背景
在Hadoop 2.0.0之前,NameNode是HDFS集群中的单点故障(SPOF)。每个群集只有一个NameNode,并且如果该计算机或进程不可用,则整个群集将不可用,直到NameNode重新启动或在单独的计算机上启动。
这从两个方面影响了HDFS群集的总可用性:
- 如果发生意外事件(例如机器崩溃),则在操作员重新启动NameNode之前,群集将不可用。
- 计划内的维护事件,例如NameNode计算机上的软件或硬件升级,将导致群集停机时间的延长。
HDFS高可用性功能通过提供在带有热备用的主动/被动配置中在同一群集中运行两个冗余NameNode的选项来解决上述问题。这可以在计算机崩溃的情况下快速故障转移到新的NameNode,或出于计划维护的目的由管理员发起的正常故障转移。
1、修改hadoop配置文件
master slave1建立免密钥(后续以这两台机器作为namdnode)
修改配置文件,hdfs-site.xml :
<configuration>
<property>
<name>dfs.replication</name>
<value>2</value>
</property>
<property>
<name>dfs.nameservices</name> (新服务的逻辑名称)
<value>mycluster</value>
</property>
<property>
<name>dfs.ha.namenodes.mycluster</name> (各NameNode ID)
<value>nn1,nn2</value>
</property>
<property>
<name>dfs.namenode.rpc-address.mycluster.nn1</name> (NameNode具体IP和端口号)
<value>master:8020</value>
</property>
<property>
<name>dfs.namenode.rpc-address.mycluster.nn2</name>
<value>slave1:8020</value>
</property>
<property>
<name>dfs.namenode.http-address.mycluster.nn1</name> (NameNode HTTP服务器设置地址)
<value>master:50070</value>
</property>
<property>
<name>dfs.namenode.http-address.mycluster.nn2</name>
<value>slave1:50070</value>
</property>
<property>
<name>dfs.namenode.shared.edits.dir</name> (配置JournalNode)
<value>qjournal://master:8485;slave1:8485;slave2:8485/mycluster</value>
</property>
<property>
<name>dfs.client.failover.proxy.provider.mycluster</name> (DFS客户端将使用该Java类来确定哪个NameNode是当前的Active,从而确定哪个NameNode当前正在服务于客户端请求。Hadoop当前随附的唯一实现是ConfiguredFailoverProxyProvider,因此请使用此实现)
<value>org.apache.hadoop.hdfs.server.namenode.ha.ConfiguredFailoverProxyProvider</value>
</property>
<property>
<name>dfs.ha.fencing.methods</name> (sshfence选项SSHes到目标节点,然后通过定影杀该服务的TCP端口上侦听的过程。为了使该防护选项起作用,它必须能够在不提供密码的情况下SSH到目标节点)
<value>sshfence</value>
</property>
<property>
<name>dfs.ha.fencing.ssh.private-key-files</name>
<value>/root/.ssh/id_rsa</value>
</property>
<property>
<name>dfs.ha.automatic-failover.enabled</name> (自动故障转移需要配置的参数)
<value>true</value>
</property>
</configuration>
core-site.xml :
<configuration>
<property>
<name>fs.defaultFS</name>
<value>hdfs://mycluster</value>
</property>
<property>
<name>hadoop.tmp.dir</name> (设置HA文件目录)
<value>/usr/local/src/hadoop-2.6.5/HA</value>
</property>
<property>
<name>ha.zookeeper.quorum</name> (指定应为自动故障转移设置群集)
<value>slave1:2181,slave2:2181,slave3:2181</value>
</property>
</configuration>
分发到其他3个节点
scp core-site.xml hdfs-site.xml slave1:/usr/local/src/hadoop-2.6.5/etc/hadoop
2、给slave1,slave2,slave3安装zookeeper
解压安装:tar -zxvf zookeeper-3.4.6.tar.gz
将conf下的zoo_sample.cfg改名为zoo.cfg
配置文件夹:dataDir=/usr/local/src/zookeeper-3.4.6/data
server.1=slave1:2888:3888
server.2=slave2:2888:3888
server.3=slave3:2888:3888
分发到其他2个节点
scp -r zookeeper-3.4.6/ slave2:'pwd'
分别增加zookeeper编号123
mkdir -p / /usr/local/src/zookeeper-3.4.6/data
echo 1 > /usr/local/src/zookeeper-3.4.6/data/myid
分别配置环境变量:
export ZOOKEEPER_HOME=/usr/local/src/zookeeper-3.4.6
export PATH=$PATH:$ZOOKEEPER_HOME/bin
zkServer.sh start启动3台zookeeper
jps查看:
6267 Jps
6204 QuorumPeerMain
分别启动JournalNode :hadoop-daemon.sh start journalnode
同步2个NameNode数据:
master: hdfs namenode -format
hadoop-daemon.sh start namenode (启动主节点)
slave1: hdfs namenode -bootstrapStandby
在主节点初始化zookeeper:hdfs zkfc -formatZK
可在zookeeper客户端查看:zkCli.sh
下面开始启动集群
start-dfs.sh
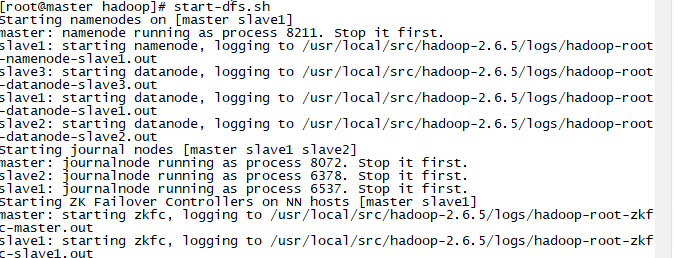
jps查看:
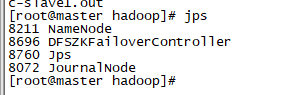
至此集群搭建启动完成
检验集群
首先打开浏览器查看:
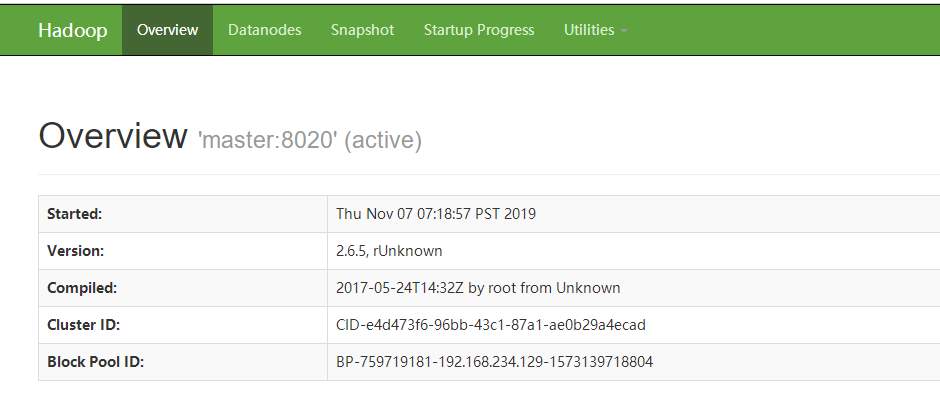
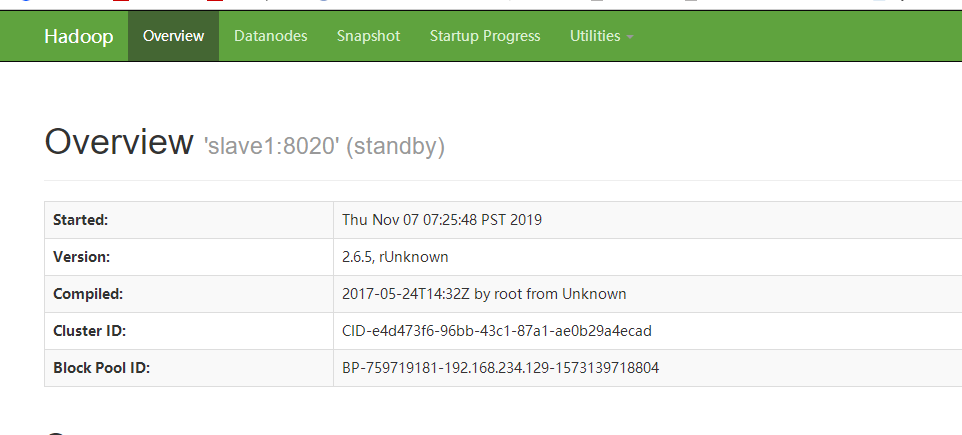
实验关闭master的NameNode:
hadoop-daemon.sh stop namenode
查看浏览器上显示的状态active和standby发生转变,已经实现自动故障转移
注意:需要关闭防火墙。
service iptables stop
永久关闭修改配置开机不启动防火墙:
chkconfig iptables off