题目链接:http://poj.org/problem?id=2406
Given two strings a and b we define a*b to be their concatenation. For example, if a = "abc" and b = "def" then a*b = "abcdef". If we think of concatenation as multiplication, exponentiation by a non-negative integer is defined in the normal way: a^0 = "" (the empty string) and a^(n+1) = a*(a^n).
Input
Each test case is a line of input representing s, a string of printable characters. The length of s will be at least 1 and will not exceed 1 million characters. A line containing a period follows the last test case.
Output
For each s you should print the largest n such that s = a^n for some string a.
Sample Input
abcd aaaa ababab .
Sample Output
1 4 3
Hint
This problem has huge input, use scanf instead of cin to avoid time limit exceed.
题目意思:在每个字符串中求该字符串最多由多少个相同的字符串首尾连接组成。
题目思路:
KMP中next数组的巧妙运用。在这里我们假设这个字符串的长度是len,那么如果len可以被len-next[len]整除的话,我们就可以说len-next[len]就是那个最短子串的长度。为什么呢? 假设我们有一个字符串ababab,那么next[6]=4对吧,由于next的性质是,匹配失败后,下一个能继续进行匹配的位置,也就是说,把字符串的前四个字母,abab,平移2个单位,这个abab一定与原串的abab重合(否则就不满足失败函数的性质),这说明了什么呢,由于字符串进行了整体平移,而平移后又要重叠,那么必有s[1]=s[3],s[2]=s[4],s[3]=s[5],s[4]=s[6].说明长度为2的字符串在原串中一定重复出现,这就是len-next[len]的含义!
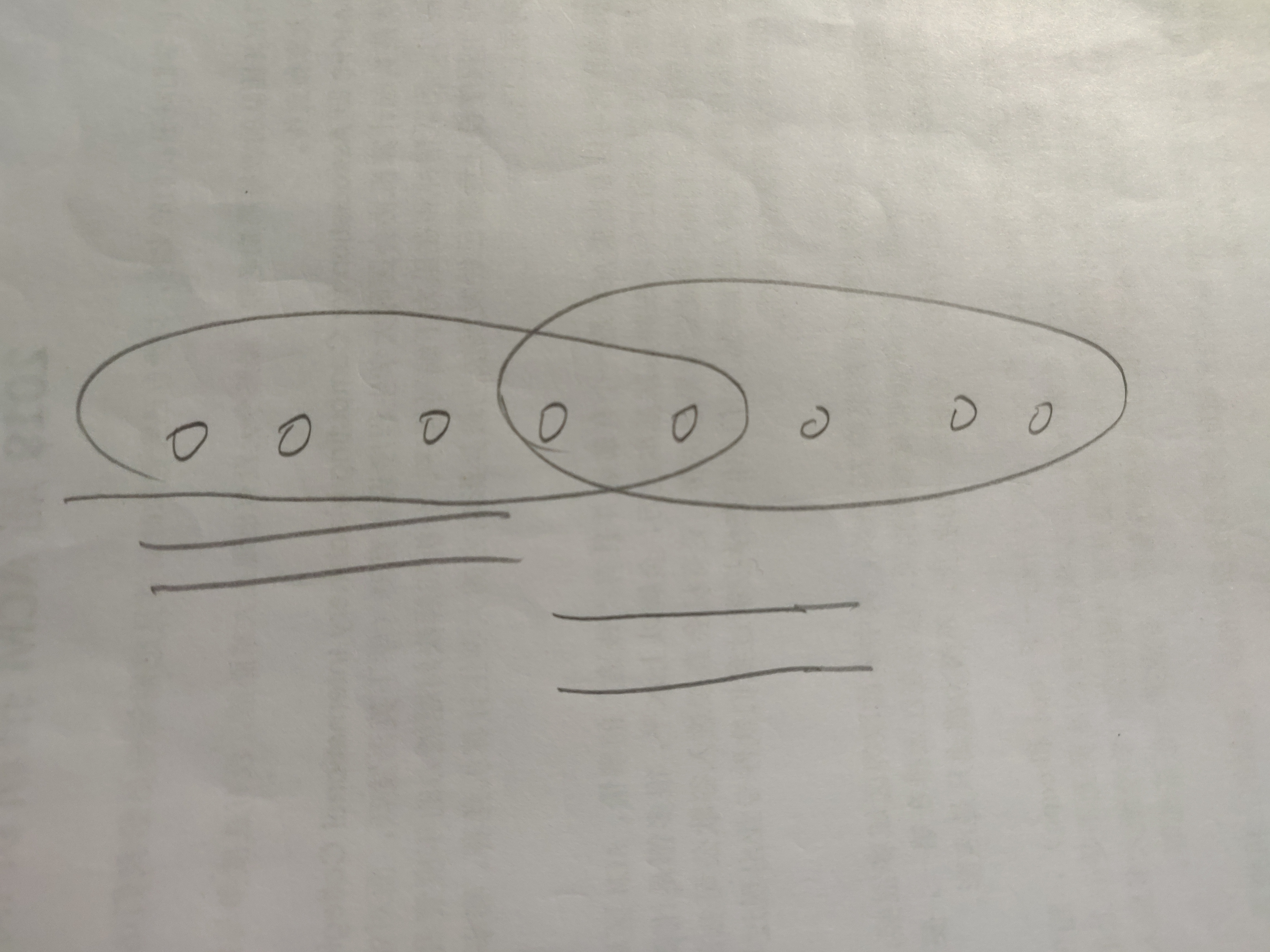
也可以这么认为(上面懂了可以不看):根据next数组的来历,我们可以知道next[len]是从0到len-1中的最大相同前缀后缀,如下图,我们可以看到圈住的部分就是最大相同的前缀后缀。则我们可以肯定len-next[len](划双横线部分)是重复出现的最短子串。
#include<stdio.h>
#include<string.h>
using namespace std;
const int maxn=1e7+10;
char str[maxn];
int next[maxn];
void GetNext(char *p)
{
int plen=strlen(p);
next[0]=-1;
int k=-1;
int j=0;
while(j<plen)
{
if(k==-1||p[j]==p[k])
{
++k;
++j;
next[j]=k;
}
else k=next[k];
}
}
int main()
{
while(scanf("%s",str)!=EOF)
{
if(str[0]=='.')return 0;
GetNext(str);
int ans=1;
int len=strlen(str);
if(len%(len-next[len])==0)ans=len/(len-next[len]);
printf("%d\n",ans);
}
return 0;
}