说明:单机版的Spark的机器上只需要安装JDK即可,其他诸如Hadoop、Zookeeper(甚至是scala)之类的东西可以一概不安装。
集群版搭建:Spark2.2集群部署和配置
一、安装JDK1.8
1、下载JDK1.8,地址
2、将下载的文件保存在 /home/qq/java下,进行解压,解压后文件夹为 jdk1.8.0_171:
tar -zxvf jdk-8u171-linux-i586.tar.gz
3、配置JDK环境,输入命令:
sudo vim ~/.bashrc
在文件末尾加入:
export JAVA_HOME=/home/qq/java/jdk1.8.0_171
export JRE_HOME=${JAVA_HOME}/jre
export CLASSPATH=.:${JAVA_HOME}/lib:${JRE_HOME}/lib
export PATH=${JAVA_HOME}/bin:$PATH
使用命令:wq保存退出,执行命令生效:
source ~/.bashrc
4、测试JDK
输入命令:
java -version
输出:
java version "1.8.0_171"
Java(TM) SE Runtime Environment (build 1.8.0_171-b11)
Java HotSpot(TM) Client VM (build 25.171-b11, mixed mode)
JDK安装成功。
二、安装spark2.2.0
1、使用命令
wget https://d3kbcqa49mib13.cloudfront.net/spark-2.2.0-bin-hadoop2.7.tgz

下载文件,并将其放在 /home/qq/spark 文件夹下。
或者先下载再传入ubuntu
2、解压,改名(之前名字太长,改成spark-2.2.0)
tar -zxvf spark-2.4.0-bin-hadoop2.7.tgz
mv spark-2.4.0-bin-hadoop2.7 spark-2.4.0
3、配置环境,打开文件sudo vi /etc/profile,在末尾加入:
export SPARK_HOME=/home/qq/spark/spark-2.4.0
export PATH=$PATH:$SPARK_HOME/bin
输入:
source /etc/profile
使环境变量生效。
4、配置spark环境
打开文件夹spark-2.4.0,首先我们把缓存的文件spark-env.sh.template改为spark识别的文件spark-env.sh:
cp conf/spark-env.sh.template conf /spark-env.sh
打开修改spark-env.sh文件,
vi conf/spark-env.sh
在末尾加入:
export JAVA_HOME=/home/qq/java/jdk1.8.0_171
export SPARK_MASTER_IP=SparkMaster
export SPARK_WORKER_MEMORY=2g
export SPARK_WORKER_CORES=2
export SPARK_WORKER_INSTANCES=1
变量说明
JAVA_HOME:Java安装目录
SPARK_MASTER_IP:spark集群的Master节点的ip地址
SPARK_WORKER_MEMORY:每个worker节点能够最大分配给exectors的内存大小
SPARK_WORKER_CORES:每个worker节点所占有的CPU核数目
SPARK_WORKER_INSTANCES:每台机器上开启的worker节点的数目
其次,修改slaves文件,
cp slaves.template slaves
vi conf/slaves
加入:
localhost
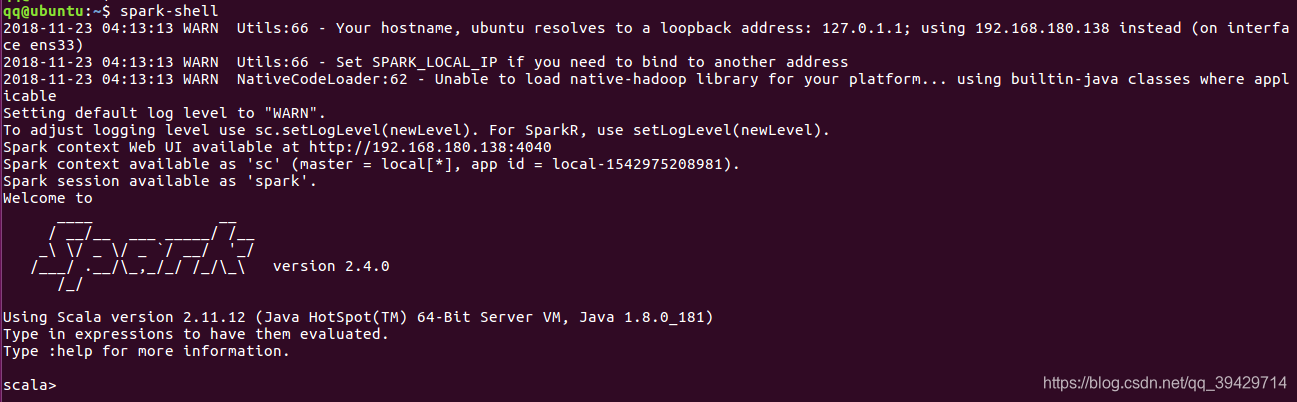
5、运行spark
spark-shell
如图:
至此,安装全部完成。
测试
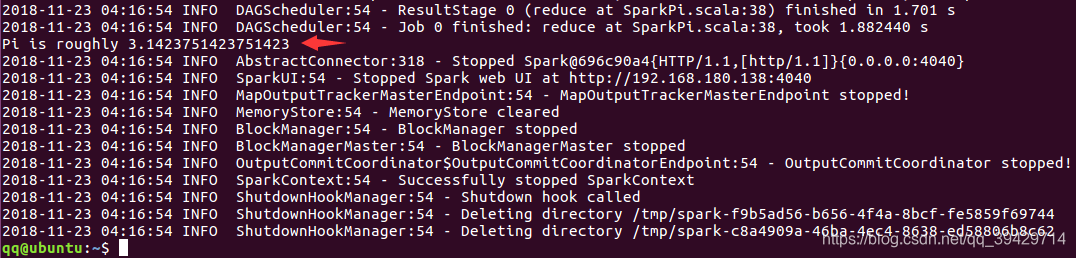
跑PI
$ run-example SparkPi 10
结果如图: