把HDFS文件的路径写死在代码里,万一不小心删除或者移动了文件,spark任务就会失败,另外这种把代码和资源分开的做法在有些场景下是不可行的。所以我们可以考虑另外一种选择,把ID写入资源文件,并打入jar包,spark任务首先从jar包中解析资源内容,然后广播。
下面假设你已经创建好资源并放在下面目录
src/main/resources
第一步。首先配置maven的资源选项,比如
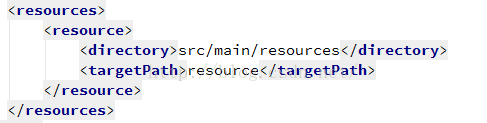
这样一来我们分别制定了资源所在的位置和打包后的位置
第二步,在程序里读出该资源并广播:
val source = Source.fromURL(this.getClass.getClassLoader.getResource("resource/your.data"))
val adgroupId = source.getLines().toArray.filter(item=>item.trim.length>0).map(item=>item.split(",")(0).toLong).toSet
val adgroupId_b = sc.broadcast(adgroupId)