1.概率分布
由于前面学习的是回归,因此我们通过回归的方法来查看概率分布
分类是class 1 的时候结果是1
分类为class 2的时候结果是-1;
测试时,如果结果接近1的是class1 ,如果结果接近-1的是class2。

但是呢,这只是看起来很美丽,但是如果当结果远远大于1的时候,他的分类应该是class1还是class2呢? 我们为了降低整体误差,需要调整已经找到的分类函数,这样会导致实际结果的不准确。

因此对于概率分布的类型题目我们不能使用回归的方法去解决。
依旧遵循机器学习的三步走:
1.设计一个model
我们根据李宏毅老师的视频使用二分类为例:

2.loss function (损失函数)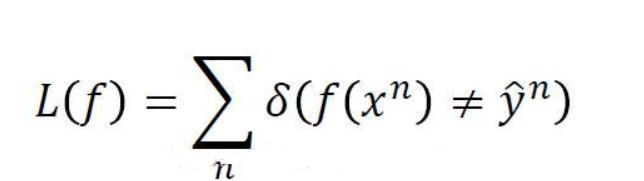
3.找到最好的函数
使用(perceptorn,SVM)两种方法。
2.概率生成模型
根据李宏毅老师的视频中我们设计了两个盒子box1和box2 假设我们重盒子里面拿出来的蓝球为p(b1) = 2/3 , 则绿球的概率p(b2) = 1/3 假设p(b1|x)>0.5说明x属于box1;反之则属于box2。

因此盒子来自box1的概率为:
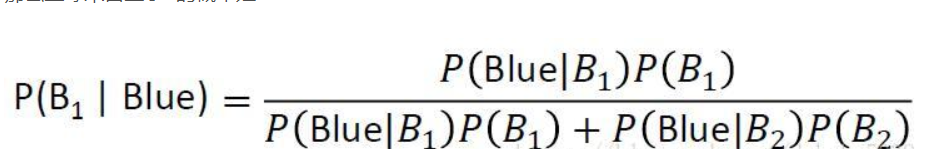
其中这里面涉及有关数论的知识,由于本身没有学过,所以里面有些内容不是很理解。
我们假设这种概率分布模型是高斯分布(因为是最常见的分布类型),根据概率论中的中心极限定理告诉我们答案,所以我们选择的高斯分布。
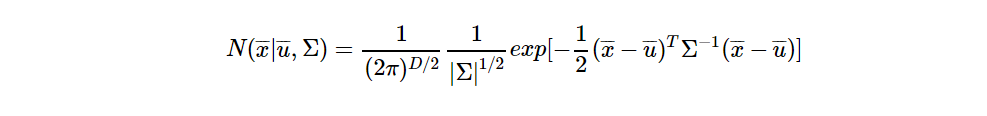
相关理解可以查阅网站:
其中均值为μ,协方差为∑(用来表示一组数据的波动大小的)
根据李宏毅老师的视频中我们假设有79组宝可梦数据,因此:
我们计算得出μ和∑的值
3.解决分类问题
(李宏毅老师的例子)
开始我们的分类问题:
我们要进行二分类,分别是水系的怪物精灵和一般的怪物精灵,我们计算得到他们的高斯分布分别为

我们就可以用第一部分的概率分布公式计算x的分类了,水系p(C1),非水系p(C2)分别在数据中就可以简单计算,p(x∣C1),p(x∣C2)由它们概率密度函数推导求解得到(积分)。
如果P(C1|x)>0.5,说明x属于水系。
但是得到的结果的正确率只有54%。
分析一下原因,是由于两类额协方差导致参数过多,那我们让协方差共享∑\sum∑,减少协方差的种类。

这样正确率就达到了73%
本图片,公式均引用自李宏毅老师的机器学习。
以上是我对李宏毅老师视频学习的笔记记录。